
作業環境
- R version: 4.4.2 (2024-10-31)
- RStudio version: 2024.12.1+563
- Platform: aarch64-apple-darwin20
- Running under: macOS 15.4 (24E247)
アンケート概要
- アンケート実施日:2025年4月9日
- アンケート実施方法:Googleフォーム
- アンケート対象者:RとQuartoではじめるデータサイエンス(2025)受講生
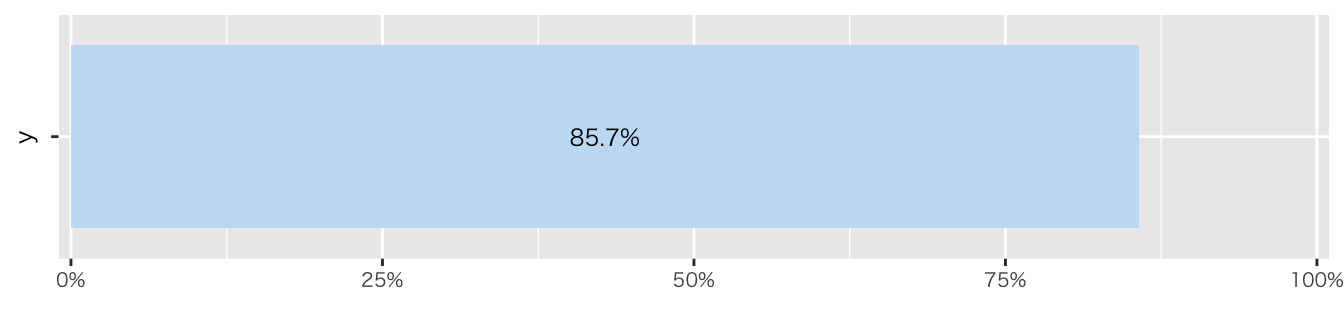
- アンケート回収率:
Code
df_初回アンケート |>
summarise(
回答者数 = n(),
.groups="drop"
) |>
mutate(登録者数 = 7) |>
mutate(
回答率 = scales::percent(回答者数/登録者数, accuracy = 0.1)) |>
mutate(回答率 = as.numeric(gsub("%", "", 回答率))) |>
ggplot(aes(x = 回答率, y = "")) +
geom_bar(stat = "identity", fill = "#C5DFF4FF") +
geom_text(aes(label = paste0(回答率, "%")),
position = position_stack(vjust = 0.5, reverse = TRUE)) +
scale_x_continuous(
limits = c(0, 100),
expand = expansion(mult = c(0.01, 0.01)),
labels = scales::percent_format(scale = 1)) +
labs(
x = ""
) 
図
同種の図はまとめて処理(個別function + map関数)
属性
Code
df_初回アンケート |>
group_by(学域) |>
summarise(
人数 = n()
) |>
mutate(
比率 = 人数/sum(人数)
) |>
ungroup() |>
ggplot(aes(x = "", y = 人数, group = 学域)) +
geom_col(
aes(color = 学域, fill = after_scale(alpha(color, 0.9))),
position = position_fill(),
) +
geom_text(
aes(label = str_c(scales::percent(比率, accuracy = 0.1), "(", 人数, "人)")),
position = position_fill(reverse = FALSE, vjust = 0.5),
) +
scale_y_continuous(
expand = expansion(mult = c(0.01, 0.01)),
labels = scales::label_percent()) +
labs(
x = "",
y = "",
color = "学域"
) +
coord_flip() +
scale_color_paletteer_d("DresdenColor::briefcases") #配色変更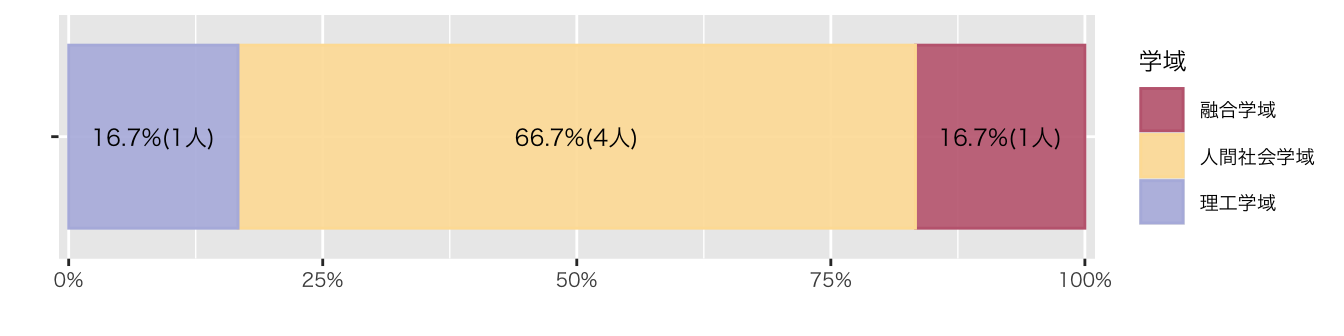
Code
df_初回アンケート |>
group_by(学年) |>
summarise(
人数 = n()
) |>
mutate(
比率 = 人数/sum(人数)
) |>
ungroup() |>
ggplot(aes(x = "", y = 人数, group = 学年)) +
geom_col(
aes(color = 学年, fill = after_scale(alpha(color, 0.9))),
position = position_fill(),
) +
geom_text(
aes(label = str_c(scales::percent(比率, accuracy = 0.1), "(", 人数, "人)")),
position = position_fill(reverse = FALSE, vjust = 0.5),
) +
scale_y_continuous(
expand = expansion(mult = c(0.01, 0.01)),
labels = scales::label_percent()) +
labs(
x = "",
y = "",
color = "年次"
) +
coord_flip() +
scale_color_paletteer_d("PrettyCols::Fun")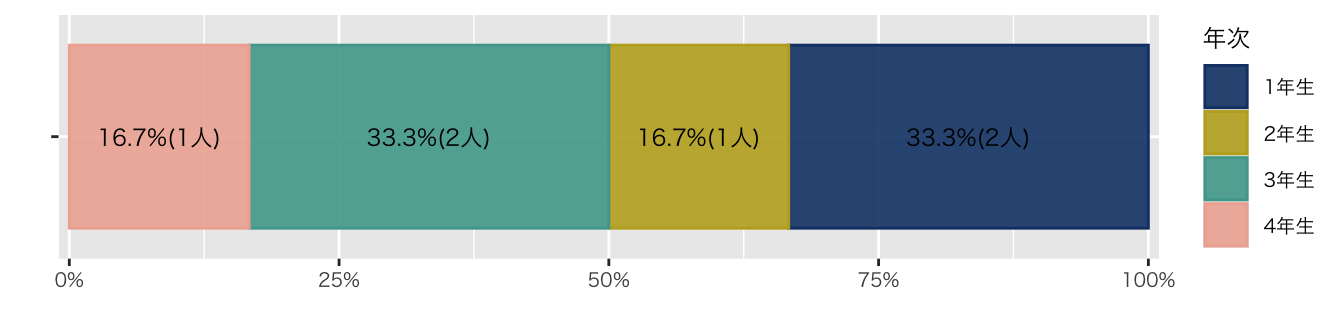
単純集計
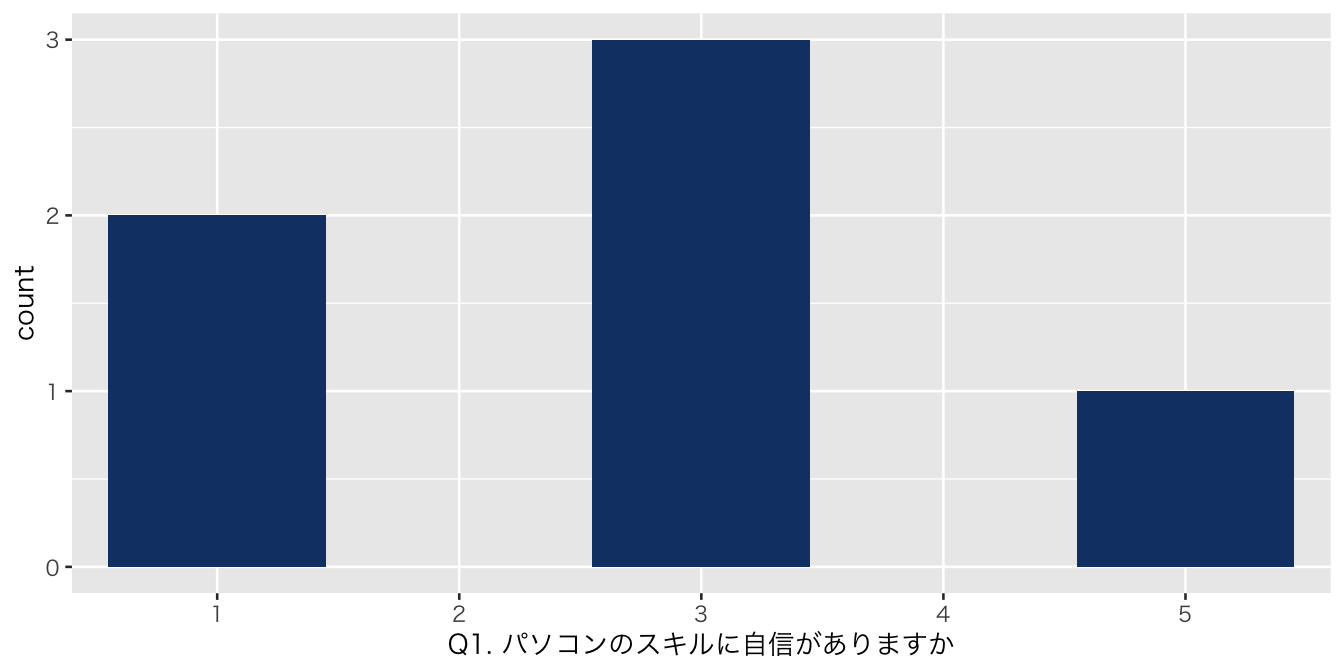
棒グラフ
Code
data_list <- list(
`Q1. パソコンのスキルに自信がありますか` = df_初回アンケート %>% select(`Q1. パソコンのスキルに自信がありますか`),
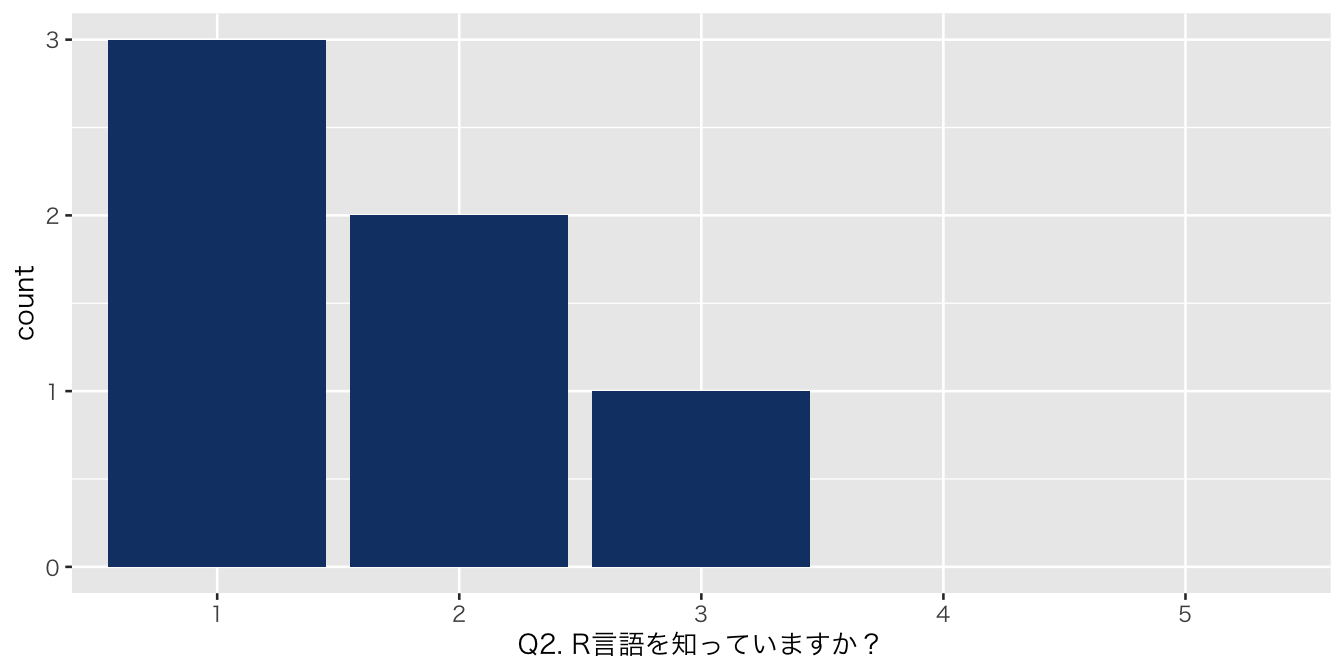
`Q2. R言語を知っていますか?` = df_初回アンケート %>% select(`Q2. R言語を知っていますか?`),
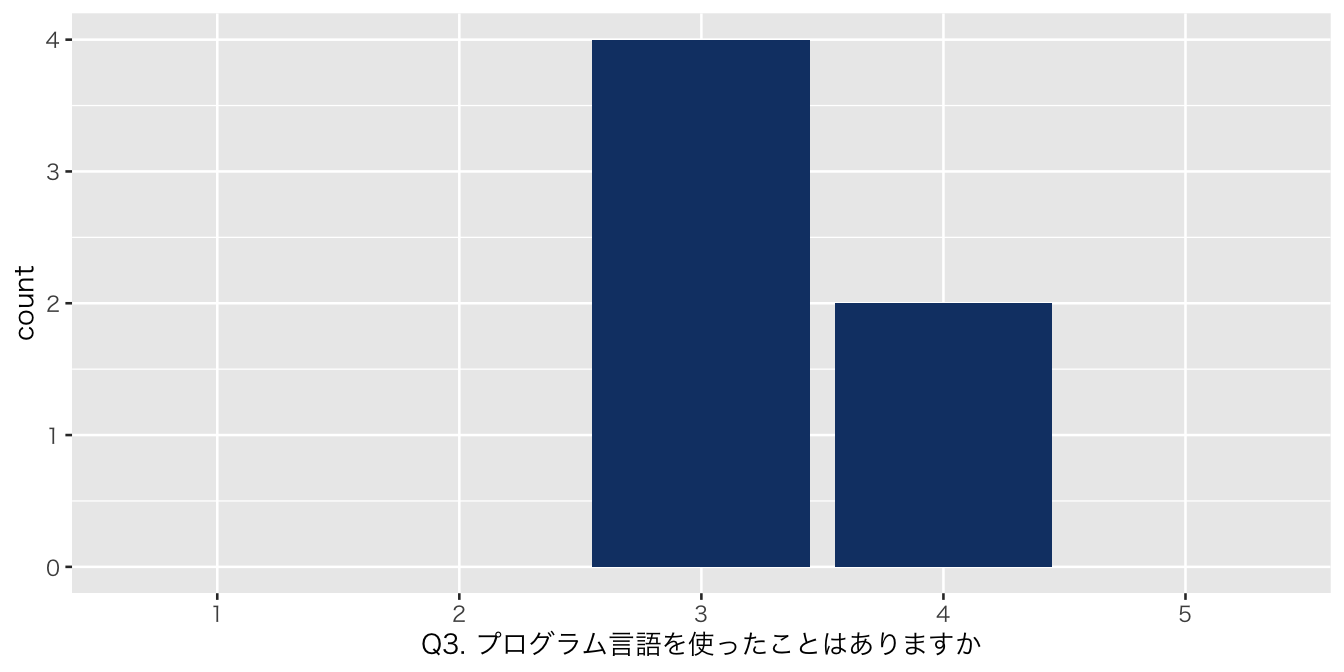
`Q3. プログラム言語を使ったことはありますか` = df_初回アンケート %>% select(`Q3. プログラム言語を使ったことはありますか`)
)
# 質問票の回答選択肢を1から5に設定
levels <- factor(1:5)
# 関数の引数名を df に変更
create_bar_plot <- function(df) {
question <- names(df)[1]
df[[question]] <- factor(df[[question]], levels = 1:5, labels = levels)
ggplot(df, aes(x = .data[[question]])) +
geom_bar(fill = "#134074FF") +
scale_x_discrete(drop = FALSE) + # データがなくてもx軸に表示
theme_gray(base_size = 10, base_family = "HiraginoSans-W3")
}
# 各質問に対して棒グラフを作成
plots <- map(data_list, create_bar_plot)
# すべてのプロットを表示
for (plot in plots) {
print(plot)
}
Code
data_list <- list(
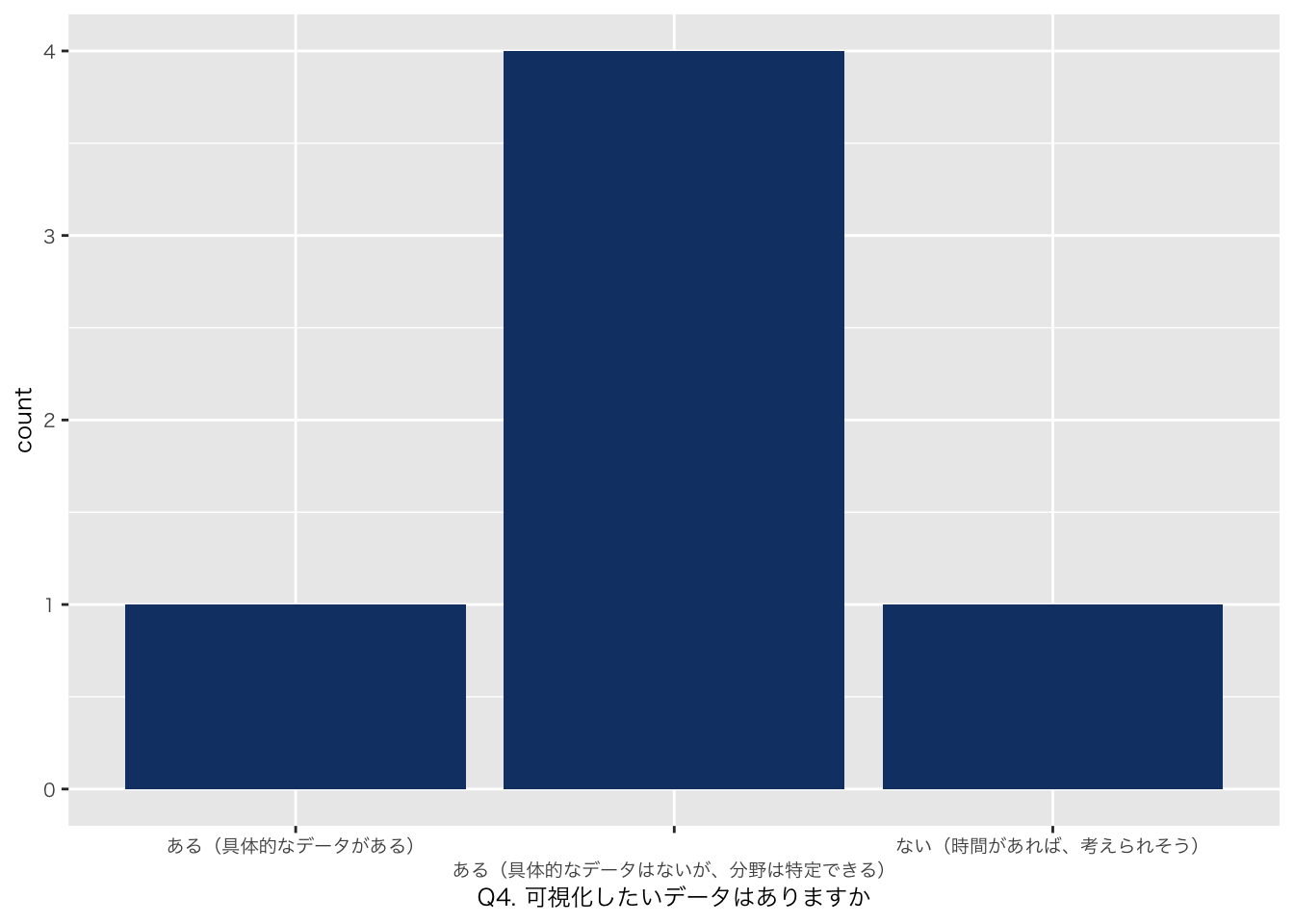
`Q4. 可視化したいデータはありますか` = df_初回アンケート %>% select(`Q4. 可視化したいデータはありますか`),
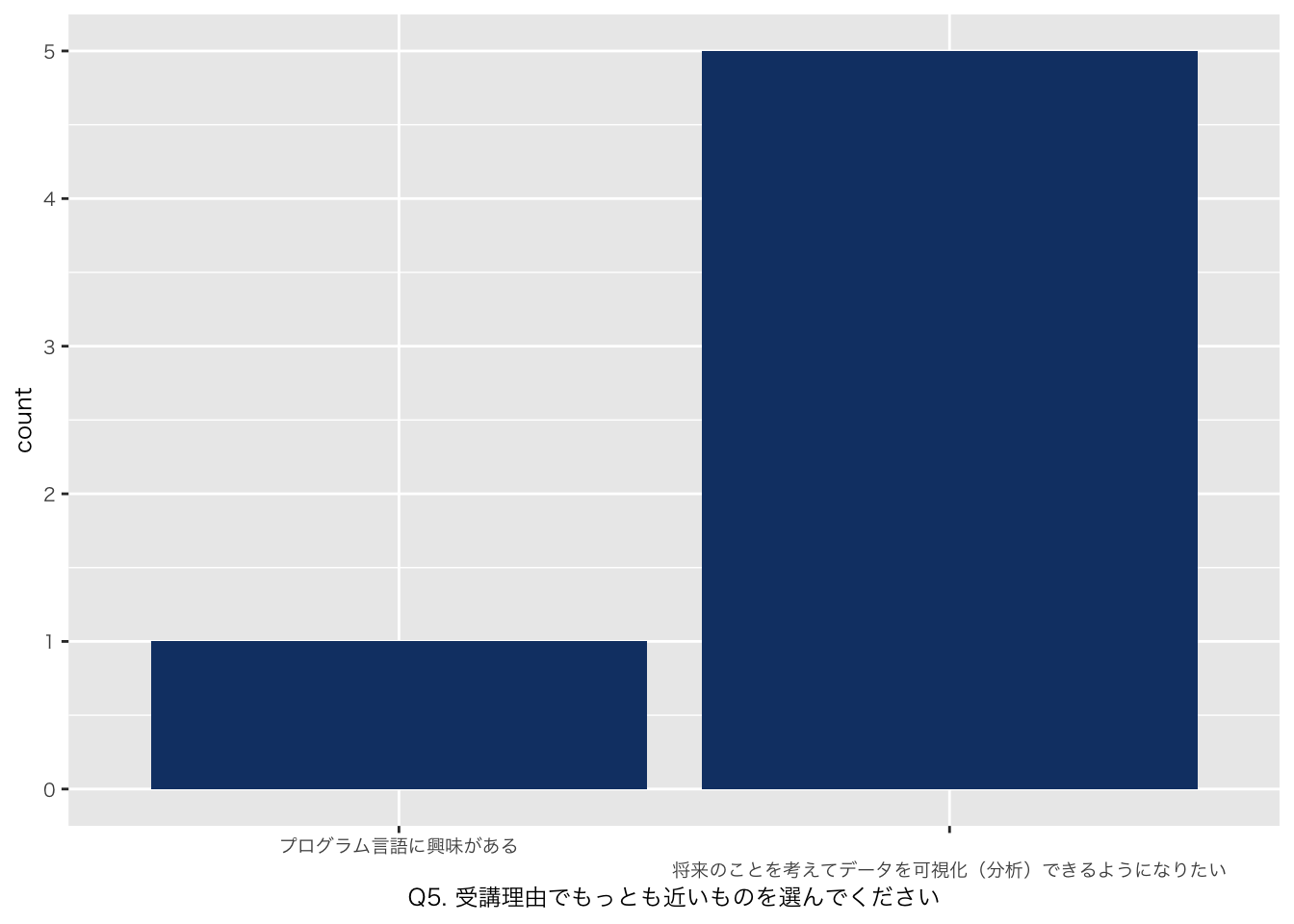
`Q5. 受講理由でもっとも近いものを選んでください` = df_初回アンケート %>% select(`Q5. 受講理由でもっとも近いものを選んでください`)
)
create_bar_plot <- function(df) {
question <- names(df)[1]
ggplot(df, aes(x = .data[[question]])) +
geom_bar(fill = "#134074FF") +
scale_x_discrete(drop = FALSE) + # データがなくてもx軸に表示
scale_x_discrete(guide = guide_axis(n.dodge = 2)) +
theme(base_size = 10, base_family = "HiraginoSans-W3")}
# theme(axis.text.x = element_text(angle = 45, hjust = 1),
# base_size = 10, base_family = "HiraginoSans-W3")}
# 各質問に対して棒グラフを作成
plots <- map(data_list, create_bar_plot)
# すべてのプロットを表示
for (plot in plots) {
print(plot)
}
Code
data_list <- list(
`Q6. Microsoft Excelを使ったことはありますか` = df_初回アンケート %>% select(`Q6. Microsoft Excelを使ったことはありますか`),
`Q7. SPSSを使ったことはありますか` = df_初回アンケート %>% select(`Q7. SPSSを使ったことはありますか`),
`Q8. Stataを使ったことはありますか` = df_初回アンケート %>% select(`Q8. Stataを使ったことはありますか`),
`Q9. SASを使ったことはありますか` = df_初回アンケート %>% select(`Q9. SASを使ったことはありますか`),
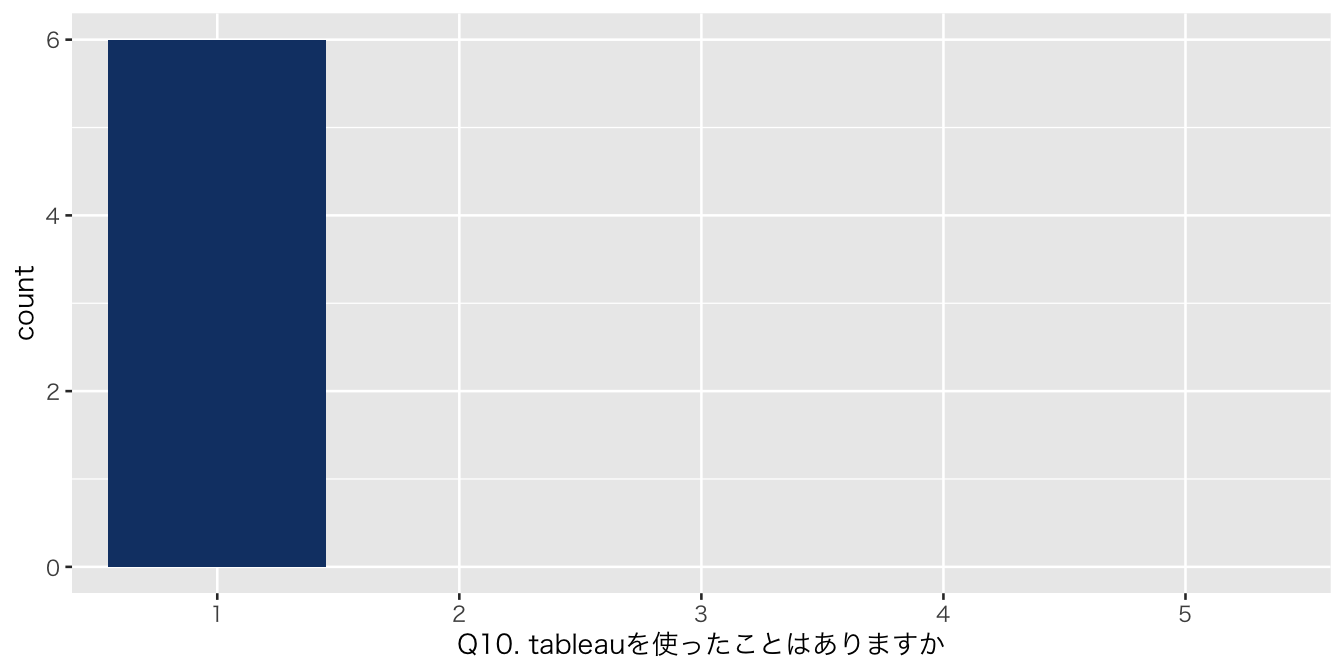
`Q10. tableauを使ったことはありますか` = df_初回アンケート %>% select(`Q10. tableauを使ったことはありますか`),
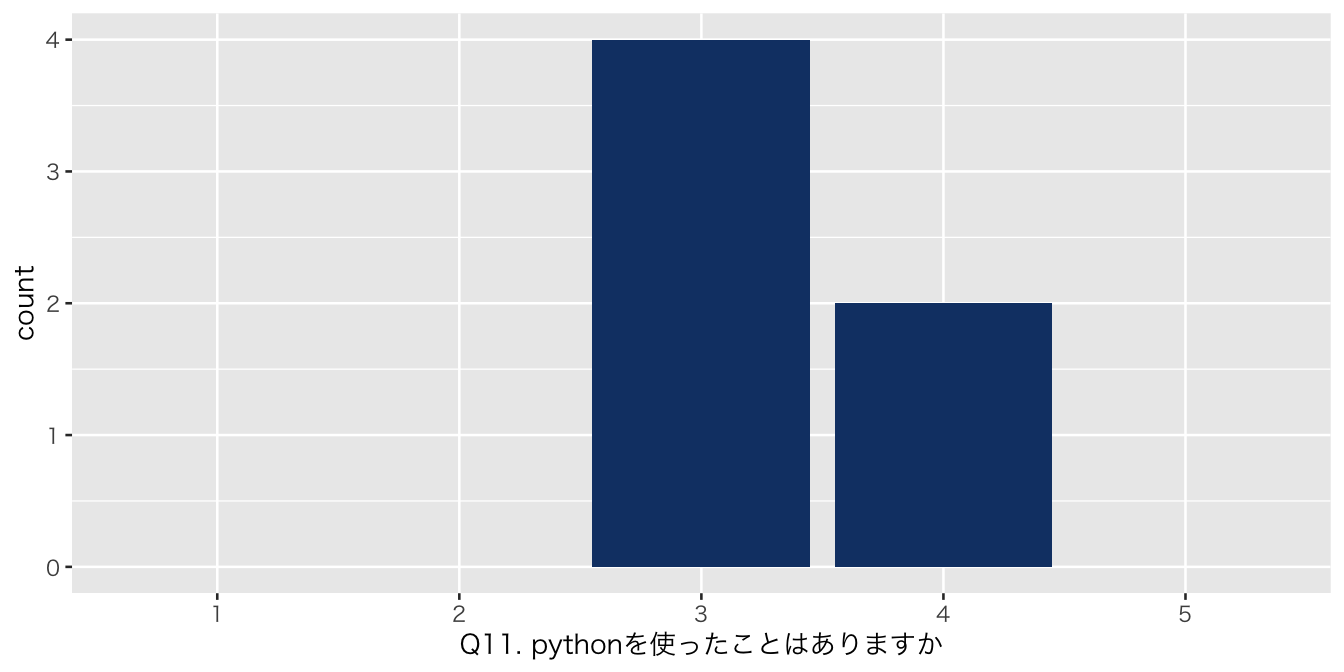
`Q11. pythonを使ったことはありますか` = df_初回アンケート %>% select(`Q11. pythonを使ったことはありますか`),
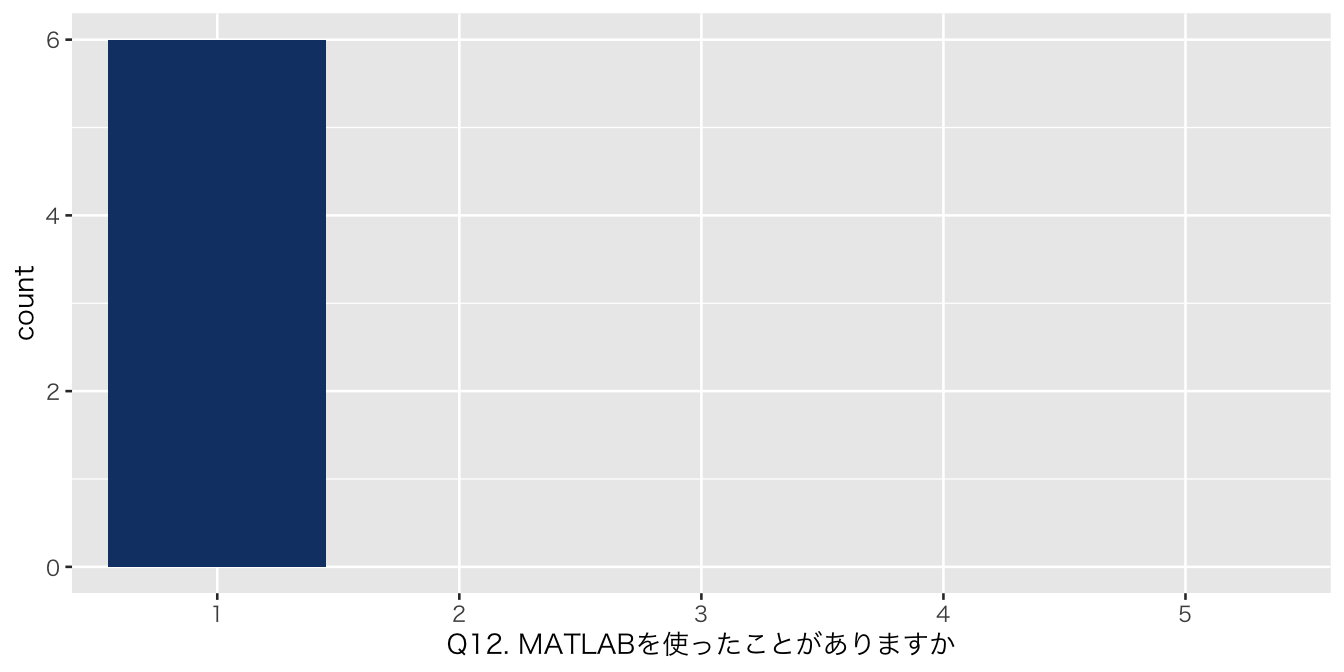
`Q12. MATLABを使ったことがありますか` = df_初回アンケート %>% select(`Q12. MATLABを使ったことがありますか`),
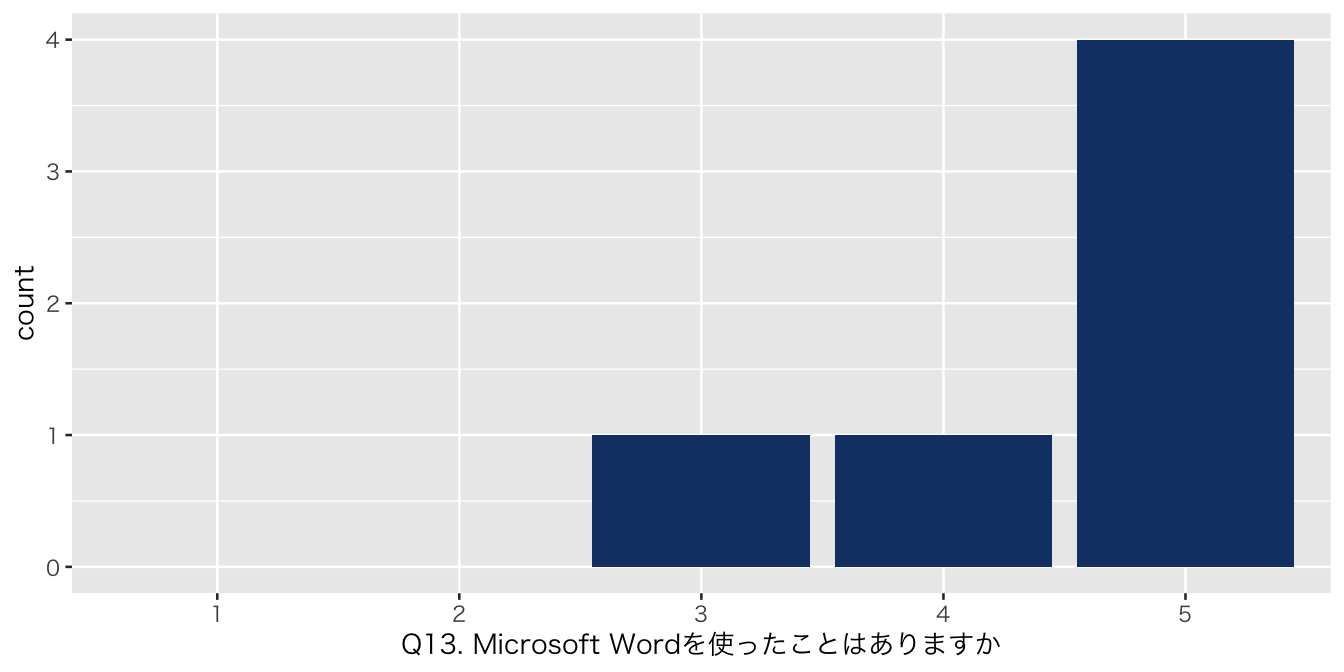
`Q13. Microsoft Wordを使ったことはありますか` = df_初回アンケート %>% select(`Q13. Microsoft Wordを使ったことはありますか`),
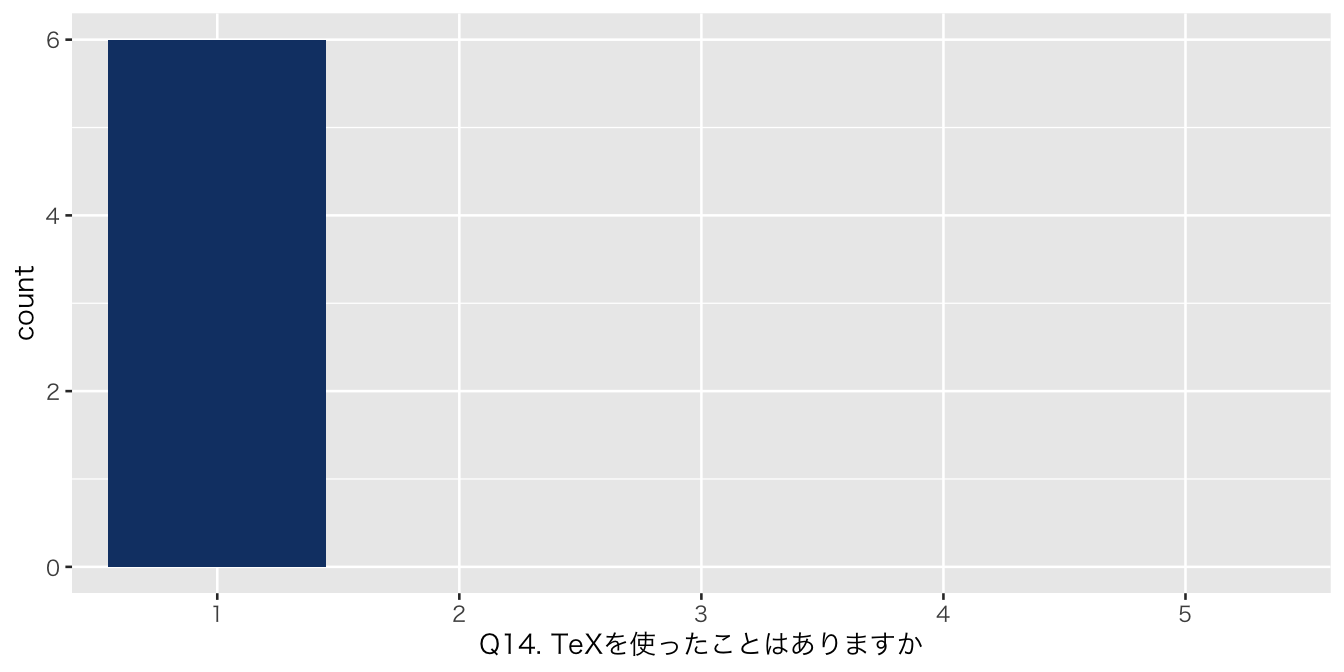
`Q14. TeXを使ったことはありますか` = df_初回アンケート %>% select(`Q14. TeXを使ったことはありますか`),
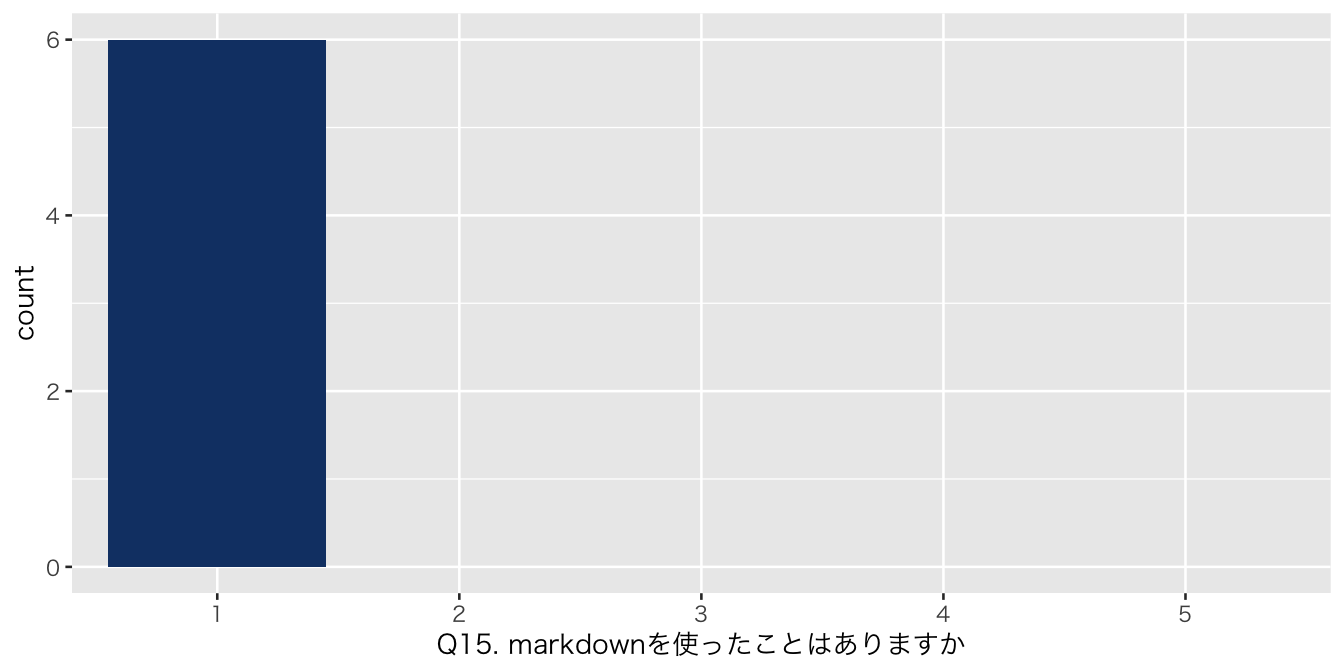
`Q15. markdownを使ったことはありますか` = df_初回アンケート %>% select(`Q15. markdownを使ったことはありますか`),
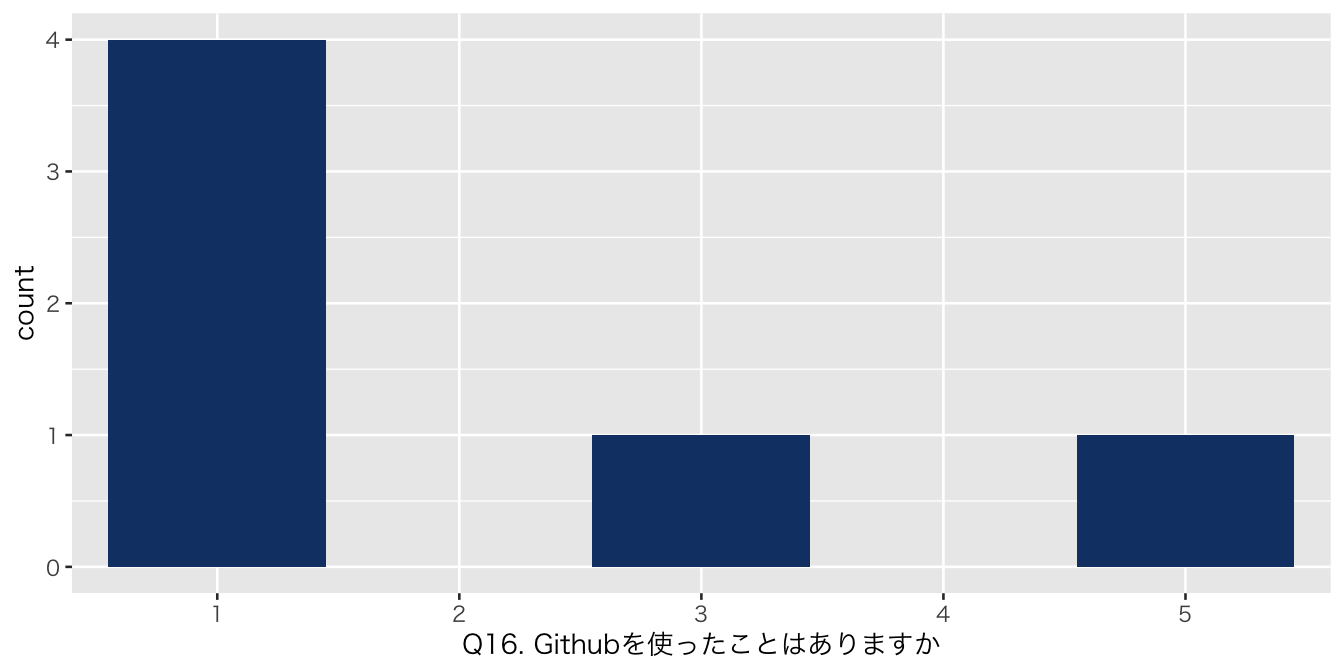
`Q16. Githubを使ったことはありますか` = df_初回アンケート %>% select(`Q16. Githubを使ったことはありますか`)
)
# 質問票の回答選択肢を1から5に設定
levels <- factor(1:5)
create_bar_plot <- function(df) {
question <- names(df)[1]
df[[question]] <- factor(df[[question]], levels = 1:5, labels = levels)
ggplot(df, aes(x = .data[[question]])) +
geom_bar(fill = "#134074FF") +
scale_x_discrete(drop = FALSE) + # データがなくてもx軸に表示
theme_gray(base_size = 10, base_family = "HiraginoSans-W3")
}
# 各質問に対して棒グラフを作成
plots <- map(data_list, create_bar_plot)
# すべてのプロットを表示
for (plot in plots) {
print(plot)
}
クロス集計
帯グラフ
Code
df_初回アンケート |>
group_by(学域, `Q5. 受講理由でもっとも近いものを選んでください`) %>%
mutate(学域 = factor(学域, levels = c("融合学域", "人間社会学域", "理工学域", "医薬保健学域"))) |>
summarise(
人数 = n(), .groups = "drop"
) |>
mutate(
比率 = 人数/sum(人数)
) |>
ungroup() |>
ggplot(aes(x = "", y = 人数, group = 学域)) +
geom_col(
aes(color = `Q5. 受講理由でもっとも近いものを選んでください`, fill = after_scale(alpha(color, 0.9))),
position = position_fill(),
) +
geom_text(
aes(label = str_c(scales::percent(比率, accuracy = 0.1), "(", 人数, "人)")),
position = position_fill(reverse = FALSE, vjust = 0.5),
) +
scale_y_continuous(
expand = expansion(mult = c(0.01, 0.01)),
labels = scales::label_percent()) +
labs(
x = "",
y = "",
color = "Q5"
) +
coord_flip() +
facet_wrap(~ 学域) +
theme(legend.position="bottom") + #凡例を図の下に
guides(color = guide_legend(nrow = 4, byrow = TRUE)) +
scale_color_paletteer_d("Manu::Hoiho")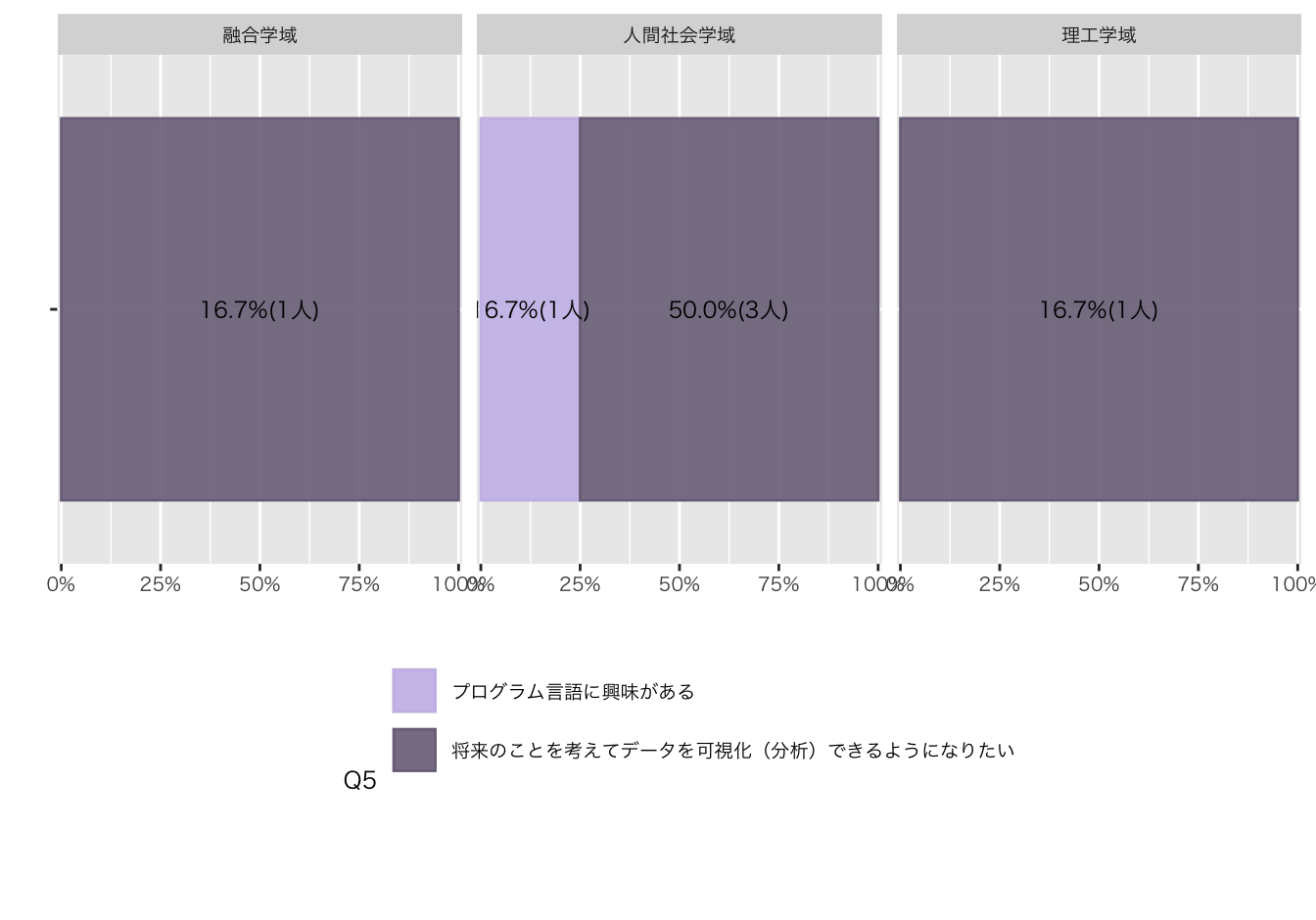
モザイク図
Code
df_mosaic <- df_初回アンケート_long |>
select(学域, 質問, 回答) |>
filter(!質問 %in% c("Q4. 可視化したいデータはありますか", "Q5. 受講理由でもっとも近いものを選んでください")) |>
mutate(質問 =substr(質問, 1, 3)) |>
mutate(across(everything(), as.factor)) |>
mutate(質問 = factor(質問, levels = c("Q1.", "Q2.", "Q3.", "Q6.", "Q7.", "Q8.", "Q9.", "Q10", "Q11", "Q12", "Q13", "Q14", "Q15", "Q16")))
ggplot(data = as.data.frame(df_mosaic)) +
geom_mosaic(aes(x = product(学域), fill = 回答)) +
labs(x = "", y = "") +
theme(legend.position="bottom",
base_family = "HiraKakuProN-W3") +
scale_fill_manual(values = c("#C2697FFF", "#FDDFA4FF", "#B4B9E0FF", "#513965FF", "#201B43FF", "#2C3778FF" ))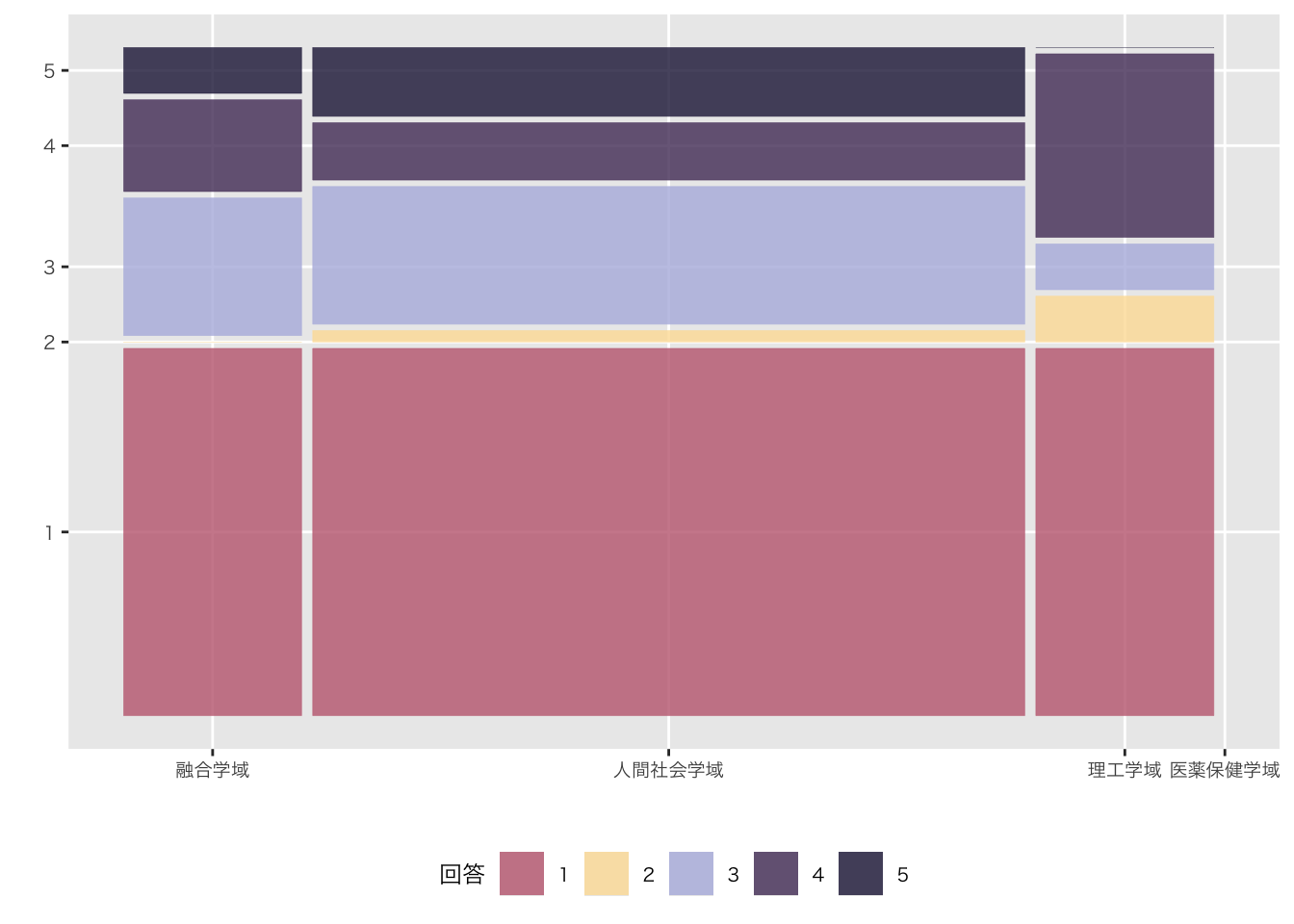
Code
df_mosaic <-
df_初回アンケート_long |>
select(学域, 質問, 回答) |>
filter(!質問 %in% c("Q4. 可視化したいデータはありますか", "Q5. 受講理由でもっとも近いものを選んでください")) |>
mutate(質問 =substr(質問, 1, 3)) |>
mutate(across(everything(), as.factor)) |>
mutate(質問 = factor(質問, levels = c("Q1.", "Q2.", "Q3.", "Q6.", "Q7.", "Q8.", "Q9.", "Q10", "Q11", "Q12", "Q13", "Q14", "Q15", "Q16")))
ggplot(data = as.data.frame(df_mosaic)) +
geom_mosaic(aes(x = product(質問), fill = 回答)) +
labs(x = "", y = "") +
coord_flip() +
scale_fill_manual(values = c("#C2697FFF", "#FDDFA4FF", "#B4B9E0FF", "#513965FF", "#201B43FF", "#2C3778FF" )) +
theme(legend.position="bottom",
base_family = "HiraKakuProN-W3")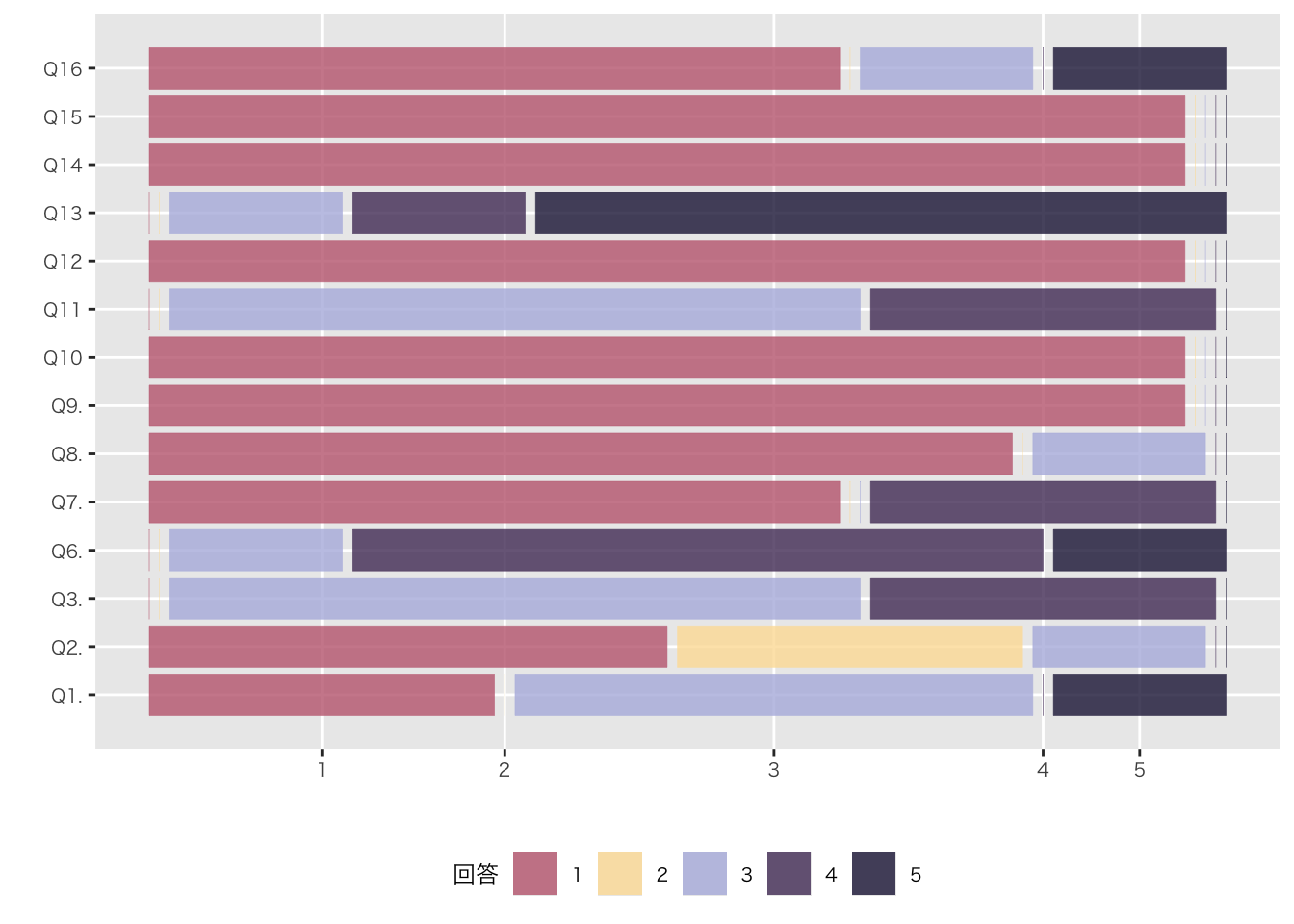
Code
ggplot(data = as.data.frame(df_mosaic)) +
geom_mosaic(aes(x = product(質問), fill = 回答)) +
labs(x = "", y = "") +
facet_wrap(. ~ 学域, nrow = 2) +
coord_flip() +
theme(legend.position="bottom",
base_family = "HiraKakuProN-W3") +
scale_fill_manual(values = c("#C2697FFF", "#FDDFA4FF", "#B4B9E0FF", "#513965FF", "#201B43FF", "#2C3778FF" ))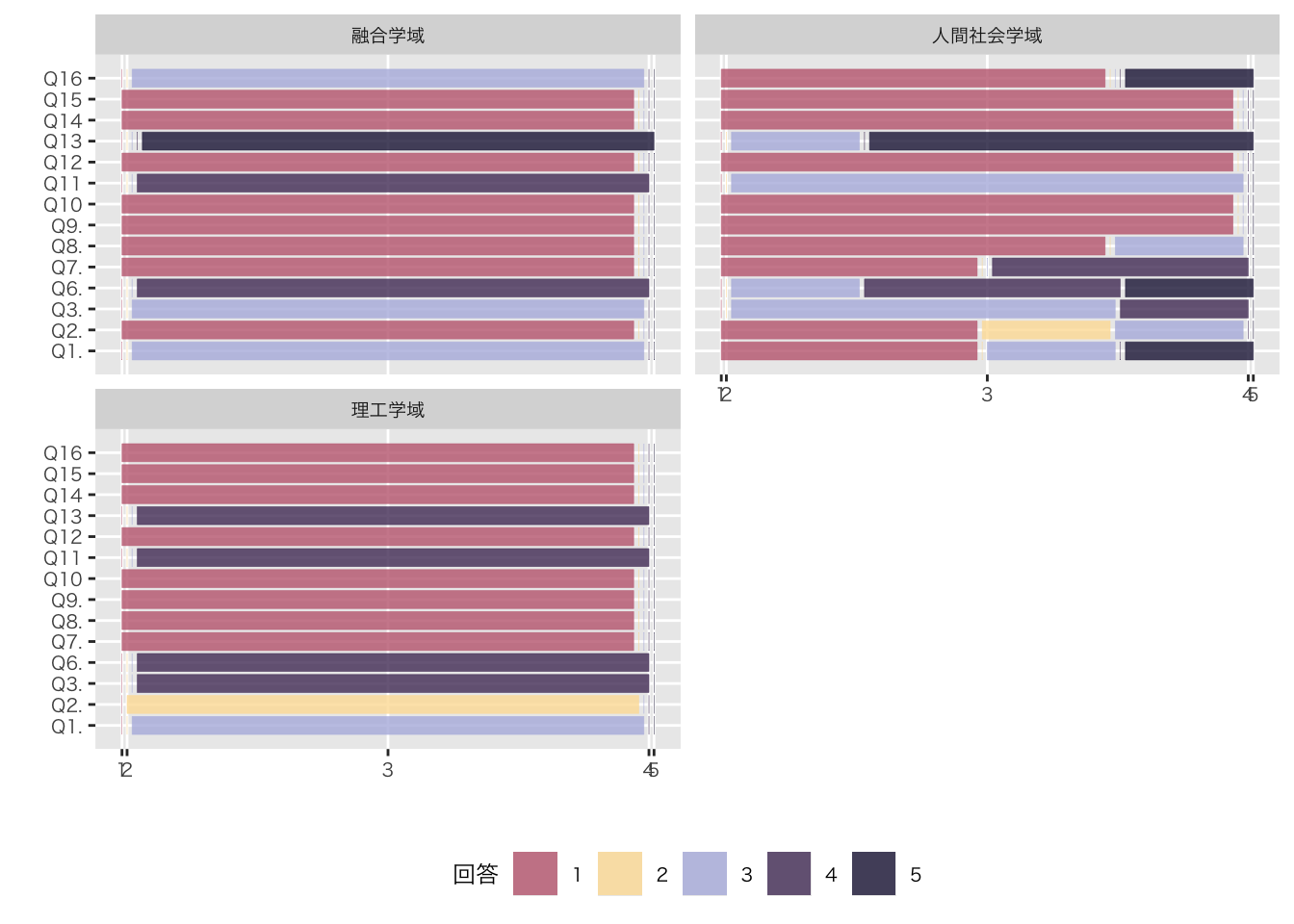
散布図
Code
df_初回アンケート |>
ggplot(aes(x = `Q1. パソコンのスキルに自信がありますか`,
y = `Q2. R言語を知っていますか?`, color = 学域)) +
scale_color_colorblind() +
geom_point() #散布図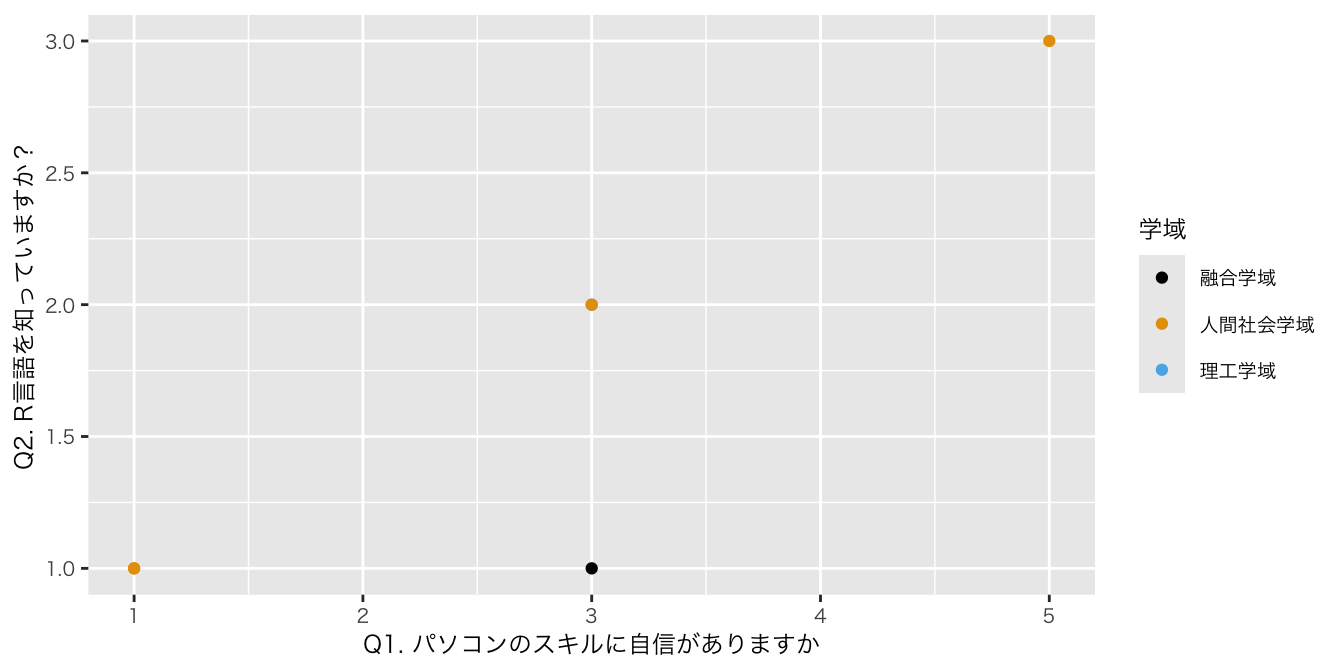
Code
df_初回アンケート |>
ggplot(aes(x = `Q1. パソコンのスキルに自信がありますか`,
y = `Q3. プログラム言語を使ったことはありますか`, color = 学域)) +
scale_color_colorblind() +
geom_point() #散布図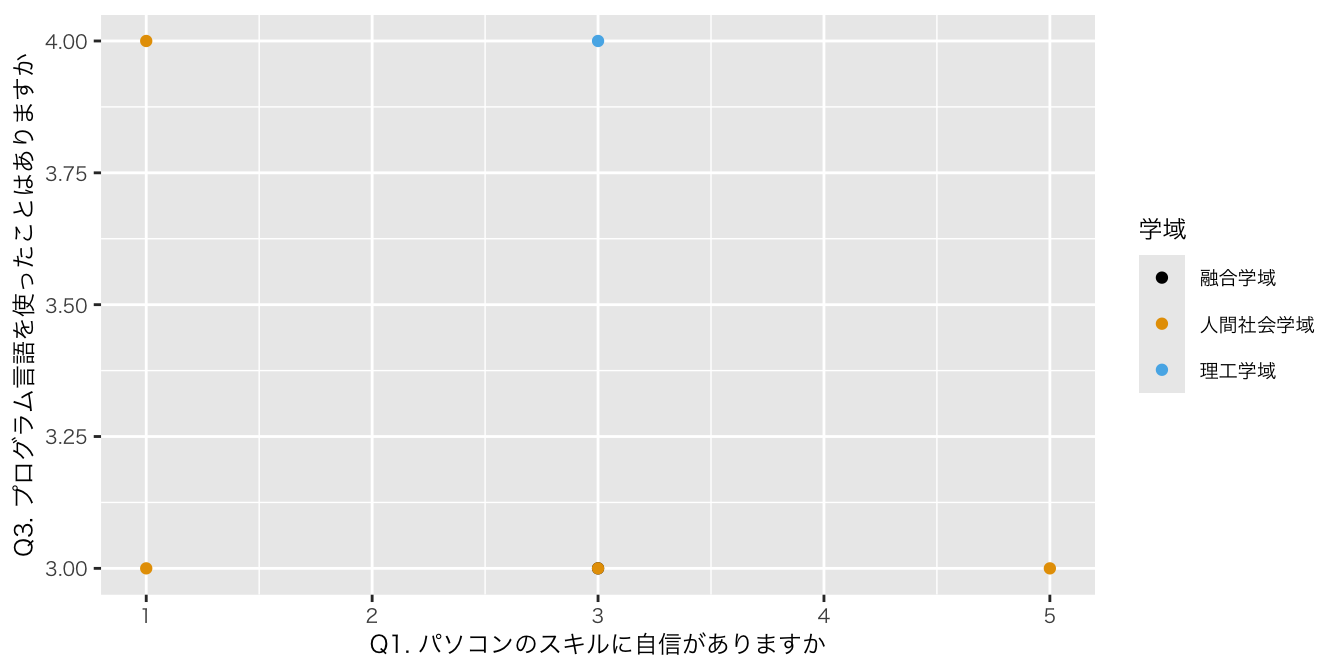
Code
df_初回アンケート |>
ggplot(aes(x = `Q6. Microsoft Excelを使ったことはありますか`,
y = `Q13. Microsoft Wordを使ったことはありますか`, color = 学域)) +
scale_color_colorblind() +
geom_point() #散布図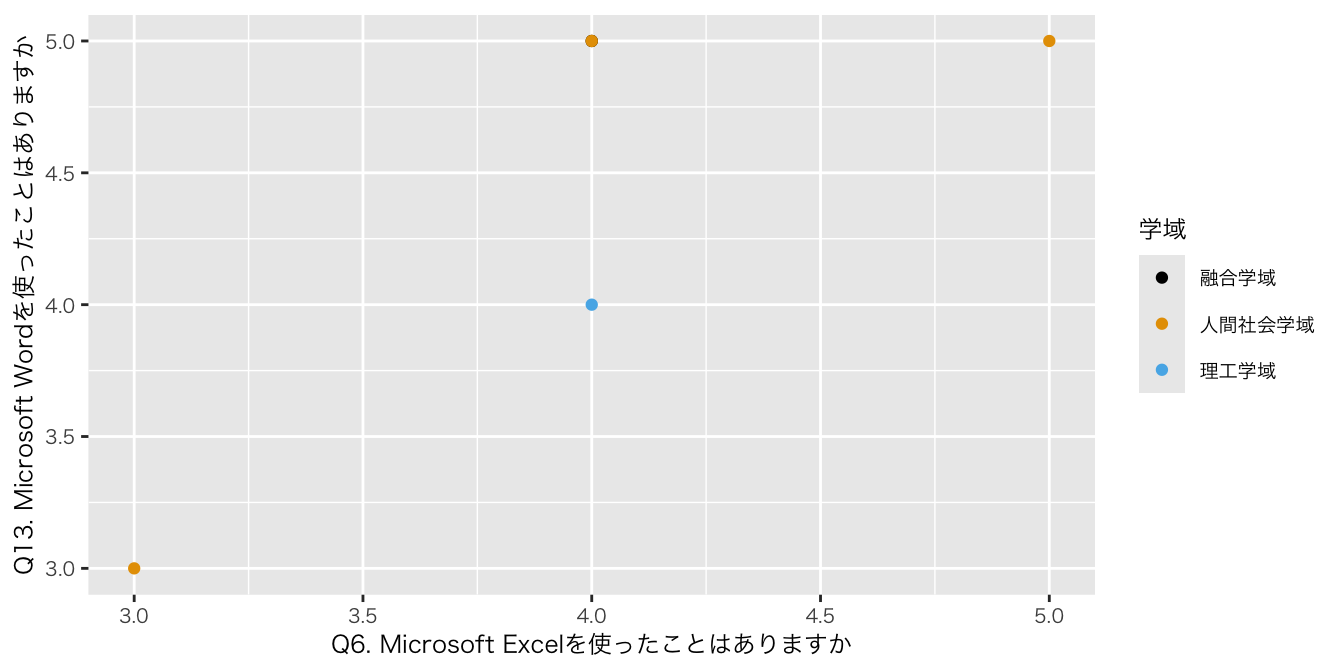
表
単純集計
Code
df_初回アンケート |>
select(!1:4) |>
tbl_summary()| Characteristic | N = 61 |
|---|---|
| 学域 | |
| 融合学域 | 1 (17%) |
| 人間社会学域 | 4 (67%) |
| 理工学域 | 1 (17%) |
| 医薬保健学域 | 0 (0%) |
| 学年 | |
| 1年生 | 2 (33%) |
| 2年生 | 1 (17%) |
| 3年生 | 2 (33%) |
| 4年生 | 1 (17%) |
| Q1. パソコンのスキルに自信がありますか | |
| 1 | 2 (33%) |
| 3 | 3 (50%) |
| 5 | 1 (17%) |
| Q2. R言語を知っていますか? | |
| 1 | 3 (50%) |
| 2 | 2 (33%) |
| 3 | 1 (17%) |
| Q3. プログラム言語を使ったことはありますか | |
| 3 | 4 (67%) |
| 4 | 2 (33%) |
| Q4. 可視化したいデータはありますか | |
| ある(具体的なデータがある) | 1 (17%) |
| ある(具体的なデータはないが、分野は特定できる) | 4 (67%) |
| ない(時間があれば、考えられそう) | 1 (17%) |
| Q5. 受講理由でもっとも近いものを選んでください | |
| プログラム言語に興味がある | 1 (17%) |
| 将来のことを考えてデータを可視化(分析)できるようになりたい | 5 (83%) |
| Q6. Microsoft Excelを使ったことはありますか | |
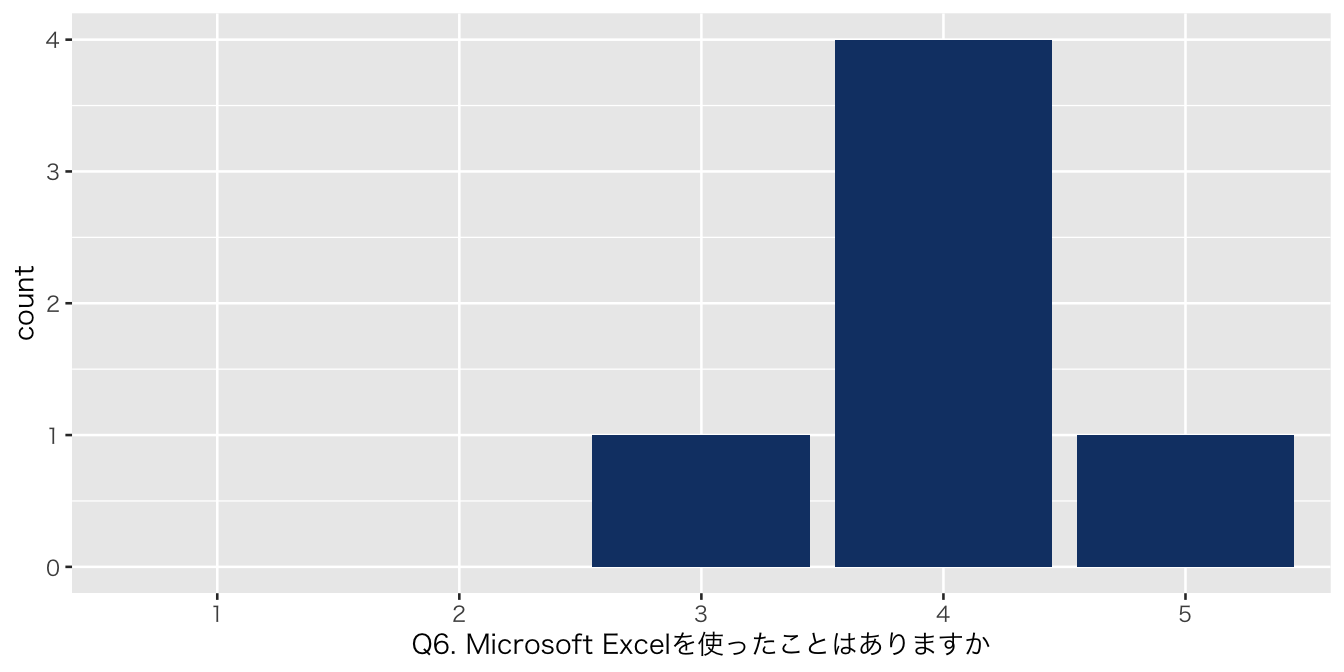
| 3 | 1 (17%) |
| 4 | 4 (67%) |
| 5 | 1 (17%) |
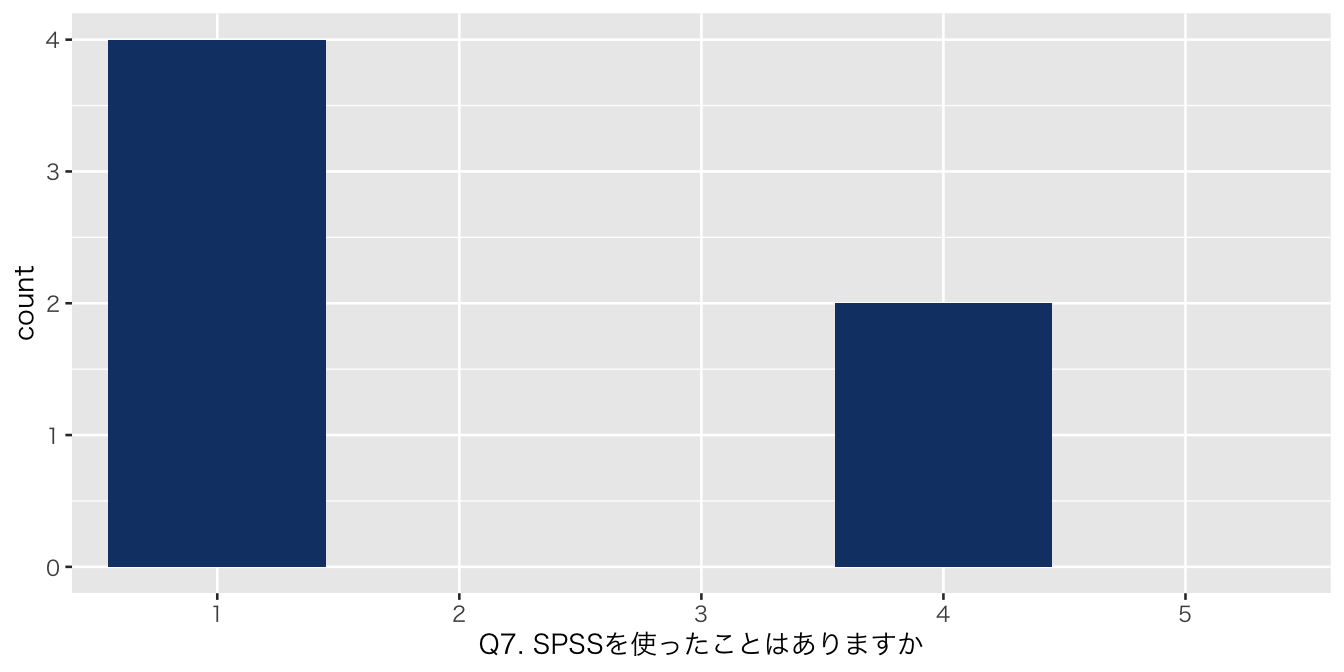
| Q7. SPSSを使ったことはありますか | |
| 1 | 4 (67%) |
| 4 | 2 (33%) |
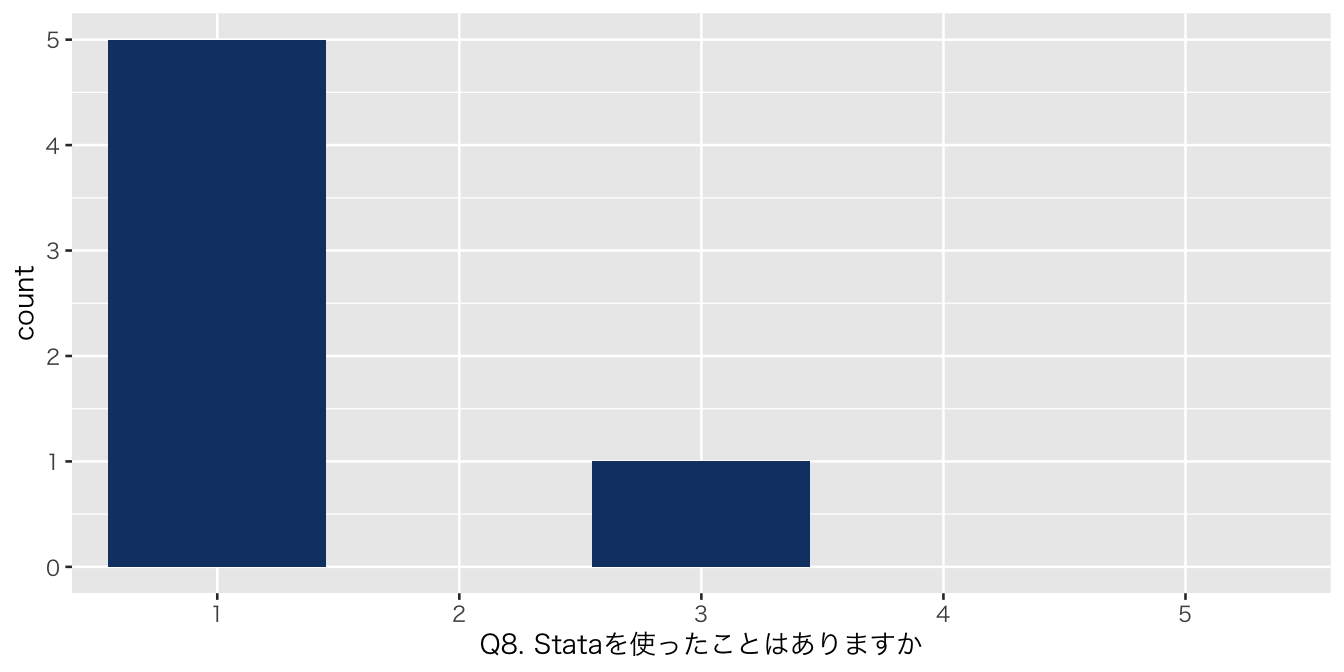
| Q8. Stataを使ったことはありますか | |
| 1 | 5 (83%) |
| 3 | 1 (17%) |
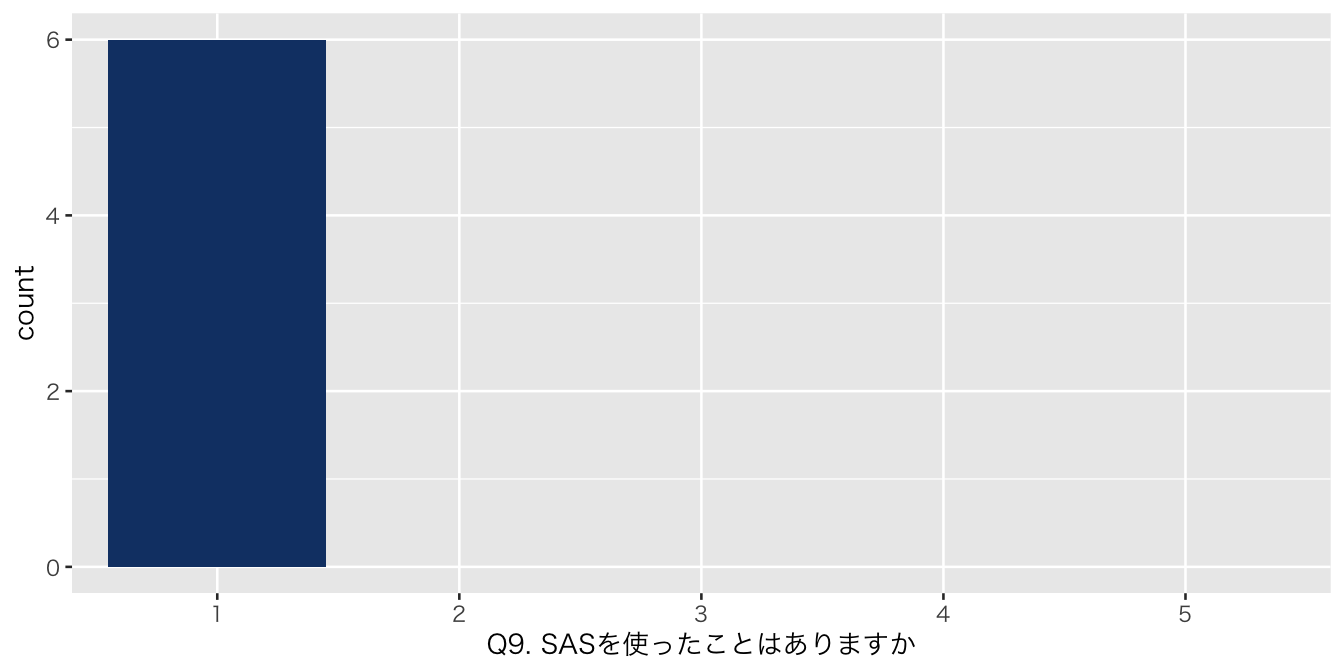
| Q9. SASを使ったことはありますか | |
| 1 | 6 (100%) |
| Q10. tableauを使ったことはありますか | |
| 1 | 6 (100%) |
| Q11. pythonを使ったことはありますか | |
| 3 | 4 (67%) |
| 4 | 2 (33%) |
| Q12. MATLABを使ったことがありますか | |
| 1 | 6 (100%) |
| Q13. Microsoft Wordを使ったことはありますか | |
| 3 | 1 (17%) |
| 4 | 1 (17%) |
| 5 | 4 (67%) |
| Q14. TeXを使ったことはありますか | |
| 1 | 6 (100%) |
| Q15. markdownを使ったことはありますか | |
| 1 | 6 (100%) |
| Q16. Githubを使ったことはありますか | |
| 1 | 4 (67%) |
| 3 | 1 (17%) |
| 5 | 1 (17%) |
| 1 n (%) | |
基本統計量
Code
df_初回アンケート |>
select(!1:4) |>
skim() |>
gt()| skim_type | skim_variable | n_missing | complete_rate | character.min | character.max | character.empty | character.n_unique | character.whitespace | factor.ordered | factor.n_unique | factor.top_counts | numeric.mean | numeric.sd | numeric.p0 | numeric.p25 | numeric.p50 | numeric.p75 | numeric.p100 | numeric.hist |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| character | 学年 | 0 | 1 | 3 | 3 | 0 | 4 | 0 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| character | Q4. 可視化したいデータはありますか | 0 | 1 | 14 | 24 | 0 | 3 | 0 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| character | Q5. 受講理由でもっとも近いものを選んでください | 0 | 1 | 13 | 30 | 0 | 2 | 0 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| factor | 学域 | 0 | 1 | NA | NA | NA | NA | NA | FALSE | 3 | 人間社: 4, 融合学: 1, 理工学: 1, 医薬保: 0 | NA | NA | NA | NA | NA | NA | NA | NA |
| numeric | Q1. パソコンのスキルに自信がありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 2.666667 | 1.5055453 | 1 | 1.50 | 3.0 | 3.00 | 5 | ▅▁▇▁▂ |
| numeric | Q2. R言語を知っていますか? | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.666667 | 0.8164966 | 1 | 1.00 | 1.5 | 2.00 | 3 | ▇▁▅▁▂ |
| numeric | Q3. プログラム言語を使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 3.333333 | 0.5163978 | 3 | 3.00 | 3.0 | 3.75 | 4 | ▇▁▁▁▃ |
| numeric | Q6. Microsoft Excelを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 4.000000 | 0.6324555 | 3 | 4.00 | 4.0 | 4.00 | 5 | ▂▁▇▁▂ |
| numeric | Q7. SPSSを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 2.000000 | 1.5491933 | 1 | 1.00 | 1.0 | 3.25 | 4 | ▇▁▁▁▃ |
| numeric | Q8. Stataを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.333333 | 0.8164966 | 1 | 1.00 | 1.0 | 1.00 | 3 | ▇▁▁▁▂ |
| numeric | Q9. SASを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.000000 | 0.0000000 | 1 | 1.00 | 1.0 | 1.00 | 1 | ▁▁▇▁▁ |
| numeric | Q10. tableauを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.000000 | 0.0000000 | 1 | 1.00 | 1.0 | 1.00 | 1 | ▁▁▇▁▁ |
| numeric | Q11. pythonを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 3.333333 | 0.5163978 | 3 | 3.00 | 3.0 | 3.75 | 4 | ▇▁▁▁▃ |
| numeric | Q12. MATLABを使ったことがありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.000000 | 0.0000000 | 1 | 1.00 | 1.0 | 1.00 | 1 | ▁▁▇▁▁ |
| numeric | Q13. Microsoft Wordを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 4.500000 | 0.8366600 | 3 | 4.25 | 5.0 | 5.00 | 5 | ▂▁▂▁▇ |
| numeric | Q14. TeXを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.000000 | 0.0000000 | 1 | 1.00 | 1.0 | 1.00 | 1 | ▁▁▇▁▁ |
| numeric | Q15. markdownを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 1.000000 | 0.0000000 | 1 | 1.00 | 1.0 | 1.00 | 1 | ▁▁▇▁▁ |
| numeric | Q16. Githubを使ったことはありますか | 0 | 1 | NA | NA | NA | NA | NA | NA | NA | NA | 2.000000 | 1.6733201 | 1 | 1.00 | 1.0 | 2.50 | 5 | ▇▁▂▁▂ |
Code
df_初回アンケート |>
select(!1:4) |>
get_summary_stats() |>
gt()| variable | n | min | max | median | q1 | q3 | iqr | mad | mean | sd | se | ci |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q1. パソコンのスキルに自信がありますか | 6 | 1 | 5 | 3.0 | 1.50 | 3.00 | 1.50 | 1.483 | 2.667 | 1.506 | 0.615 | 1.580 |
| Q2. R言語を知っていますか? | 6 | 1 | 3 | 1.5 | 1.00 | 2.00 | 1.00 | 0.741 | 1.667 | 0.816 | 0.333 | 0.857 |
| Q3. プログラム言語を使ったことはありますか | 6 | 3 | 4 | 3.0 | 3.00 | 3.75 | 0.75 | 0.000 | 3.333 | 0.516 | 0.211 | 0.542 |
| Q6. Microsoft Excelを使ったことはありますか | 6 | 3 | 5 | 4.0 | 4.00 | 4.00 | 0.00 | 0.000 | 4.000 | 0.632 | 0.258 | 0.664 |
| Q7. SPSSを使ったことはありますか | 6 | 1 | 4 | 1.0 | 1.00 | 3.25 | 2.25 | 0.000 | 2.000 | 1.549 | 0.632 | 1.626 |
| Q8. Stataを使ったことはありますか | 6 | 1 | 3 | 1.0 | 1.00 | 1.00 | 0.00 | 0.000 | 1.333 | 0.816 | 0.333 | 0.857 |
| Q9. SASを使ったことはありますか | 6 | 1 | 1 | 1.0 | 1.00 | 1.00 | 0.00 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 |
| Q10. tableauを使ったことはありますか | 6 | 1 | 1 | 1.0 | 1.00 | 1.00 | 0.00 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 |
| Q11. pythonを使ったことはありますか | 6 | 3 | 4 | 3.0 | 3.00 | 3.75 | 0.75 | 0.000 | 3.333 | 0.516 | 0.211 | 0.542 |
| Q12. MATLABを使ったことがありますか | 6 | 1 | 1 | 1.0 | 1.00 | 1.00 | 0.00 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 |
| Q13. Microsoft Wordを使ったことはありますか | 6 | 3 | 5 | 5.0 | 4.25 | 5.00 | 0.75 | 0.000 | 4.500 | 0.837 | 0.342 | 0.878 |
| Q14. TeXを使ったことはありますか | 6 | 1 | 1 | 1.0 | 1.00 | 1.00 | 0.00 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 |
| Q15. markdownを使ったことはありますか | 6 | 1 | 1 | 1.0 | 1.00 | 1.00 | 0.00 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 |
| Q16. Githubを使ったことはありますか | 6 | 1 | 5 | 1.0 | 1.00 | 2.50 | 1.50 | 0.000 | 2.000 | 1.673 | 0.683 | 1.756 |
クロス集計
Code
data_list2 <- list(
`Q1. パソコンのスキルに自信がありますか` = df_初回アンケート %>% select(`Q1. パソコンのスキルに自信がありますか`),
`Q2. R言語を知っていますか?` = df_初回アンケート %>% select(`Q2. R言語を知っていますか?`),
`Q3. プログラム言語を使ったことはありますか` = df_初回アンケート %>% select(`Q3. プログラム言語を使ったことはありますか`)
# Q4 = df_初回アンケート_test %>% select(Q4),
# Q5 = df_初回アンケート_test %>% select(Q5)
)
create_table <- function(df) {
df_初回アンケート |>
select(!1:4)|>
tbl_summary(by = 学域) |>
add_p(test = list(
all_continuous() ~ "t.test",
all_categorical() ~ "fisher.test"
),
test.args = all_continuous() ~ list(var.equal = TRUE)) %>%
bold_p(t = 0.05) |>
as_gt()
}
# 各質問に対して棒グラフを作成
result_list <- map(data_list, create_table)
# すべてのプロットを表示
result_listCode
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q1. パソコンのスキルに自信がありますか | |||||
| 1 | 0 (0%) | 2 (50%) | 0 (0%) | 0 (NA%) | |
| 3 | 1 (100%) | 1 (25%) | 1 (100%) | 0 (NA%) | |
| 5 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q2. R言語を知っていますか? | |||||
| 1 | 1 (100%) | 2 (50%) | 0 (0%) | 0 (NA%) | |
| 2 | 0 (0%) | 1 (25%) | 1 (100%) | 0 (NA%) | |
| 3 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q3. プログラム言語を使ったことはありますか | |||||
| 3 | 1 (100%) | 3 (75%) | 0 (0%) | 0 (NA%) | |
| 4 | 0 (0%) | 1 (25%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q4. 可視化したいデータはありますか | |||||
| ある(具体的なデータがある) | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| ある(具体的なデータはないが、分野は特定できる) | 1 (100%) | 3 (75%) | 0 (0%) | 0 (NA%) | |
| ない(時間があれば、考えられそう) | 0 (0%) | 0 (0%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q5. 受講理由でもっとも近いものを選んでください | |||||
| プログラム言語に興味がある | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 将来のことを考えてデータを可視化(分析)できるようになりたい | 1 (100%) | 3 (75%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q6. Microsoft Excelを使ったことはありますか | |||||
| 3 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 4 | 1 (100%) | 2 (50%) | 1 (100%) | 0 (NA%) | |
| 5 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q7. SPSSを使ったことはありますか | |||||
| 1 | 1 (100%) | 2 (50%) | 1 (100%) | 0 (NA%) | |
| 4 | 0 (0%) | 2 (50%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q8. Stataを使ったことはありますか | |||||
| 1 | 1 (100%) | 3 (75%) | 1 (100%) | 0 (NA%) | |
| 3 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q9. SASを使ったことはありますか | |||||
| 1 | 1 (100%) | 4 (100%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q10. tableauを使ったことはありますか | |||||
| 1 | 1 (100%) | 4 (100%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q11. pythonを使ったことはありますか | |||||
| 3 | 0 (0%) | 4 (100%) | 0 (0%) | 0 (NA%) | |
| 4 | 1 (100%) | 0 (0%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q12. MATLABを使ったことがありますか | |||||
| 1 | 1 (100%) | 4 (100%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q13. Microsoft Wordを使ったことはありますか | |||||
| 3 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 4 | 0 (0%) | 0 (0%) | 1 (100%) | 0 (NA%) | |
| 5 | 1 (100%) | 3 (75%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q14. TeXを使ったことはありますか | |||||
| 1 | 1 (100%) | 4 (100%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q15. markdownを使ったことはありますか | |||||
| 1 | 1 (100%) | 4 (100%) | 1 (100%) | 0 (NA%) | |
| 1 n (%) | |||||
Code
| Characteristic |
融合学域 N = 11 |
人間社会学域 N = 41 |
理工学域 N = 11 |
医薬保健学域 N = 01 |
p-value |
|---|---|---|---|---|---|
| Q16. Githubを使ったことはありますか | |||||
| 1 | 0 (0%) | 3 (75%) | 1 (100%) | 0 (NA%) | |
| 3 | 1 (100%) | 0 (0%) | 0 (0%) | 0 (NA%) | |
| 5 | 0 (0%) | 1 (25%) | 0 (0%) | 0 (NA%) | |
| 1 n (%) | |||||
Copyright
苅谷千尋