RとQuartoではじめるデータサイエンス
#3 可視化(1)
苅谷千尋 
金沢大学
April 22, 2026
ggplot
3要素
- data(材料)
- aes(設計図)
- geom(描く)

ggplot
+レイヤー演算子- グラフの要素を順番に重ねて追加する
- ggplotでは、図を「部品の重ね合わせ」として作るために使う記号
- パイプ演算子(
|>)が「処理の流れ」をつなぐのに対して、+は「図の構成要素を追加する」
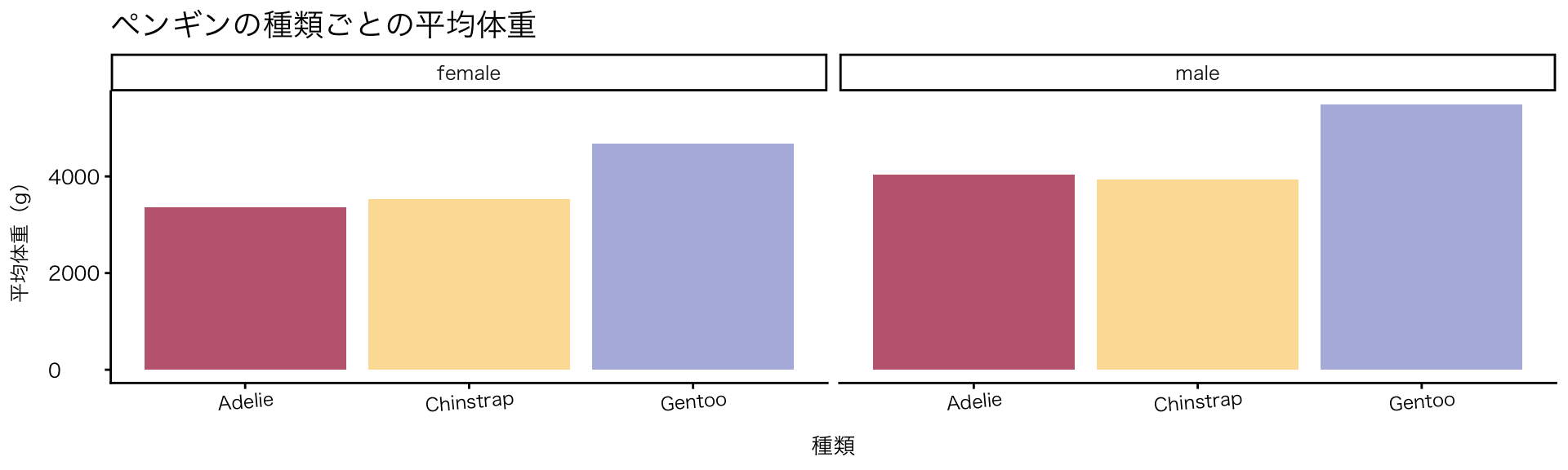
penguins |>
drop_na(species, sex, body_mass) |>
group_by(species, sex) |>
summarise(avg_body_mass = mean(body_mass), .groups = "drop") |>
ggplot(aes(x = species, y = avg_body_mass, fill = species)) +
geom_col() + # 今回説明するのはここまで。以後の見た目に関わる説明は第5回目に説明予定
facet_wrap(~ sex) +
labs(
title = "ペンギンの種類ごとの平均体重",
x = "種類",
y = "平均体重(g)"
) +
scale_fill_paletteer_d("DresdenColor::briefcases") +
theme(
legend.position = "none",
plot.title = element_text(size = 14, face = "bold"),
axis.text.x = element_text(angle = 5)
)
見た目の調整
- ラベルや塗色の変更も重要だが、回を分けて紹介する
- 今回は必要最低限の範囲で簡単に言及する
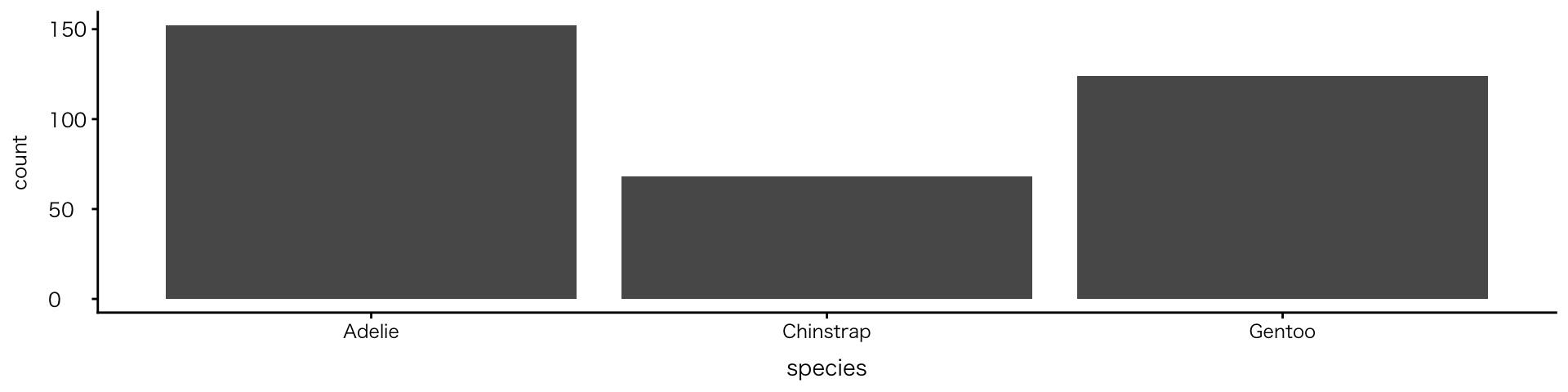
単変数:カテゴリ
棒グラフ
geom_bar()- xごとに件数を集計して棒の高さにする(自動カウント・元データを使用する)
- Cf. よく似た関数に
geom_col()がある 後ほど説明します- データフレームの列をそのまま使って棒の高さにする(元データを集計してggplotに渡すことが必要)
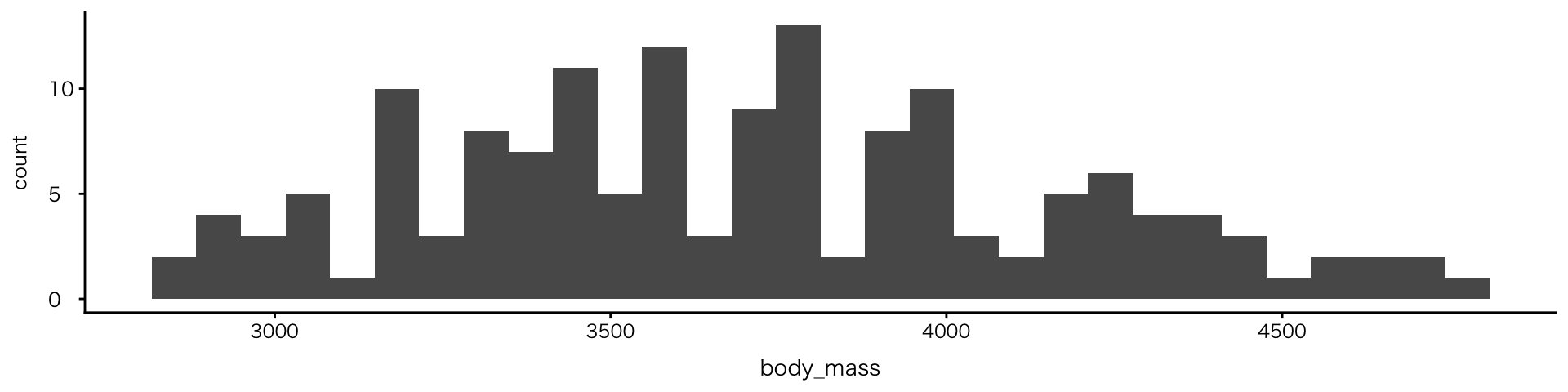
単変数:連続値
ヒストグラム
geom_histogram()- 数値の「分布」を見る
- 値を区間(ビン)に分けて数える
ビン区間(デフォルト)
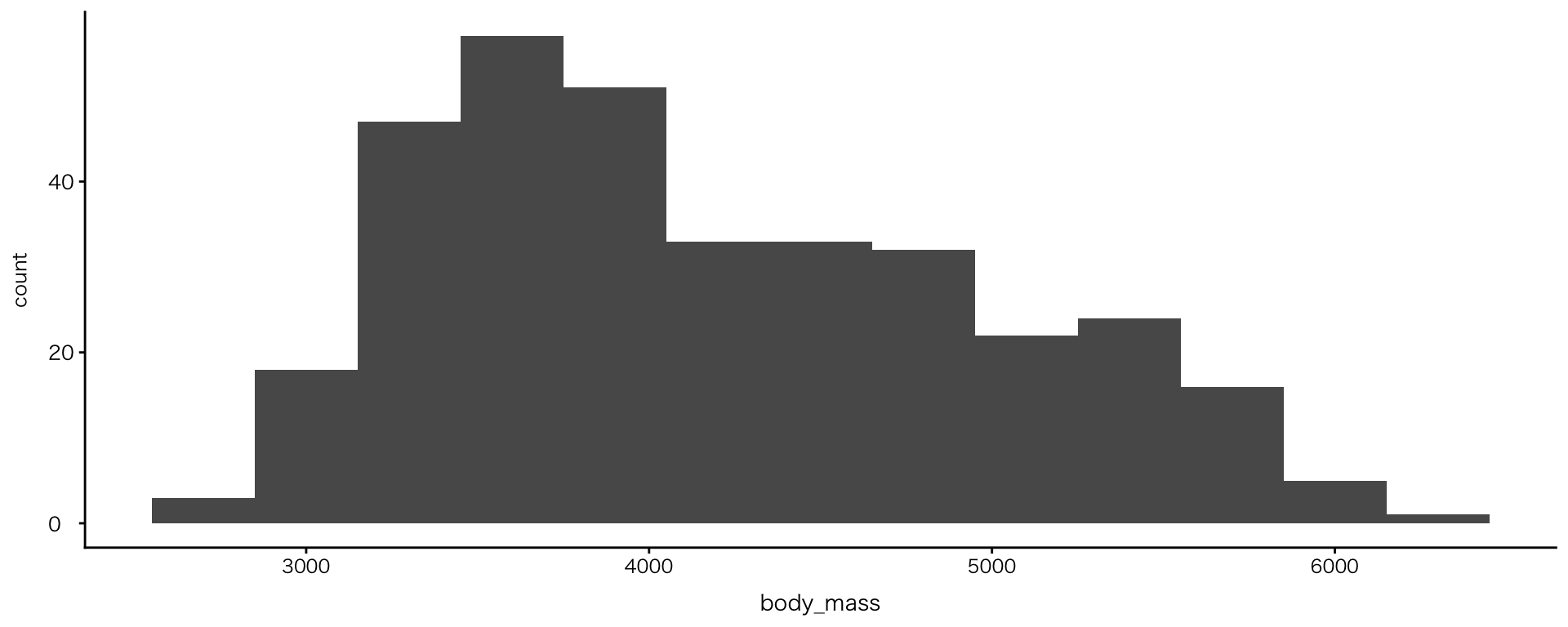
単変数:連続値 > ヒストグラム
ビン区間を引数binwidthで指定
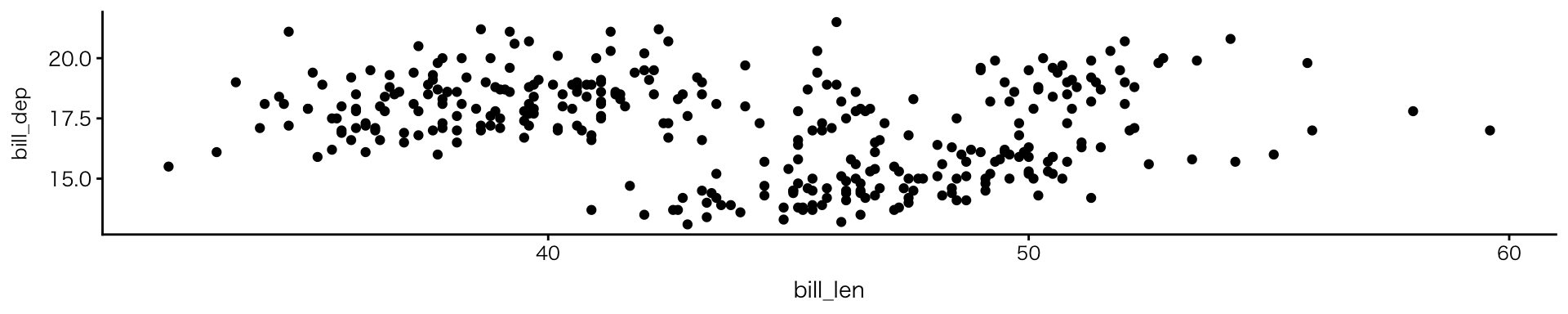
2変数:数値 × 数値
散布図
geom_point()- 2つの数値変数の関係(傾向・ばらつき)を可視化
- 読み取りのポイント
- 全体の傾向(右上がり/右下がり)
- ばらつき(点の広がり)
- 外れ値(他と大きく離れた点)
2変数:カテゴリ×カテゴリ
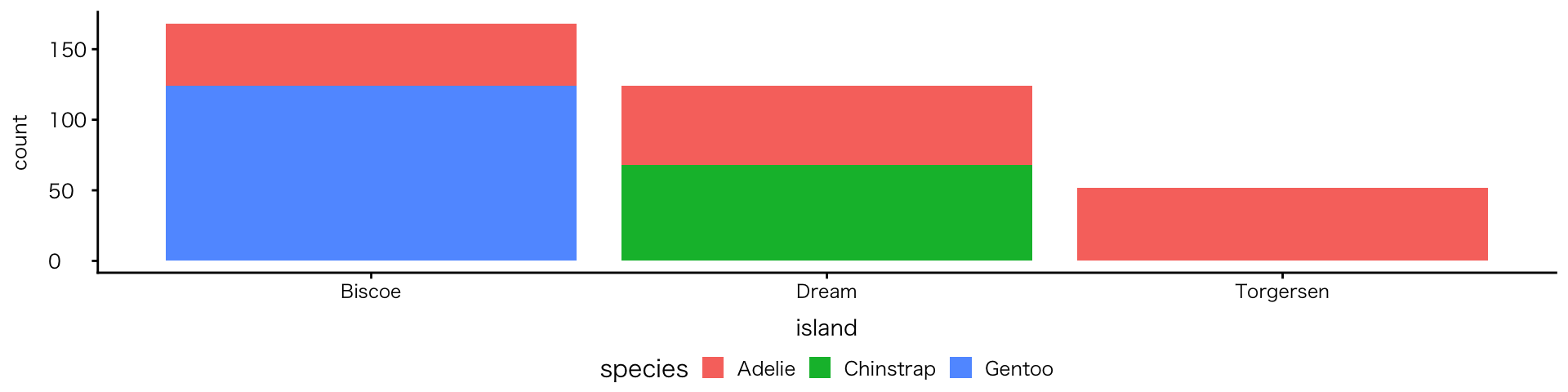
積み上げ棒グラフ
- aes で fill を指定
- 内訳ごとに色分けされて積み上げ表示される
- 表示方法は
geom_bar()のposition引数で変更できる- 3種類:
stack(何も指定しなければstack);dodge;fill
- 3種類:
- fillは多くのgeom関数で使えるが、表示のされ方は関数で異なる
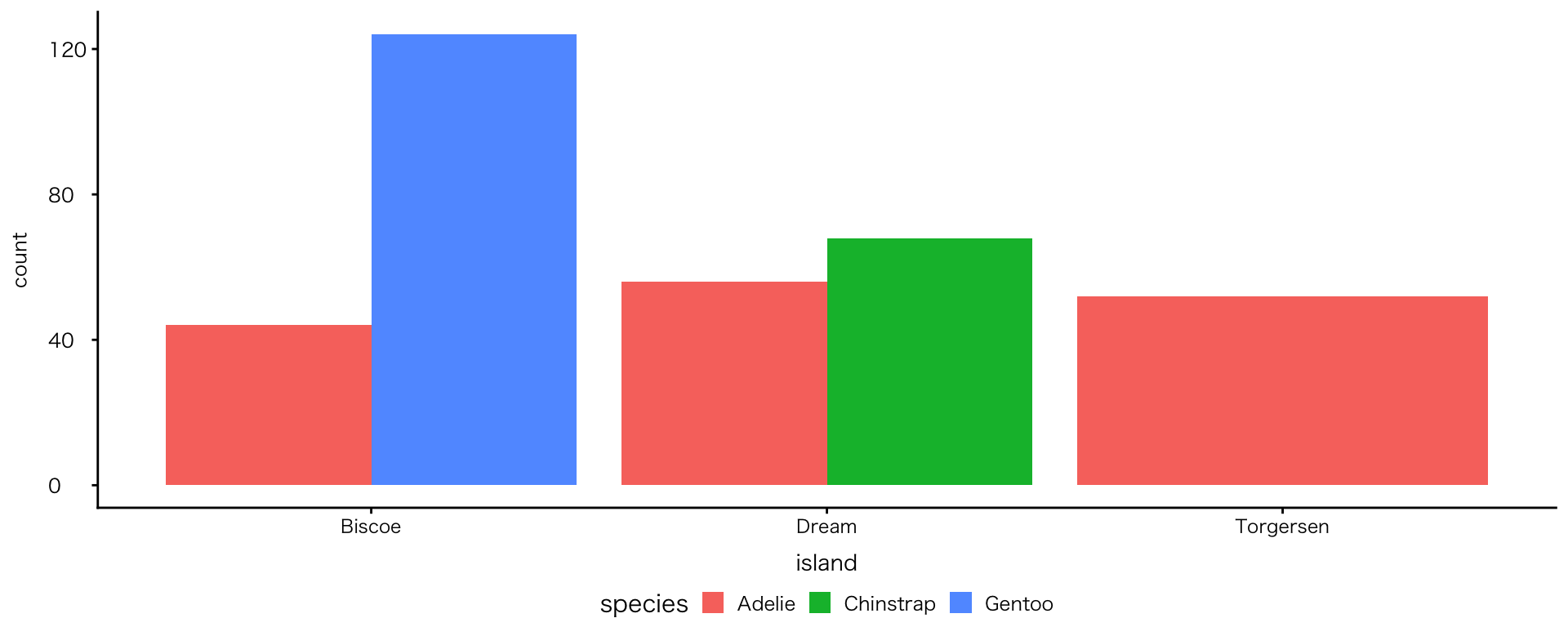
2変数:カテゴリ×カテゴリ
並列棒グラフ
geom_bar(position = "dodge")- dodge(避ける、かわすの意):重なりを避けて横に配置
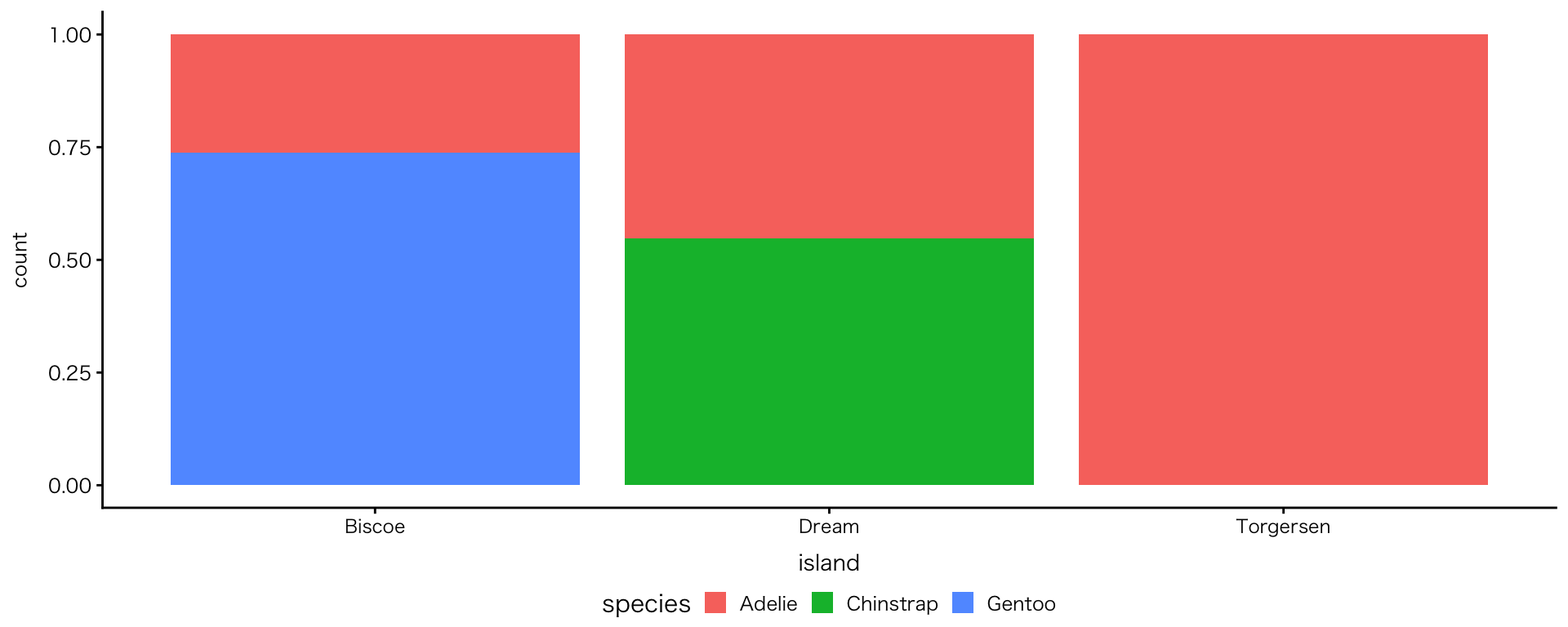
2変数:カテゴリ×カテゴリ
帯グラフ
geom_bar(position = "fill")- 各カテゴリの構成比(割合)で表示
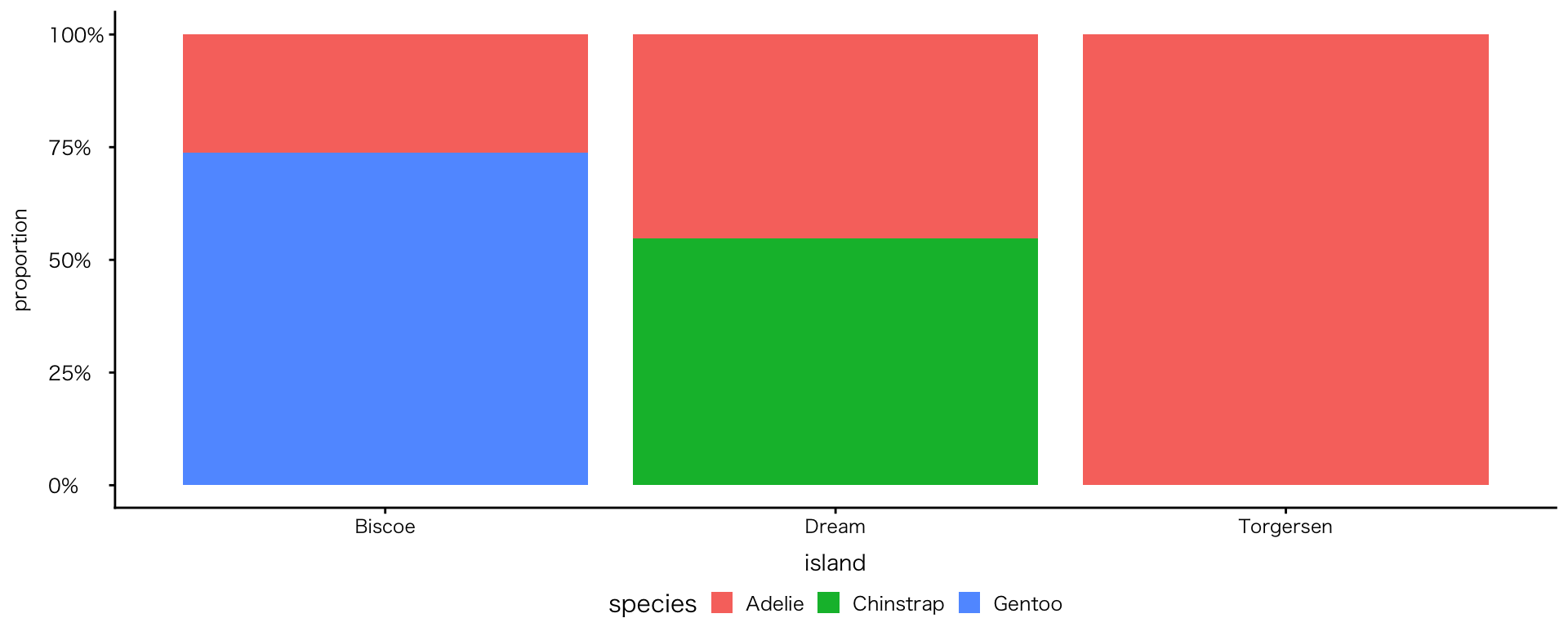
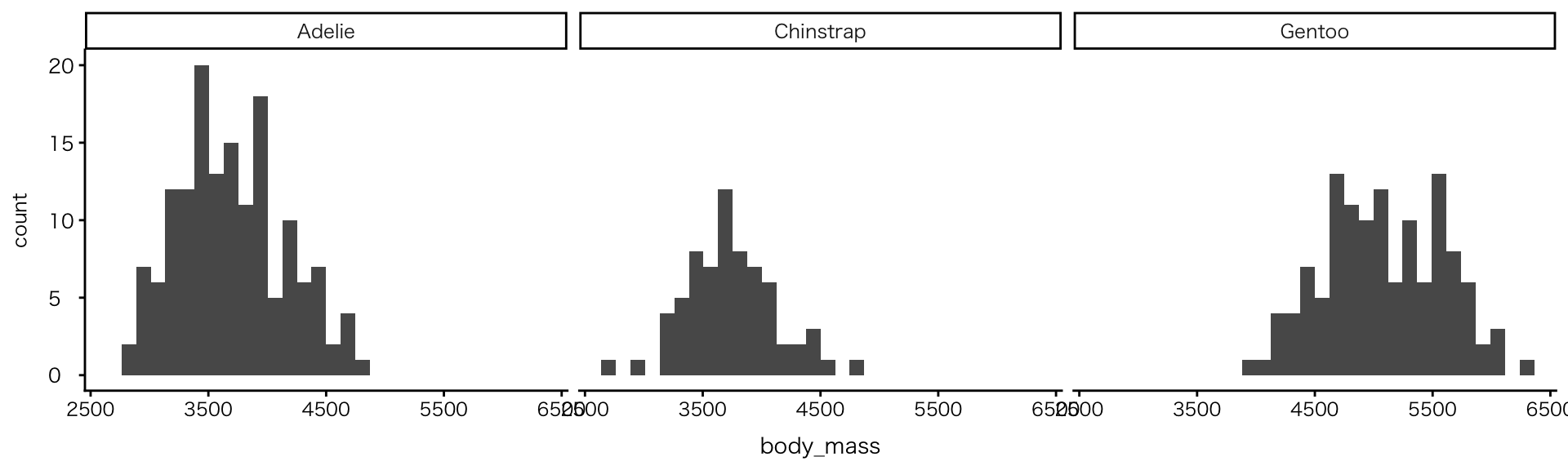
2変数:連続値×カテゴリ
ヒストグラム
geom_histogram()- 特別な引数はない
- ggplotに渡す前にグループ分け(
group_by)を行い、facet_wrapで分ける
- 分布状況の確認に加え、グループ間比較が可能
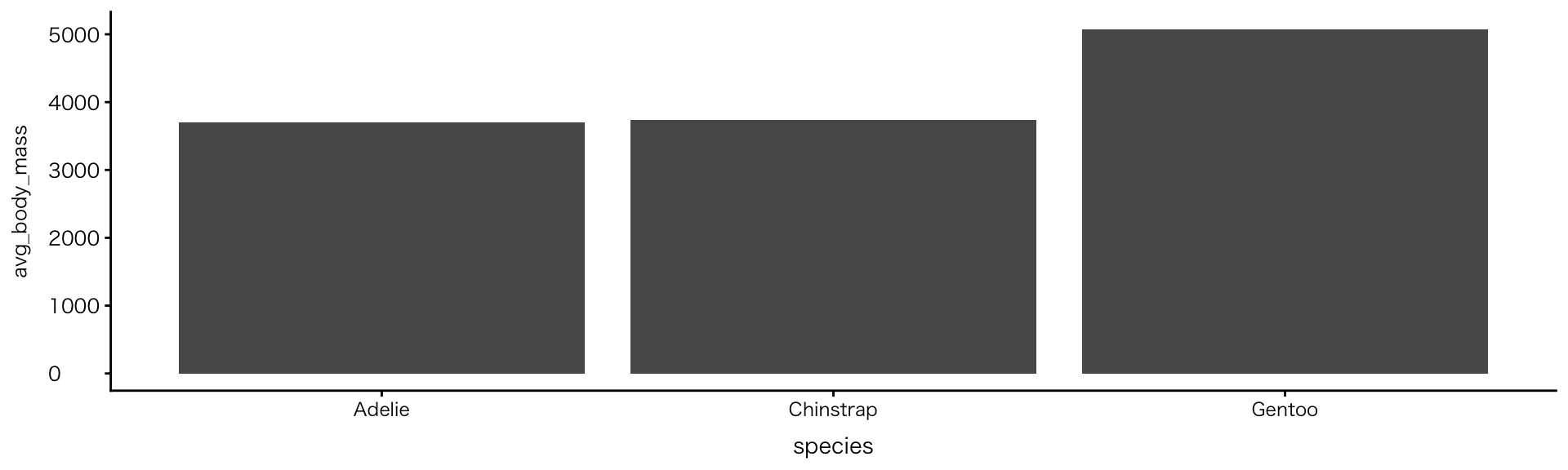
2変数:カテゴリ×数値
棒グラフ
geom_col()- カテゴリ別に集計した数値を可視化
- dplyr系の関数(
summarise()など)についての知識を要する - ここでは算出した平均値をプロットした例を示す
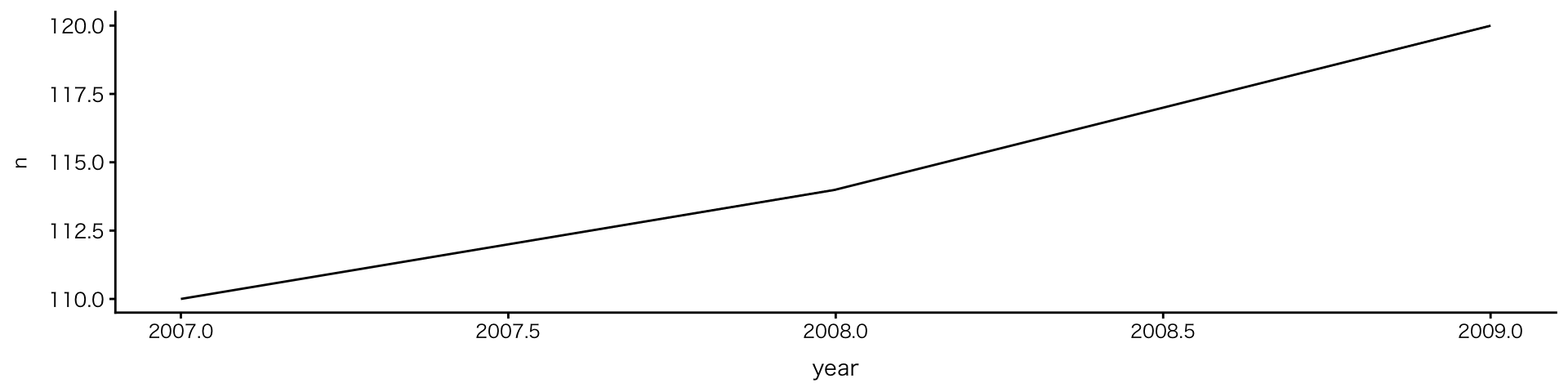
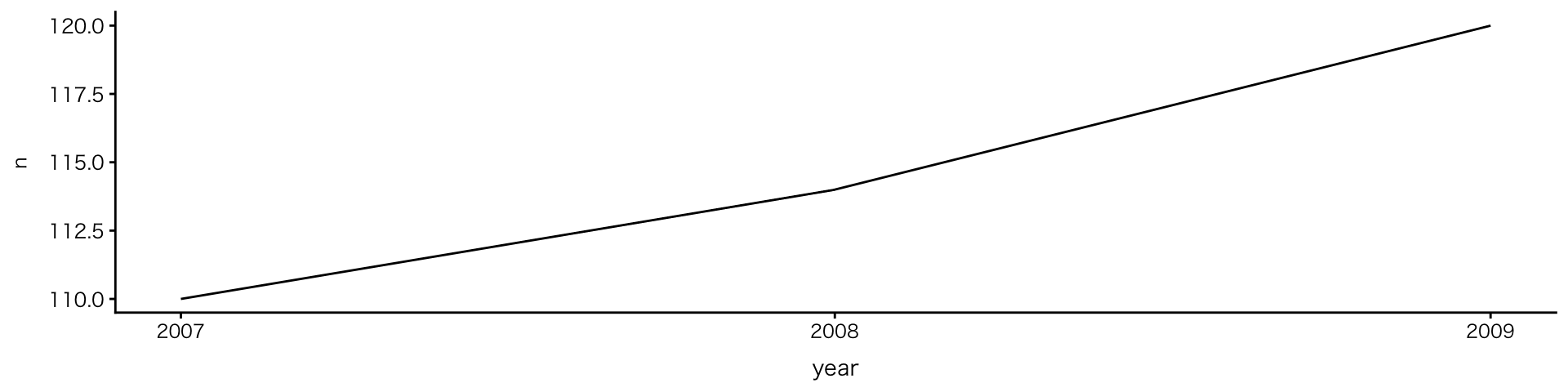
2変数:連続値(または順序) × 数値
折れ線グラフ
geom_line()- 推移の可視化 Cf.
geom_bar():分布の可視化
- 推移の可視化 Cf.
geom_lineで観測数の変化を描く場合、penguinsデータには観測数の列がないため、ggplotに渡す前に計算(count())する必要あり
演習:二変数の作図
完成イメージ
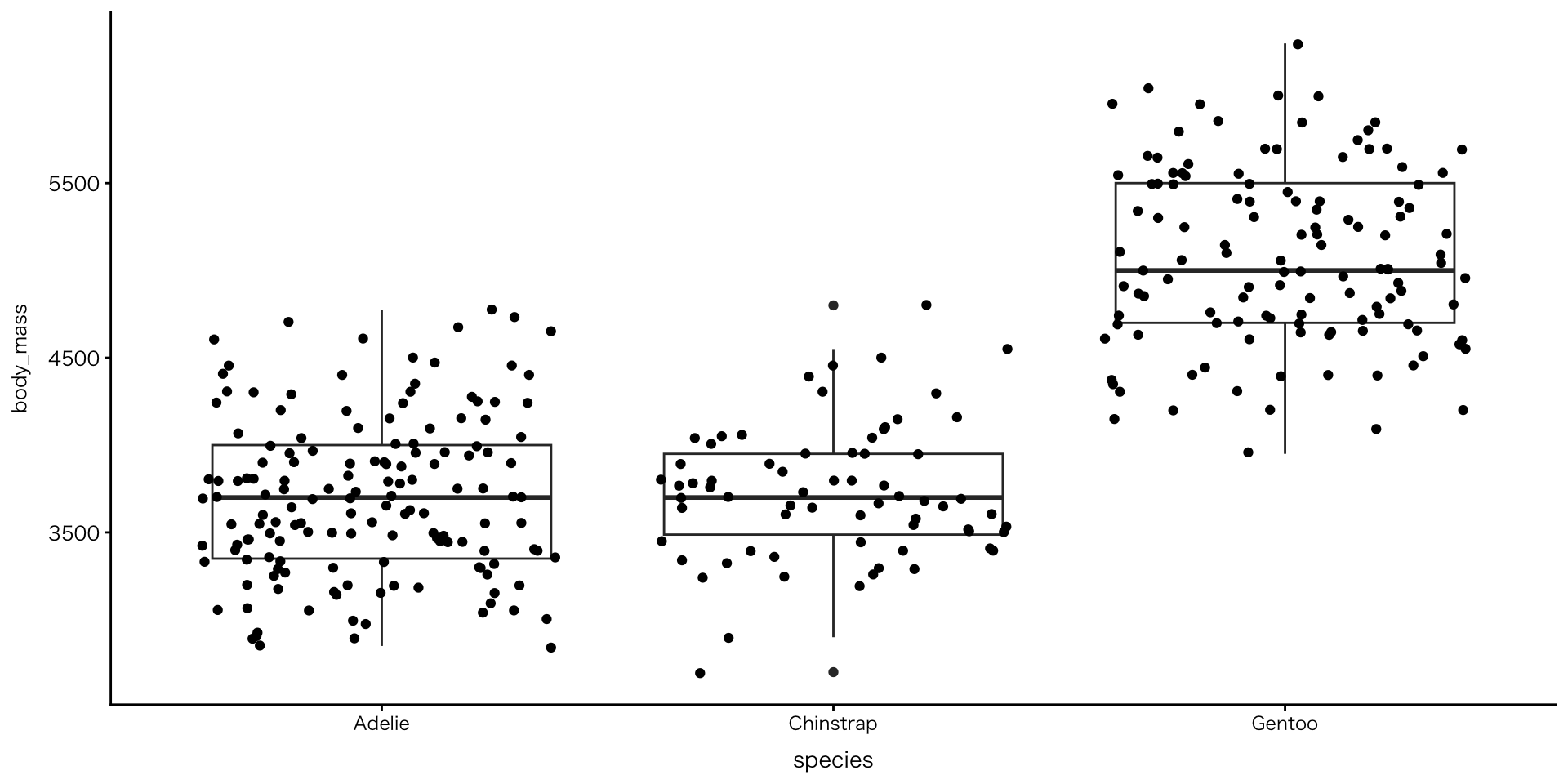
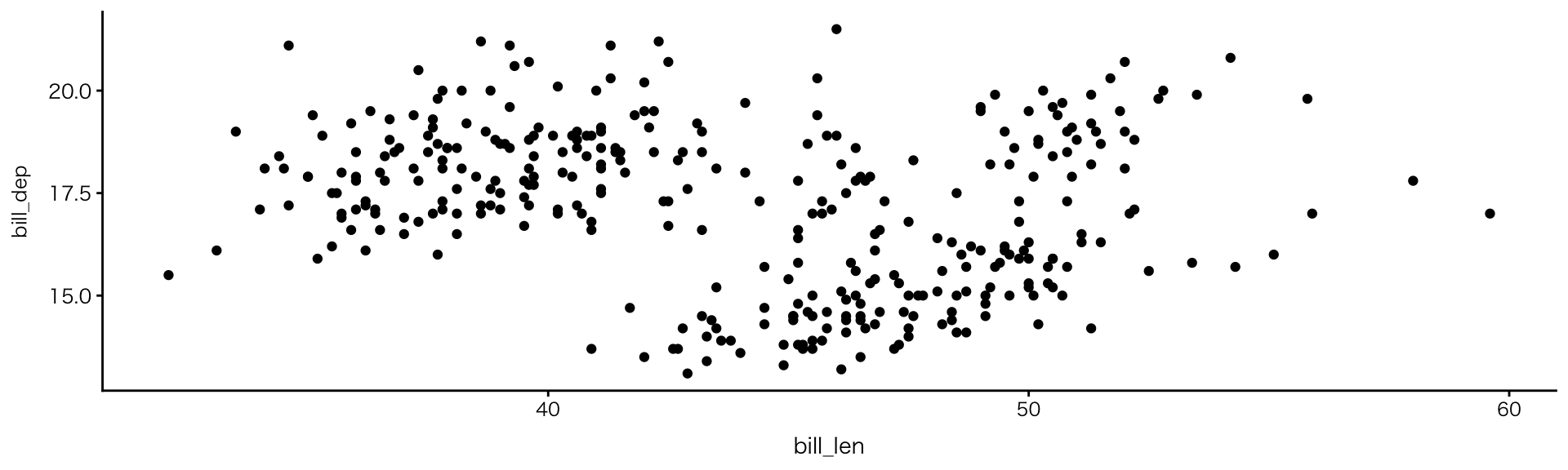
2変数:数値 × 数値
色で区別する:colour(点)の例
geom_point()にcolourを追加
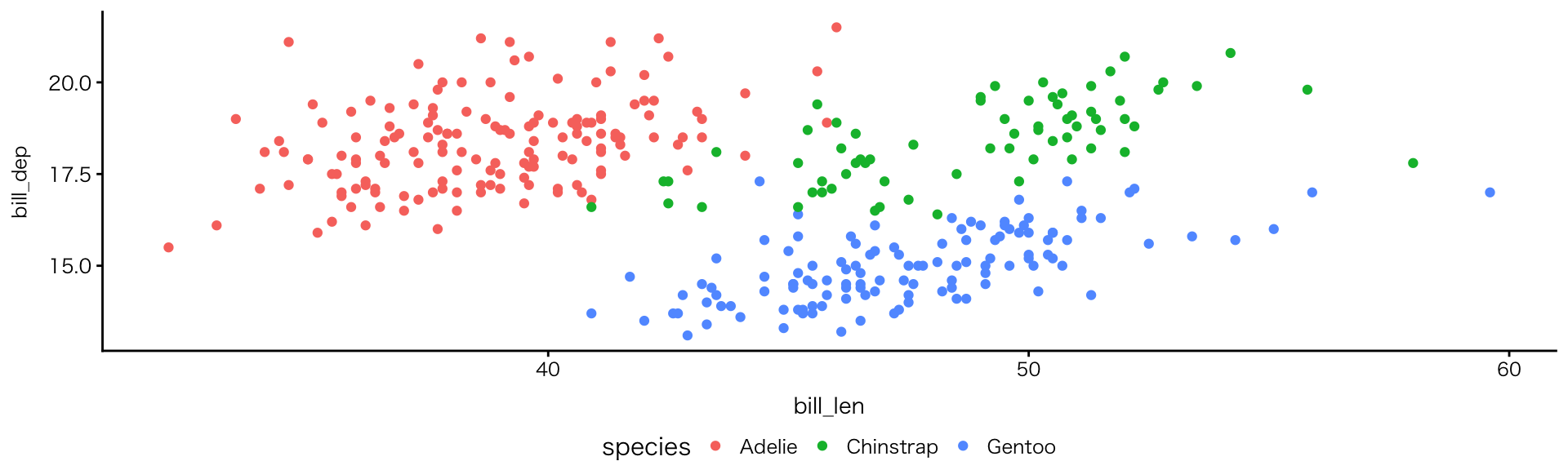
- 種ごとに分布のかたまりがあり、くちばしの形に違いが見られる
多変量:連続値(または順序) × 数値 × カテゴリ
色で区別する:fill(面)の例
geom_histogram()にfillを追加
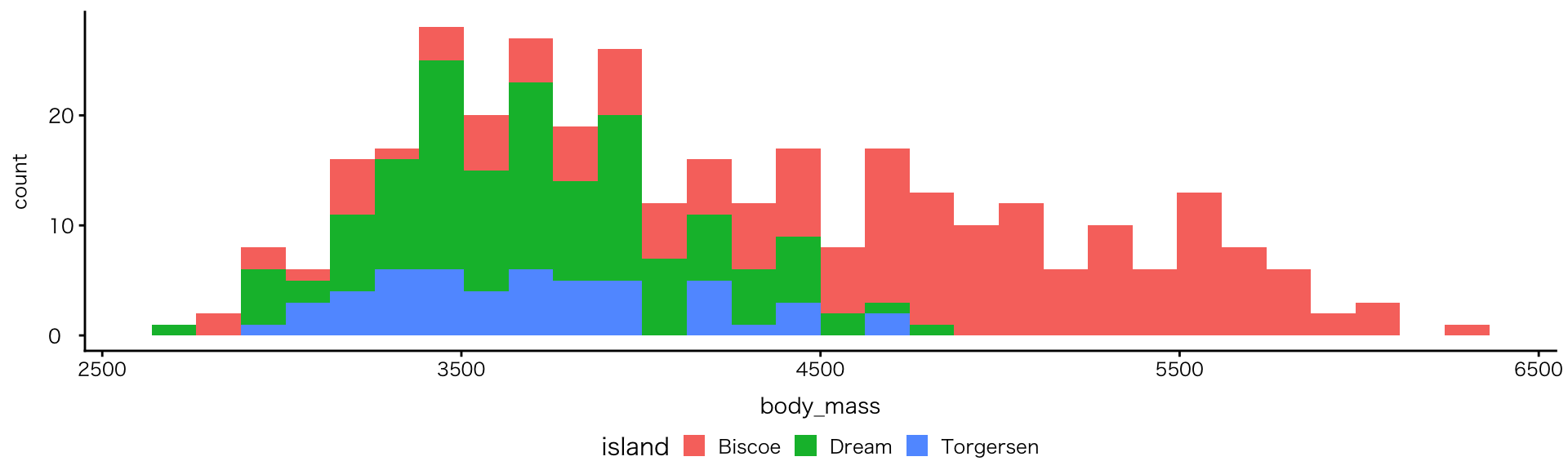
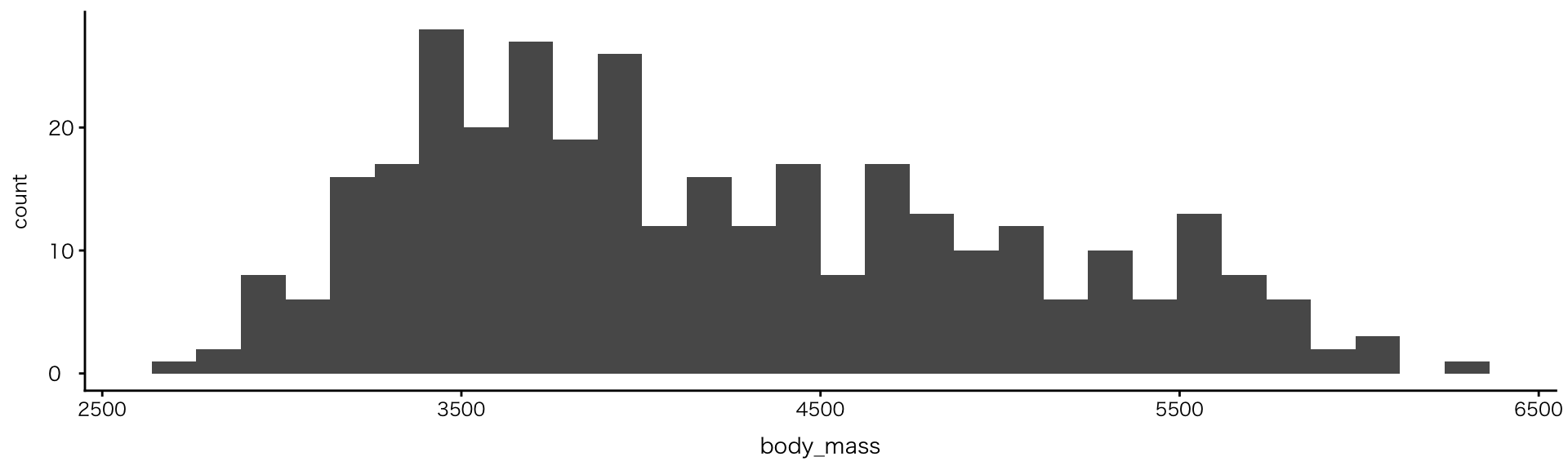
- 種と体重の関係が明確に
多変量:連続値(または順序) × 数値 × カテゴリ
図を分ける:facetの例
geom_histogramにfacetを追加
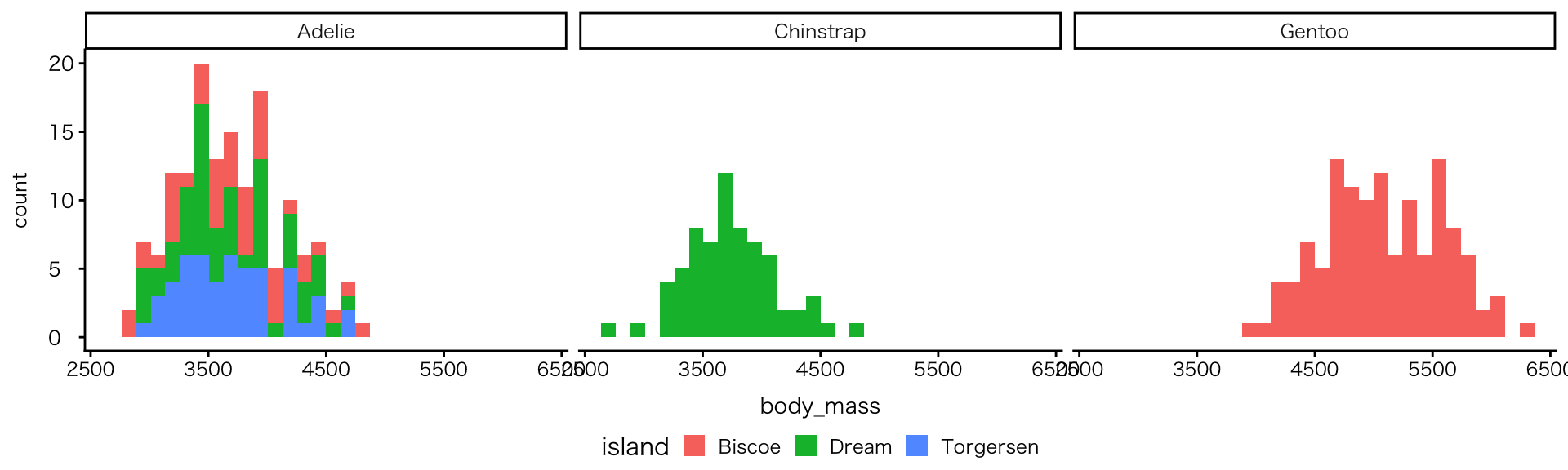
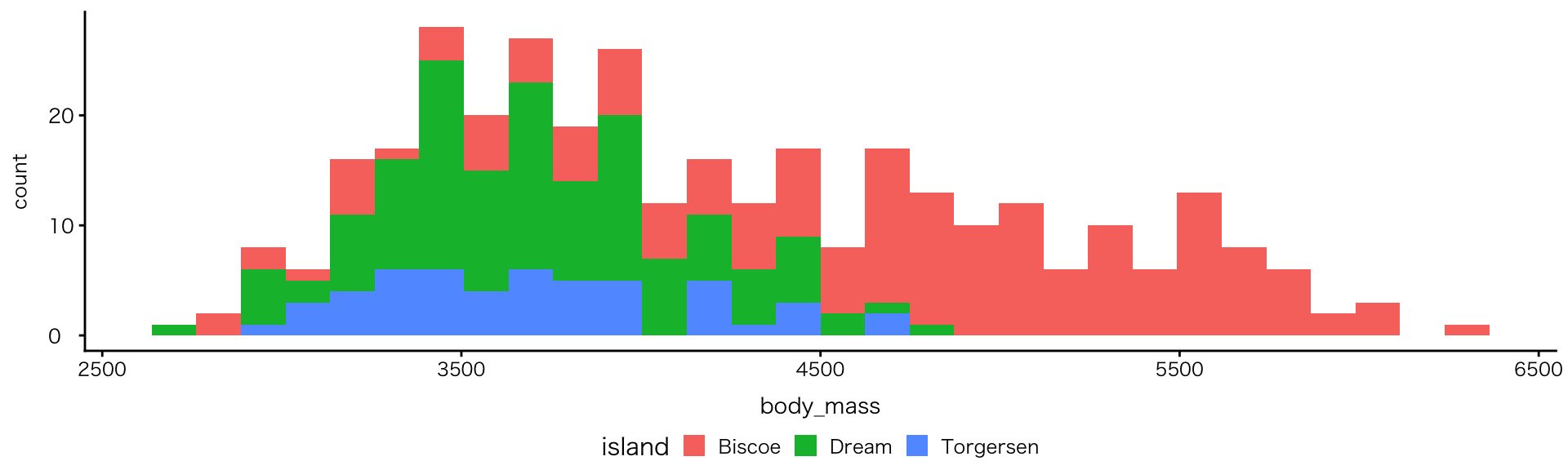
- 種と体重の関係が明確に
多変量:連続値(または順序) × 数値 × カテゴリ
色で区別する:colour(線)の例
geom_line()にcolourを追加
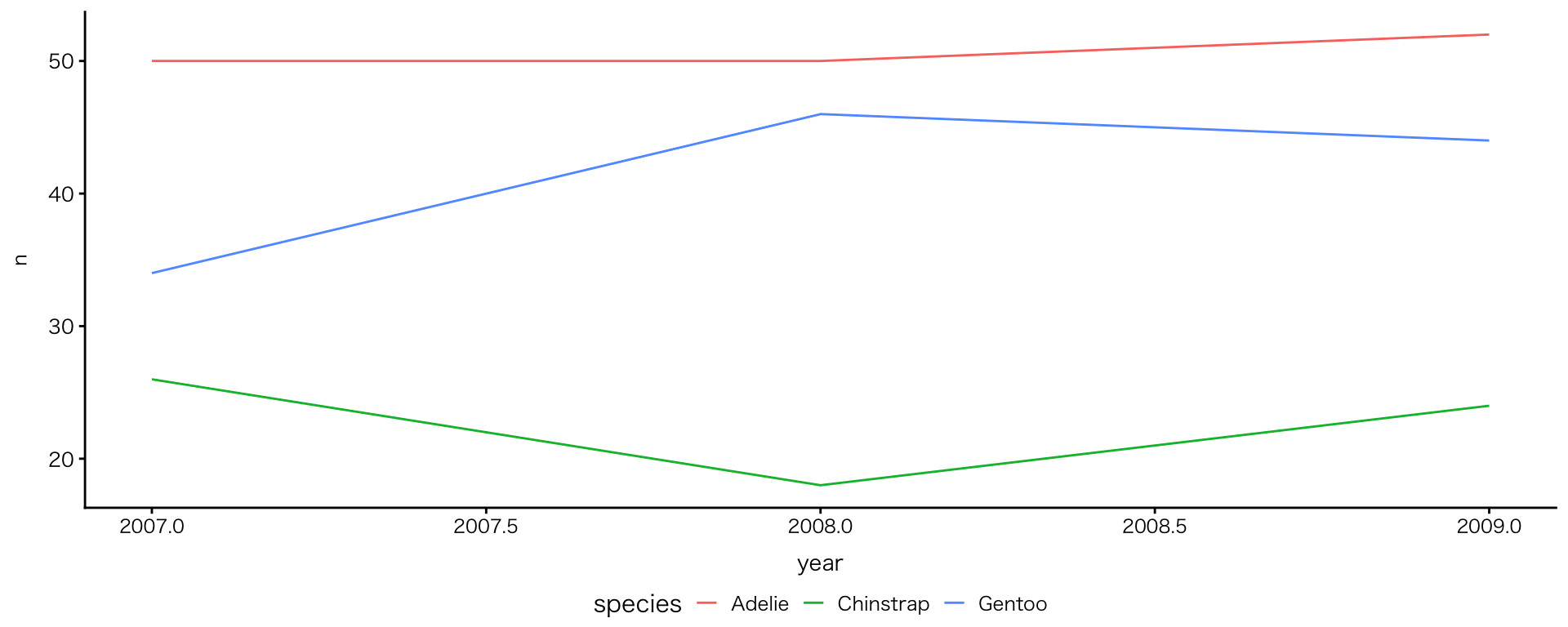
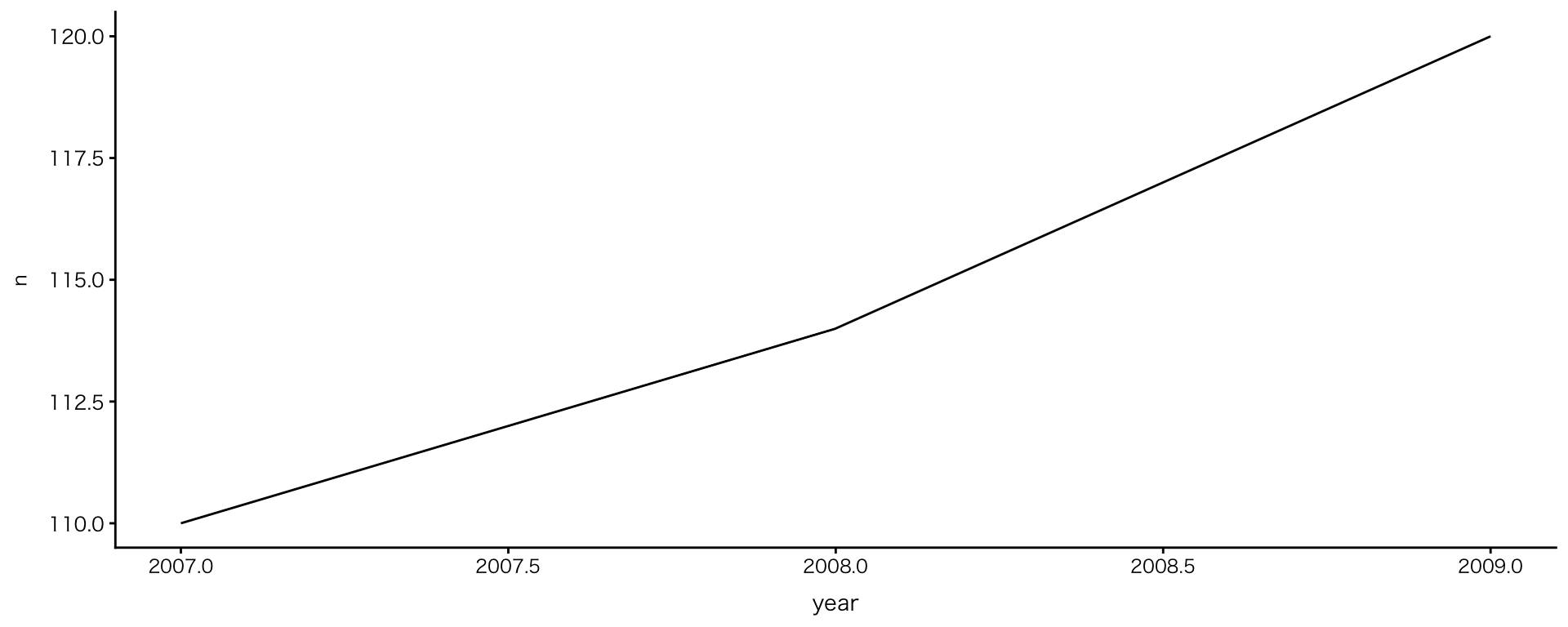
- Adelieの観測数は増えていないことが明らかに
- 2008年に見られる変化は実際の個体数の変化?それとも観測方法などの影響?(問いの浮上)
発展的理解
- facet_gridを使うとさらに変数を加え、情報量を足せる
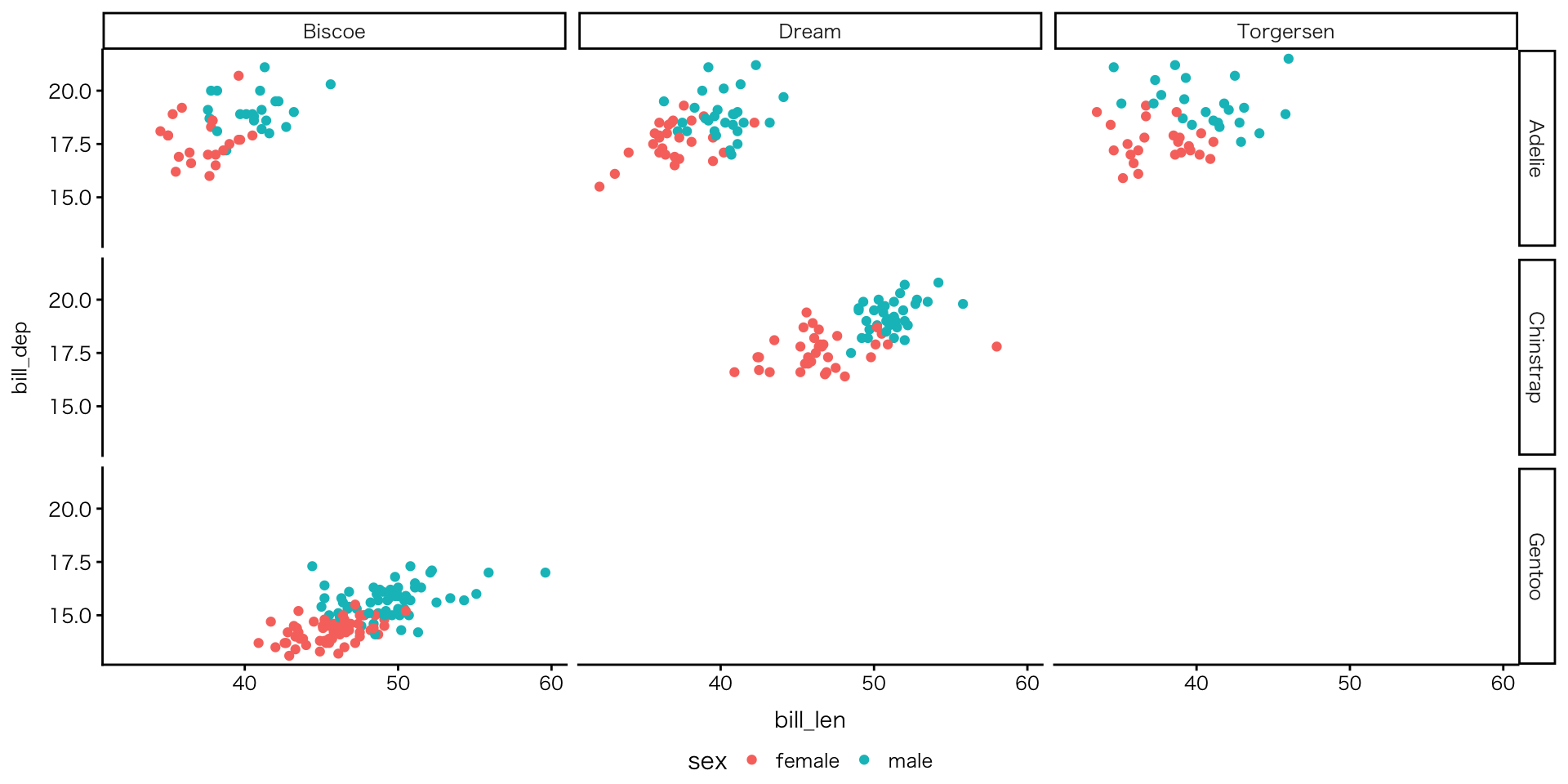
発展的理解
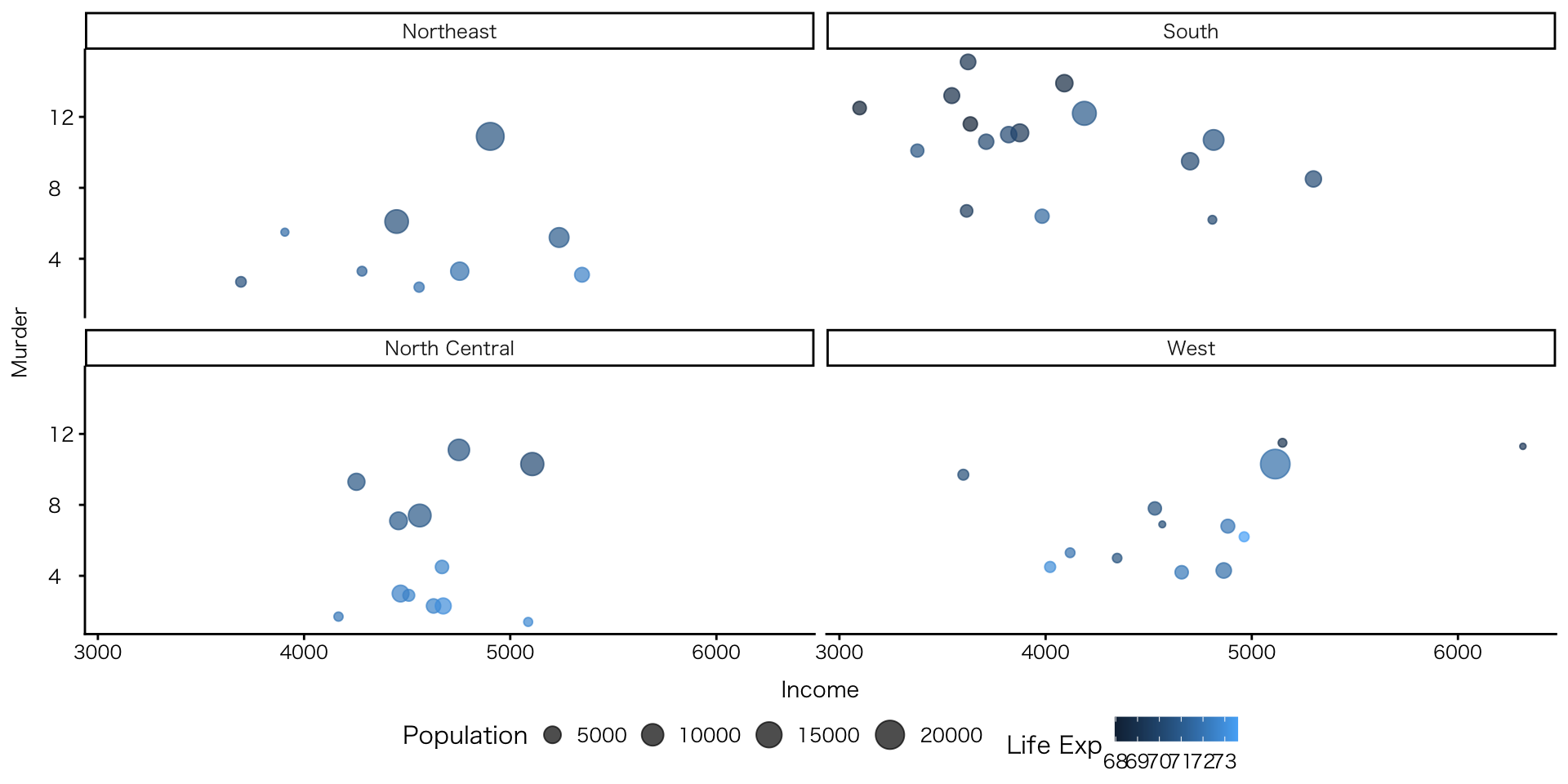
殺人率×収入×地域
- 所得と殺人率の関係は地域によって異なり、さらに平均寿命や人口規模とも関連している可能性があり、これら複数の要因を同時に考える必要があることが視覚的に示されている