| 項目 | 比率 |
|---|---|
| 宿題:授業の感想 | 30 |
| 宿題:演習 | 30 |
| レポート | 20 |
| プレゼンテーション | 10 |
| 受講態度 | 10 |
RとQuartoではじめるデータサイエンス
#8 プレゼンテーションとループ処理
苅谷千尋 
金沢大学
June 3, 2026
ループ処理
指定した列名ごとに同じ処理を繰り返す:vars()
# 可視化したい変数をまとめて指定(この3つを順番に処理する)
vars <- c("body_mass", "bill_len", "flipper_len")
# map():同じ処理を変数ごとに繰り返す(マップ=マッピング=写しとる)
map(vars, \(v) { #map()関数を使って同一処理を指示
penguins |> # タイトルを除くコードは先と同じ
drop_na() |>
group_by(species, sex) |>
summarise(avg = mean(.data[[v]])) |> # 指定した変数 v の平均を計算。data[[v]]:文字列で指定した列名を使う書き方(ここが少し特殊)
ggplot(aes(x = species, y = avg)) +
geom_col() +
facet_wrap(~ sex) +
labs(title = paste("Average of", v)) # varsからタイトルを持ってくる
})[[1]]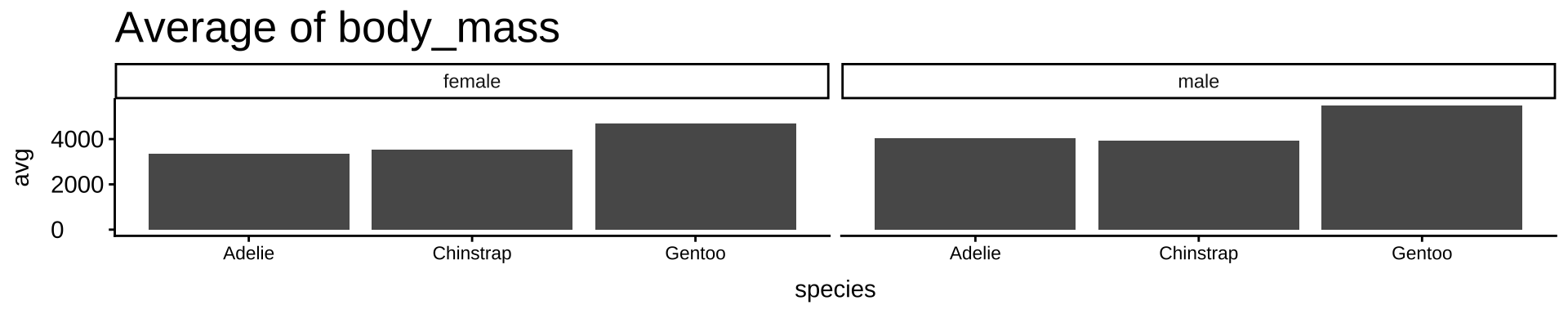
[[2]]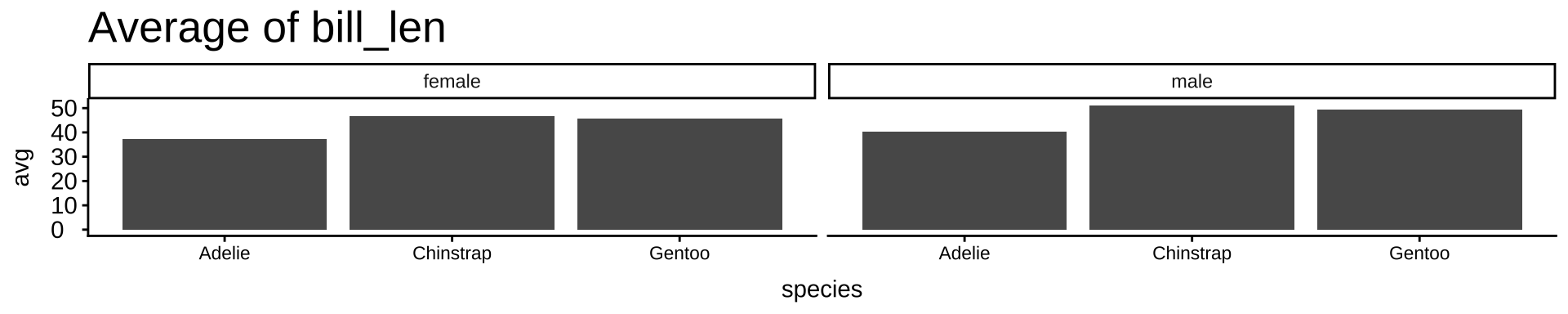
[[3]]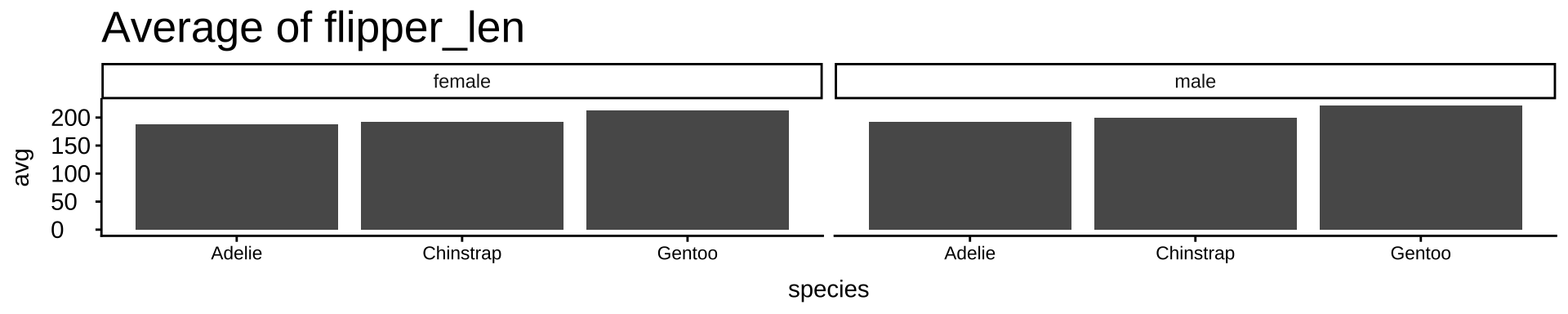
ループ処理
データをグループごとに分けて繰り返す:nest()



ループ処理
データをグループごとに分けて繰り返す:split()
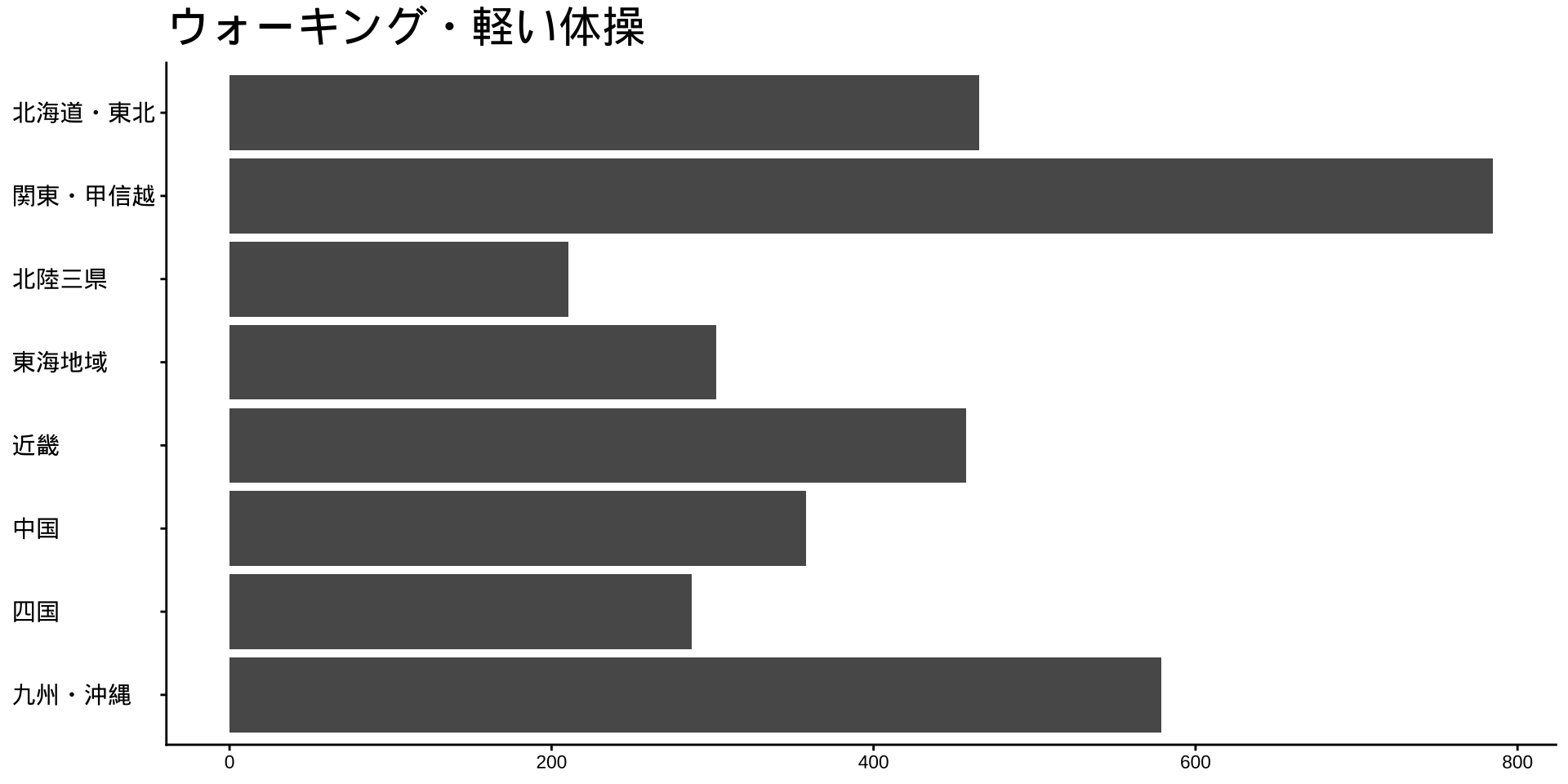
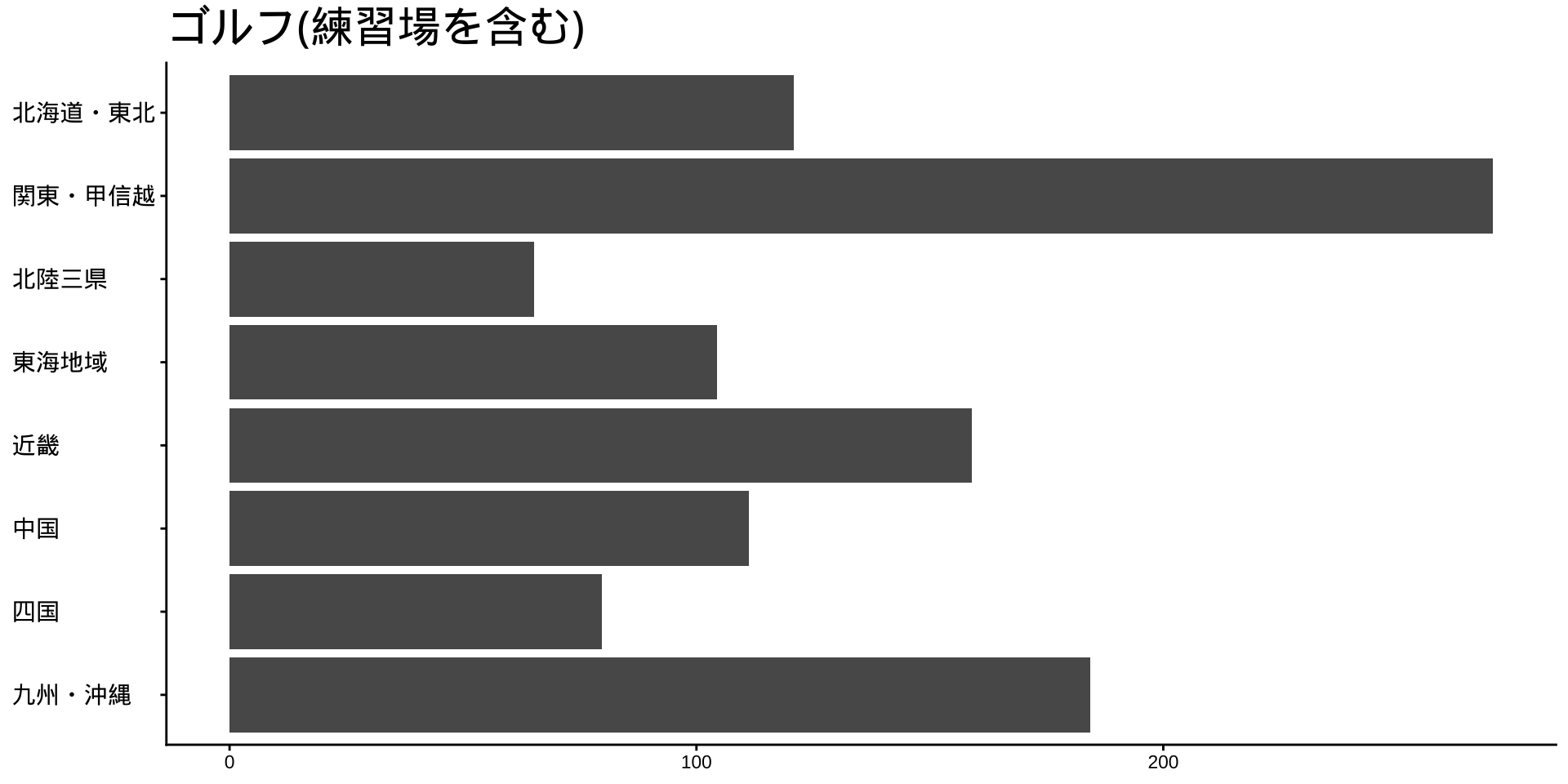
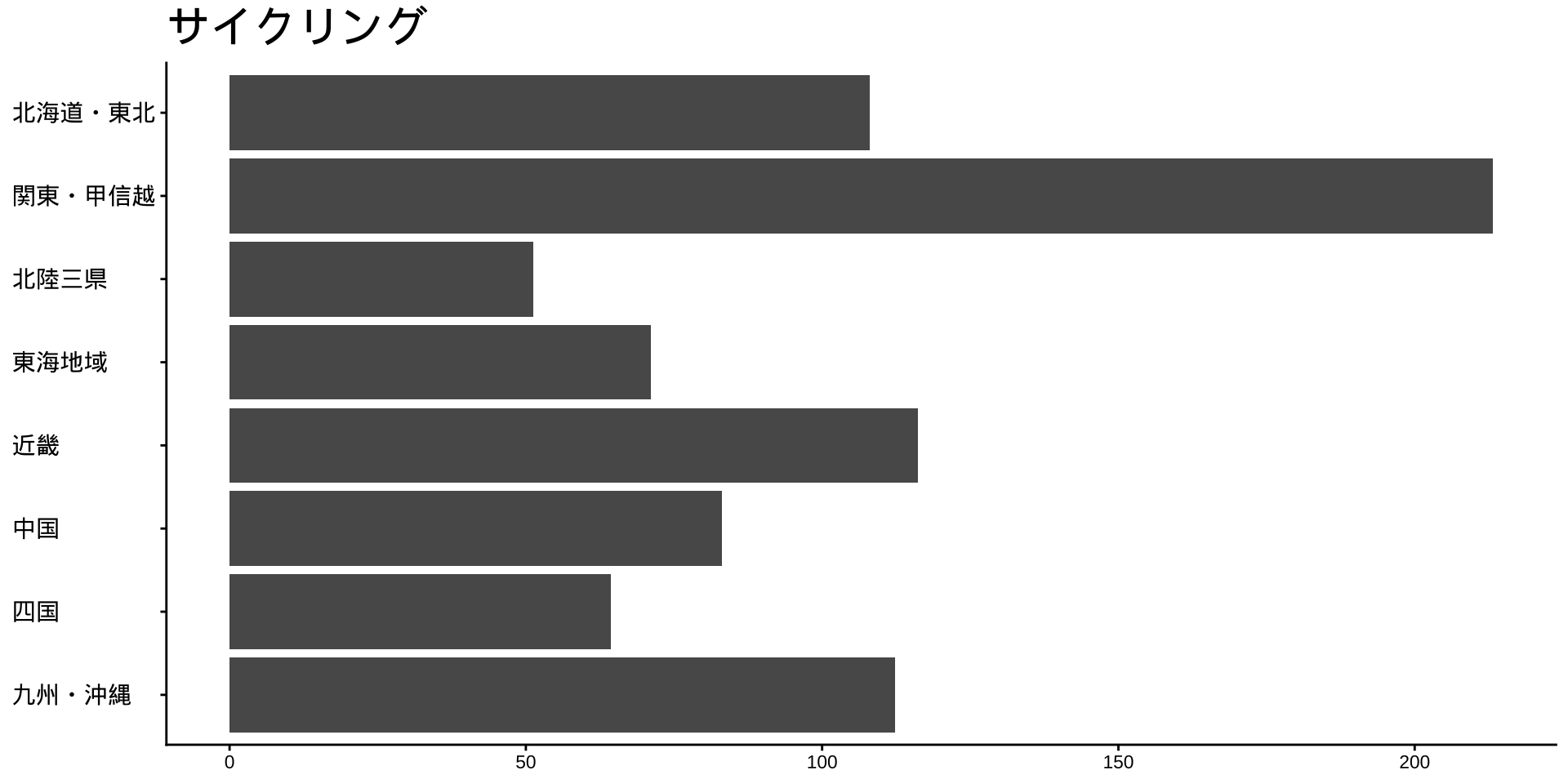
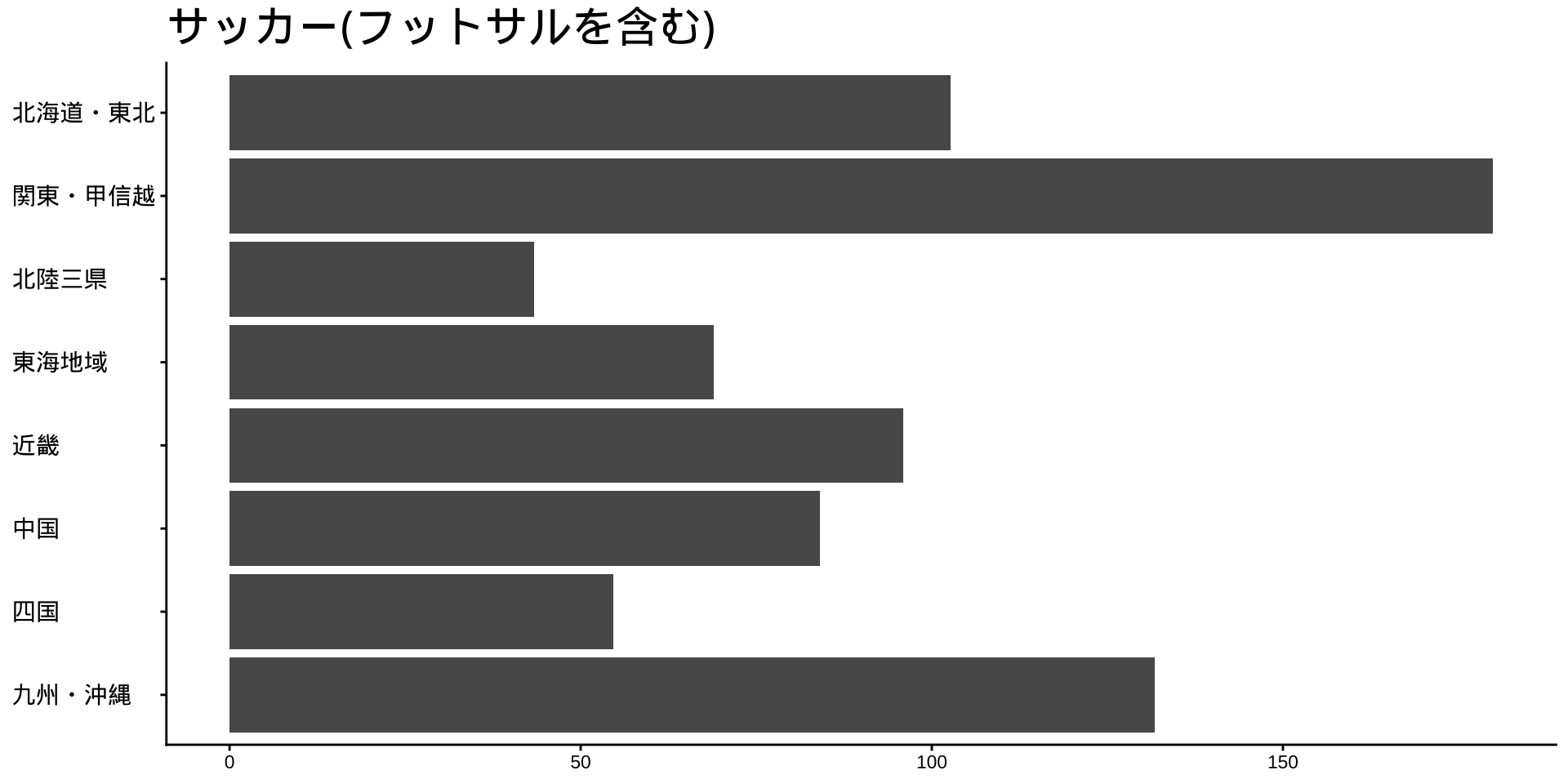
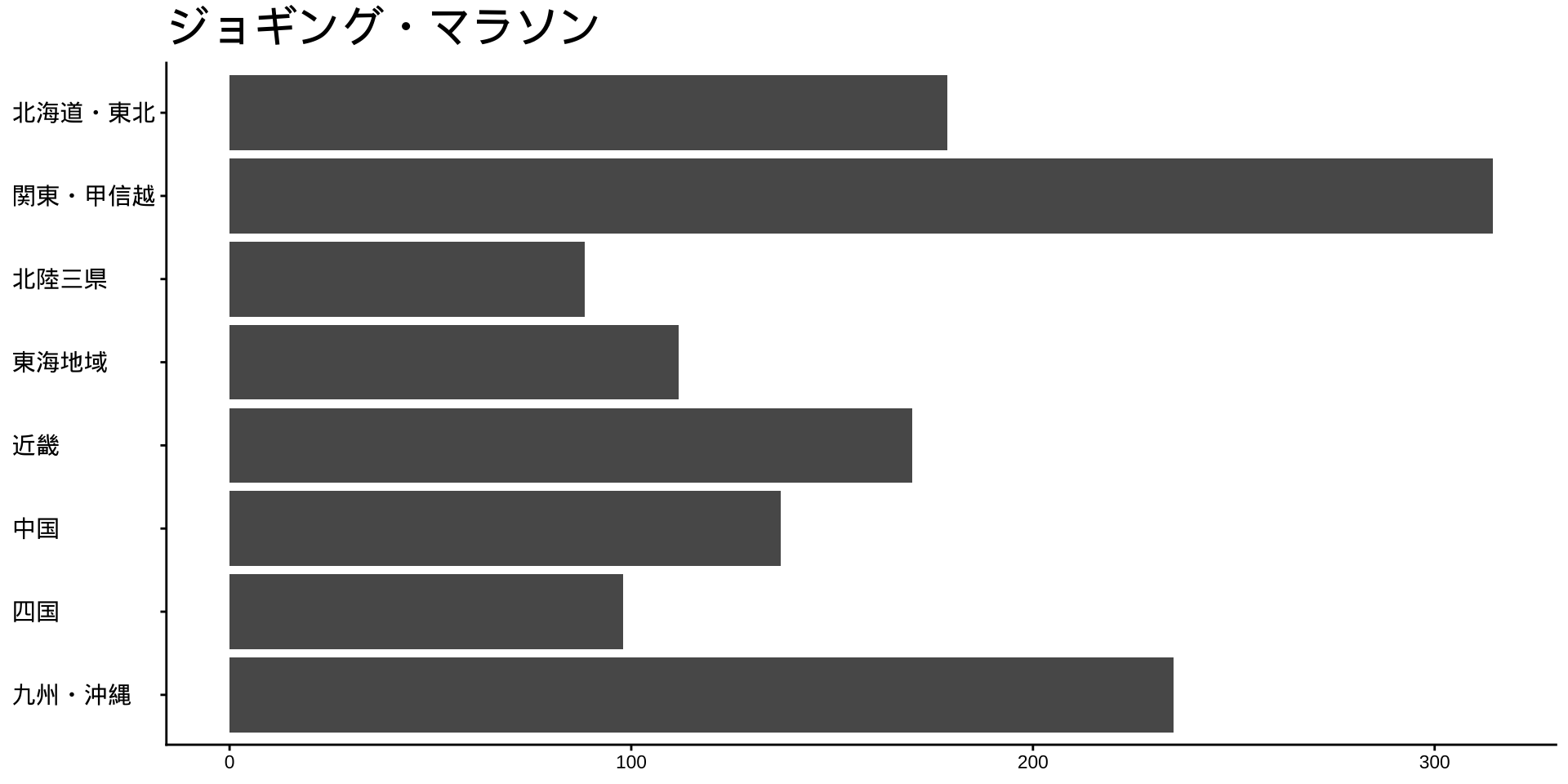
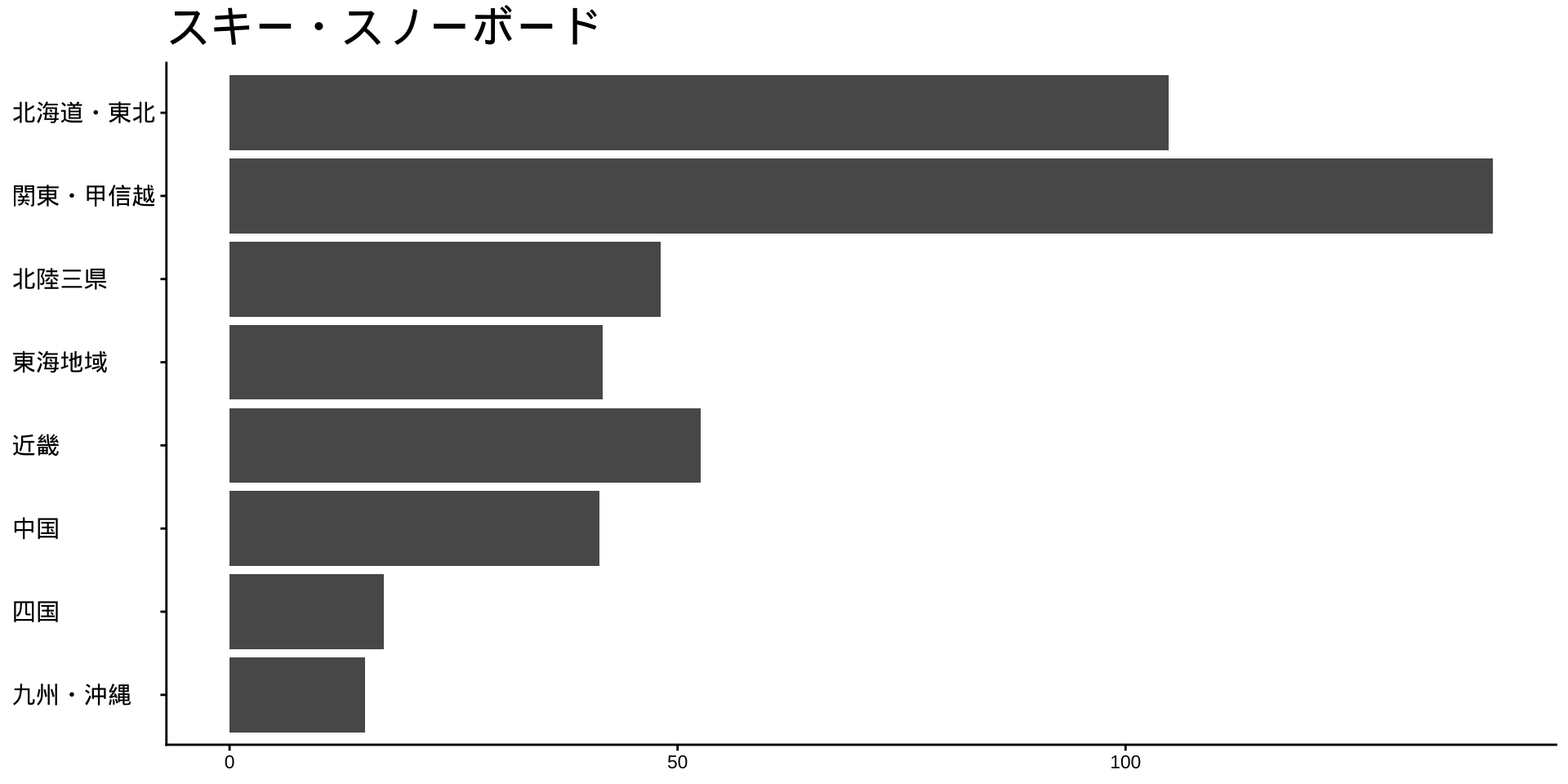
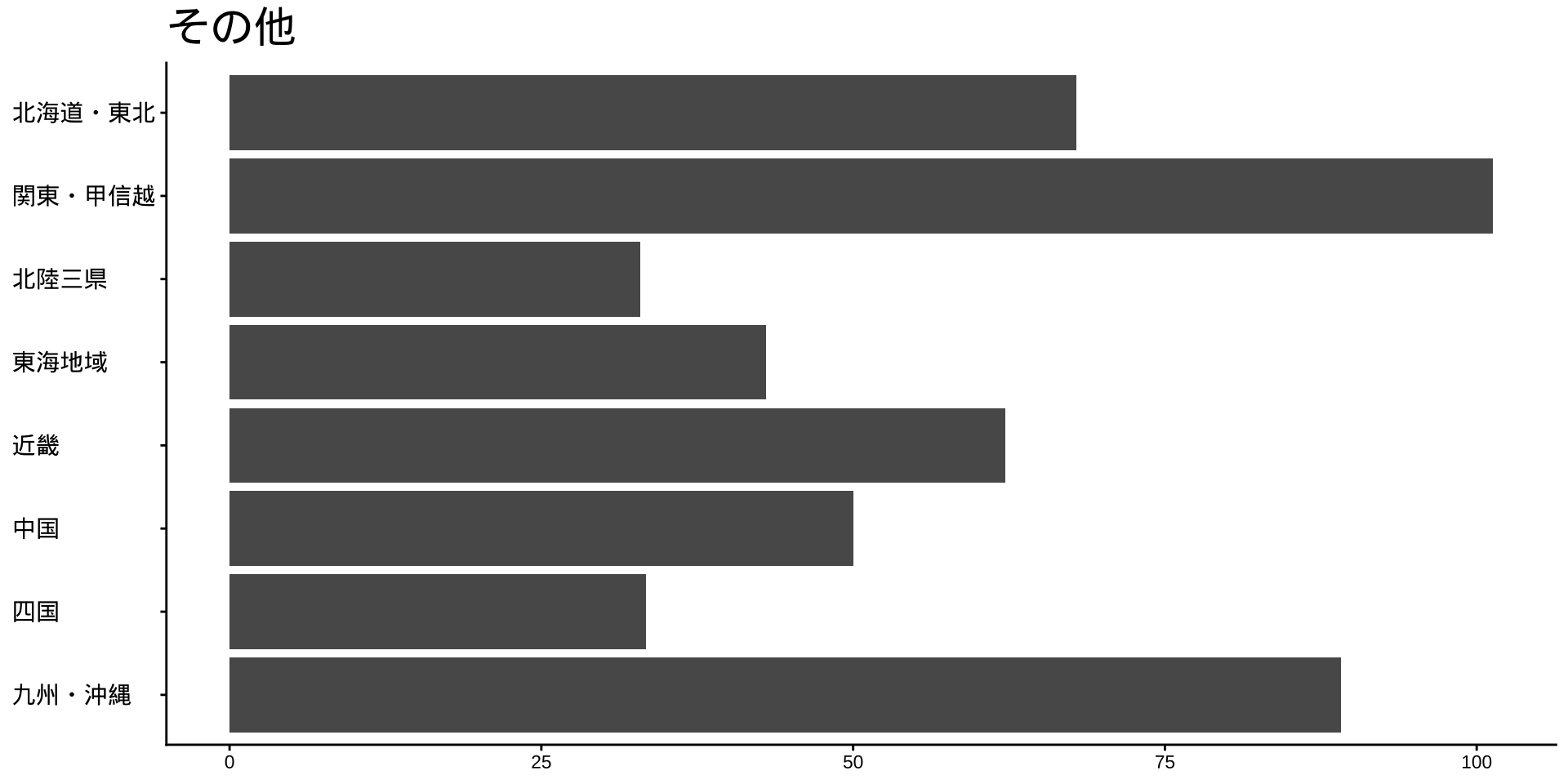
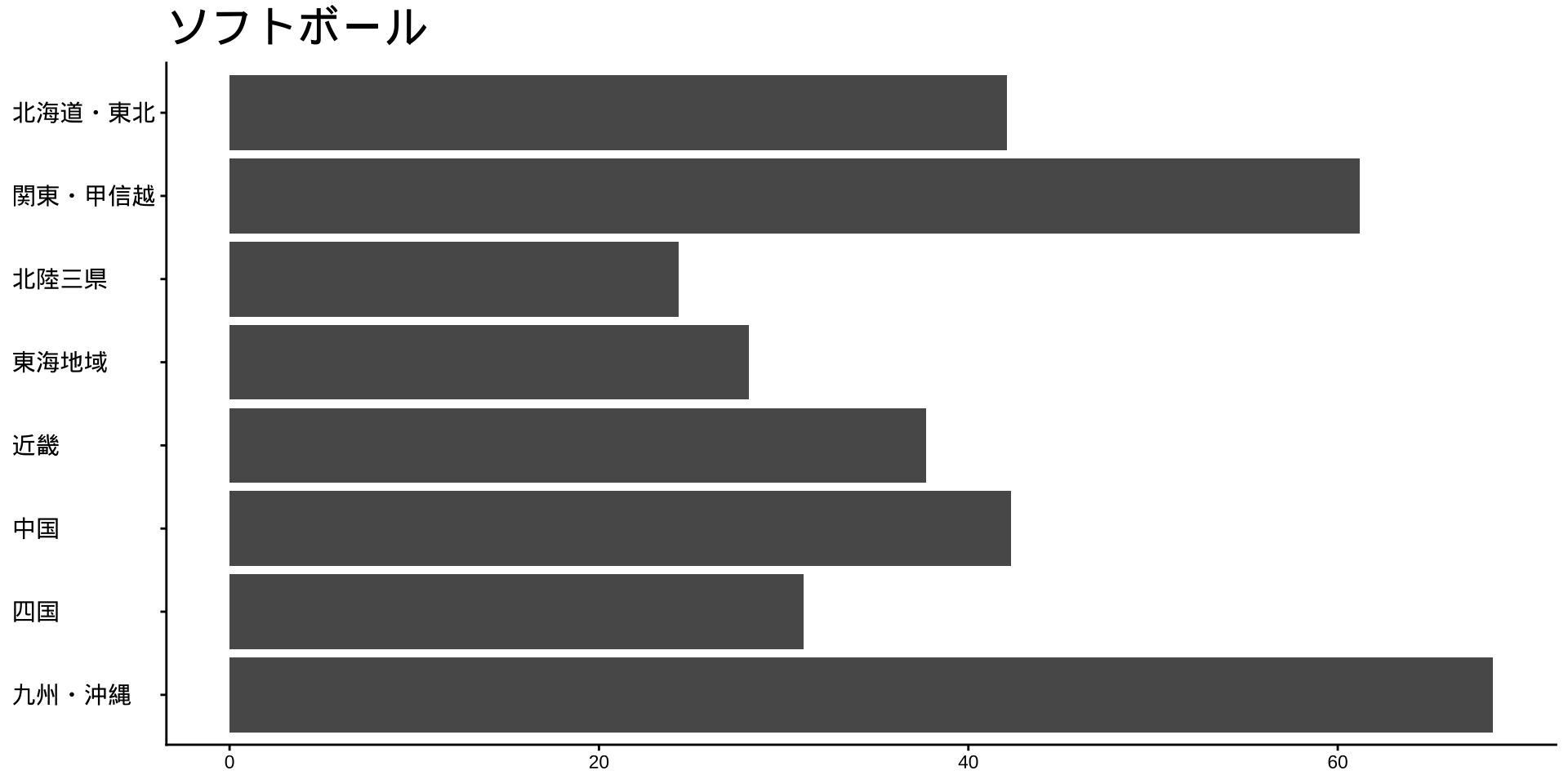
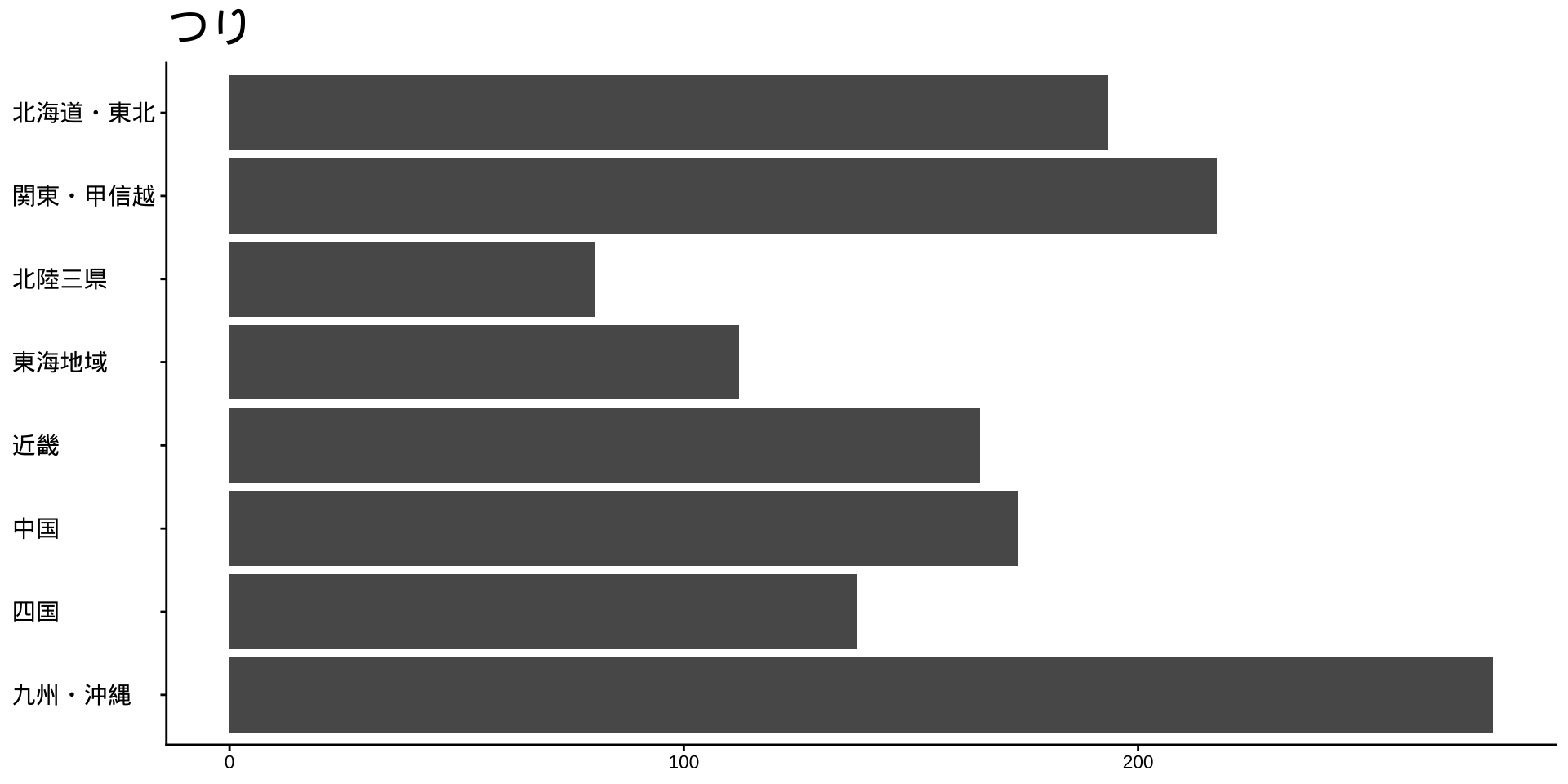
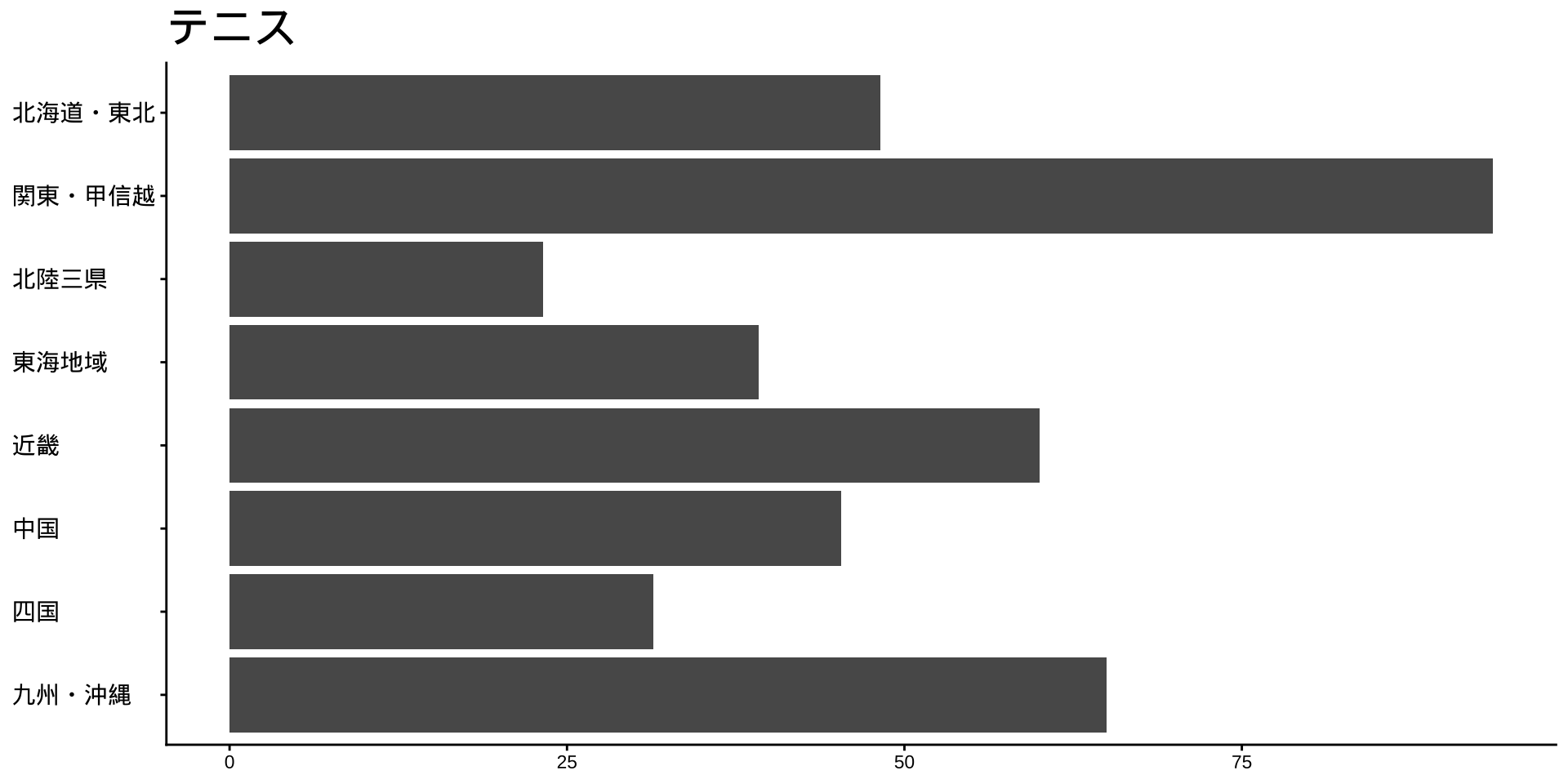
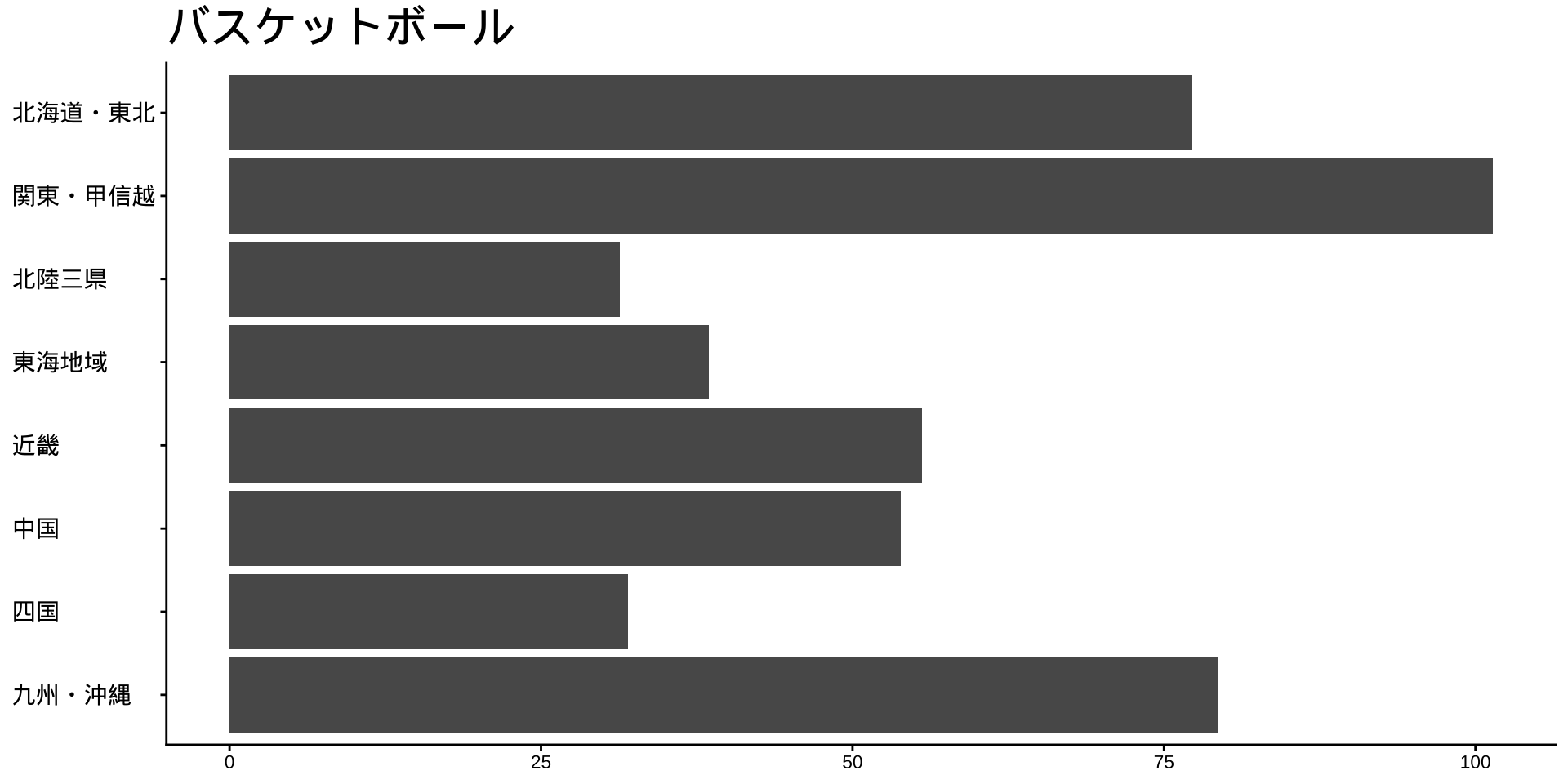
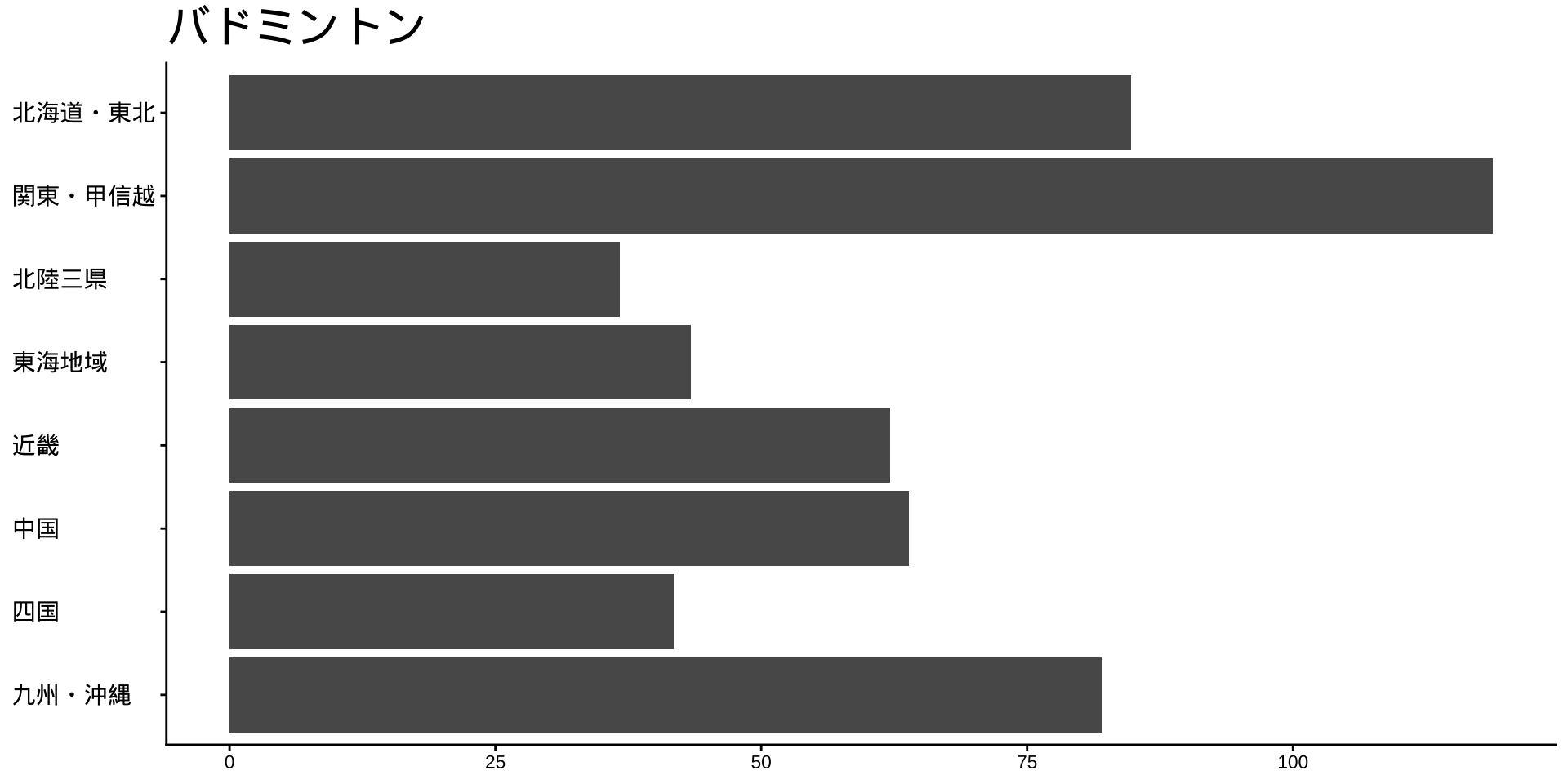
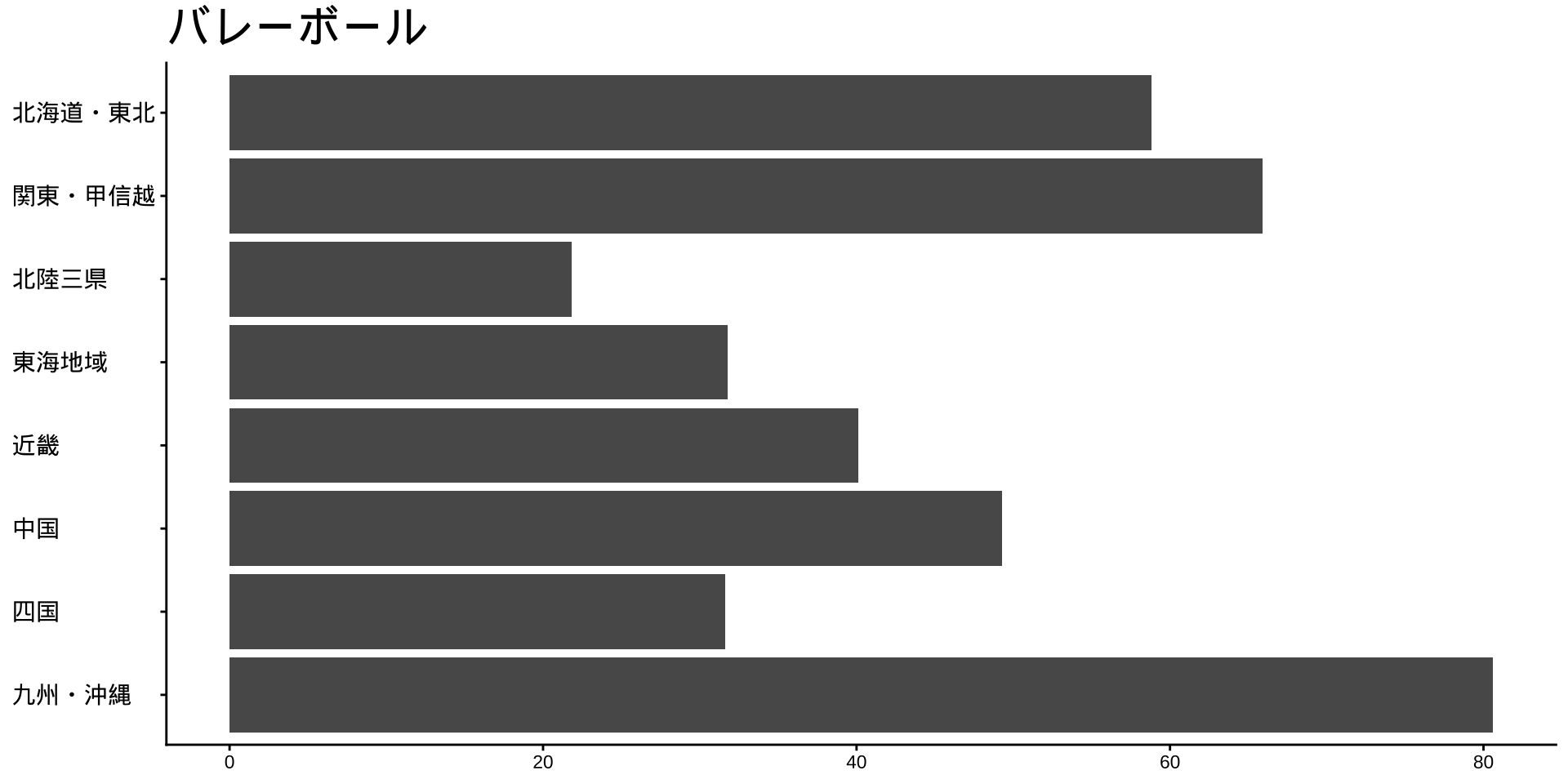
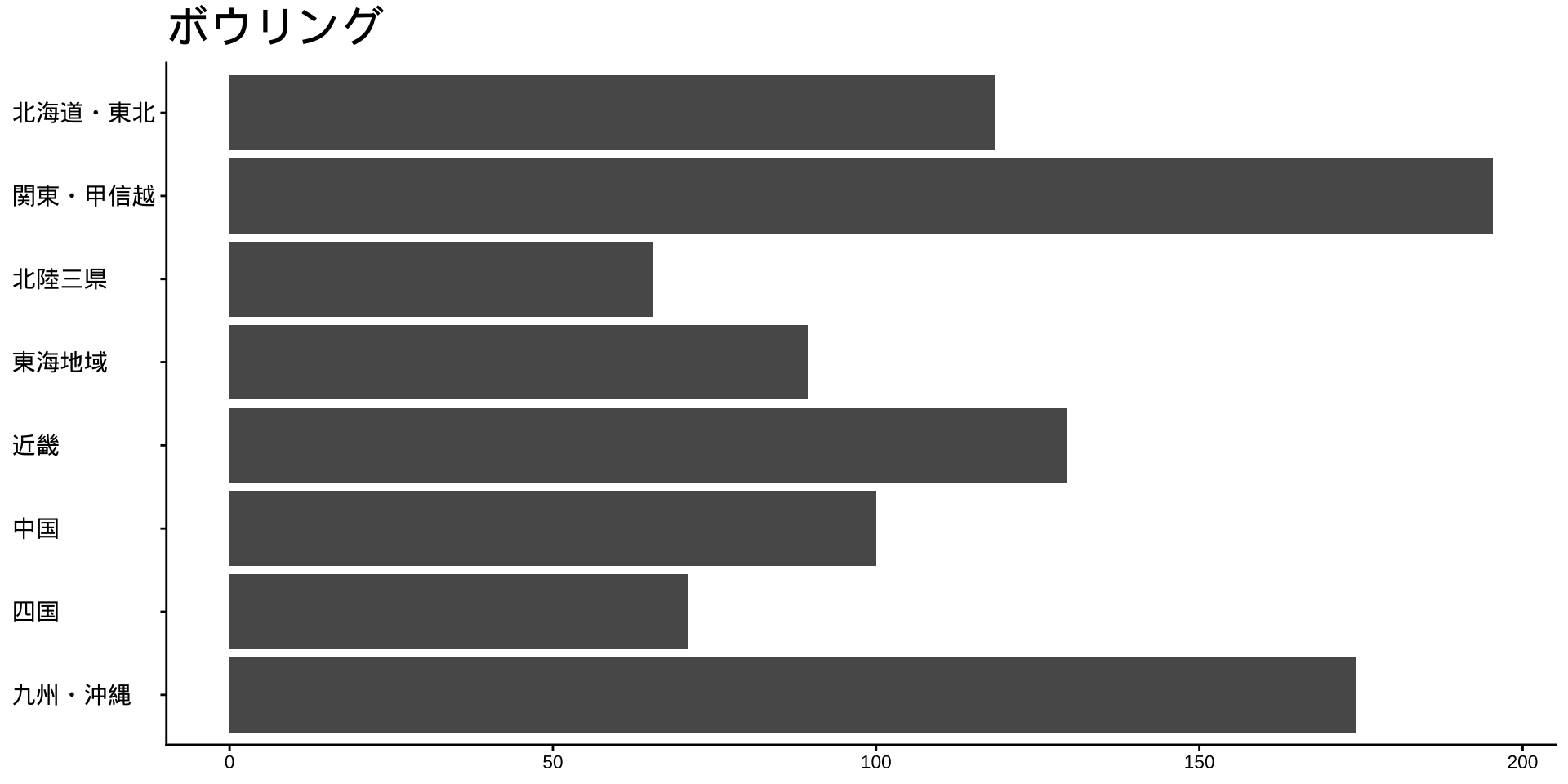
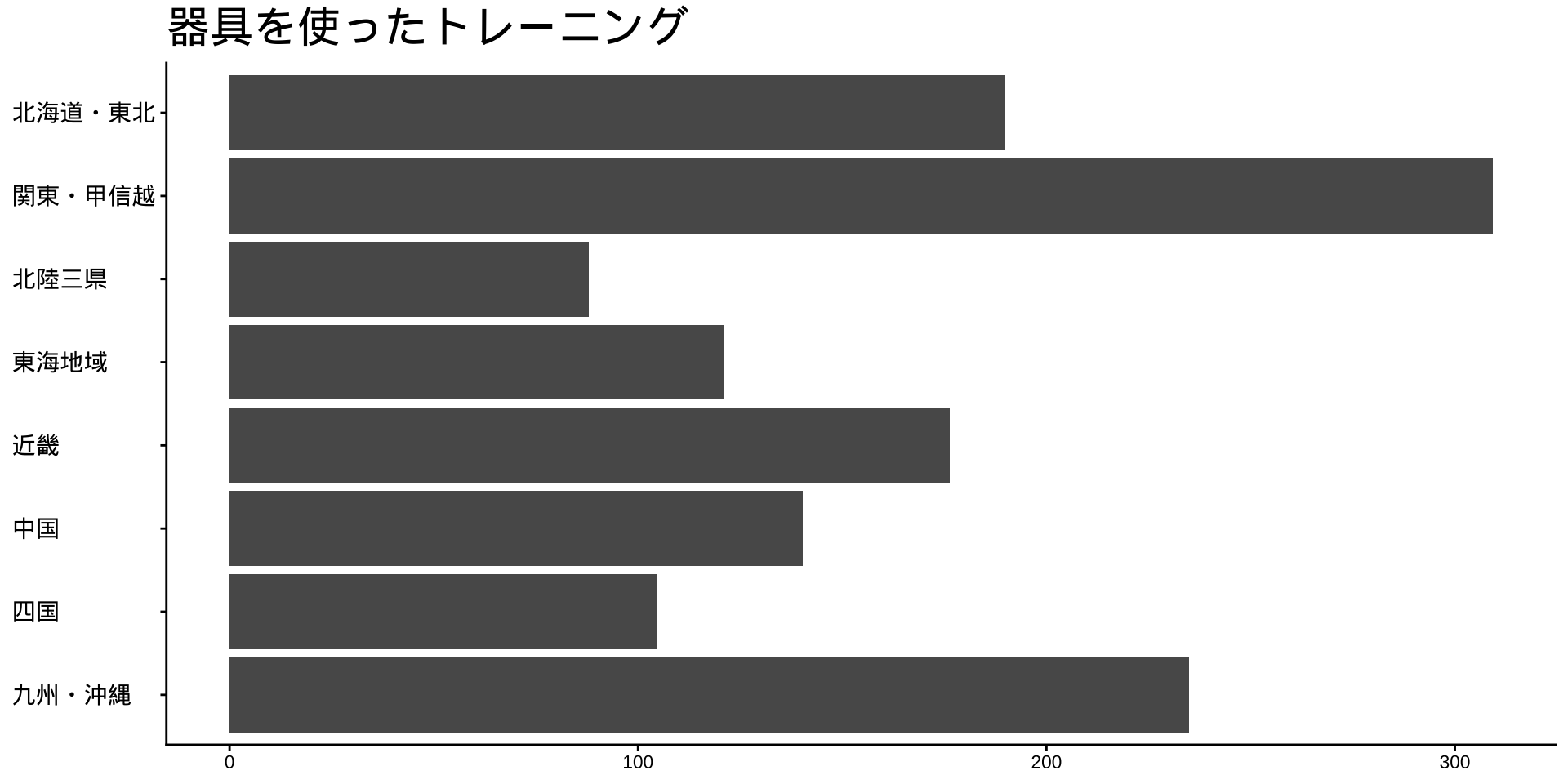
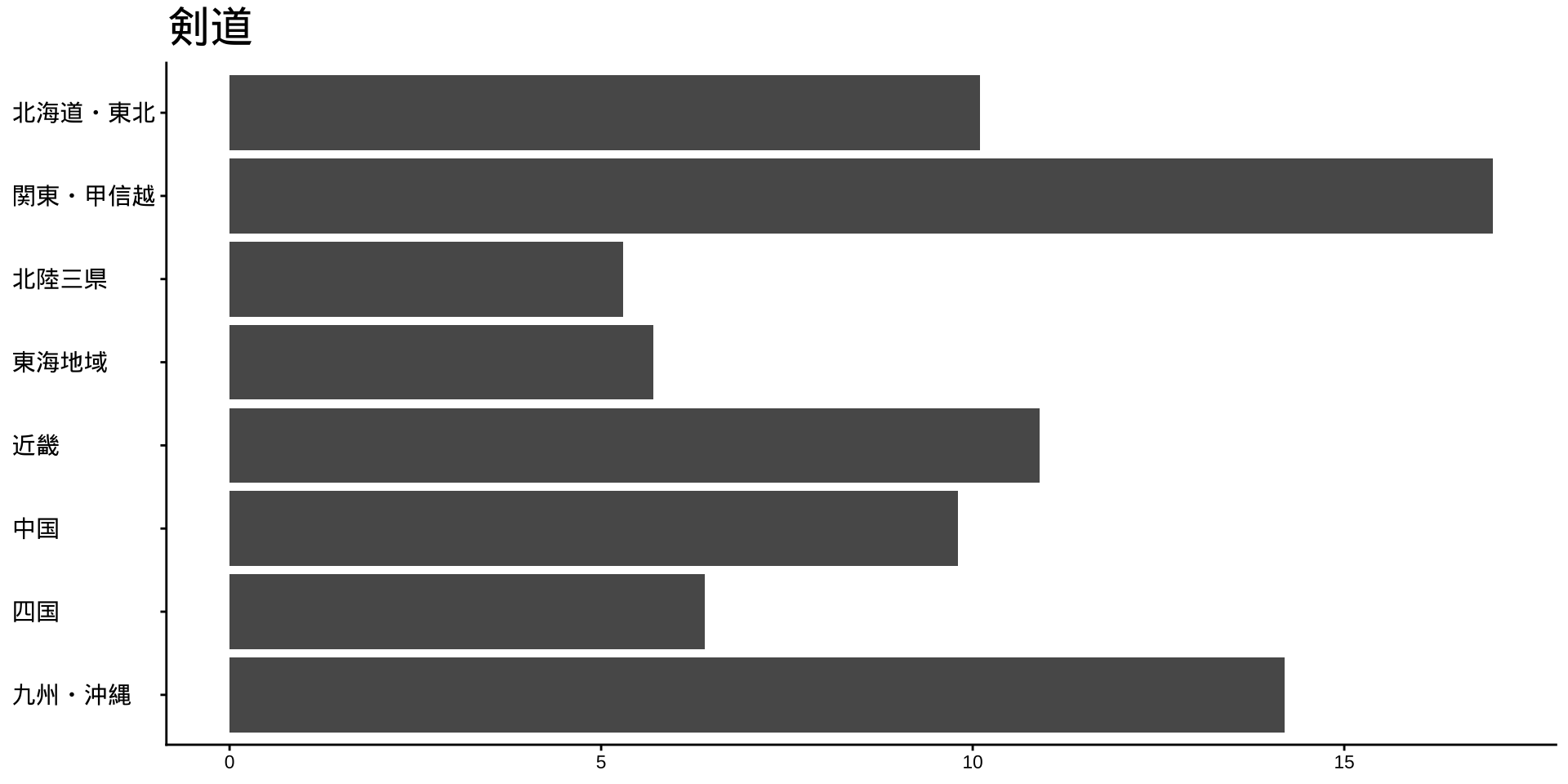
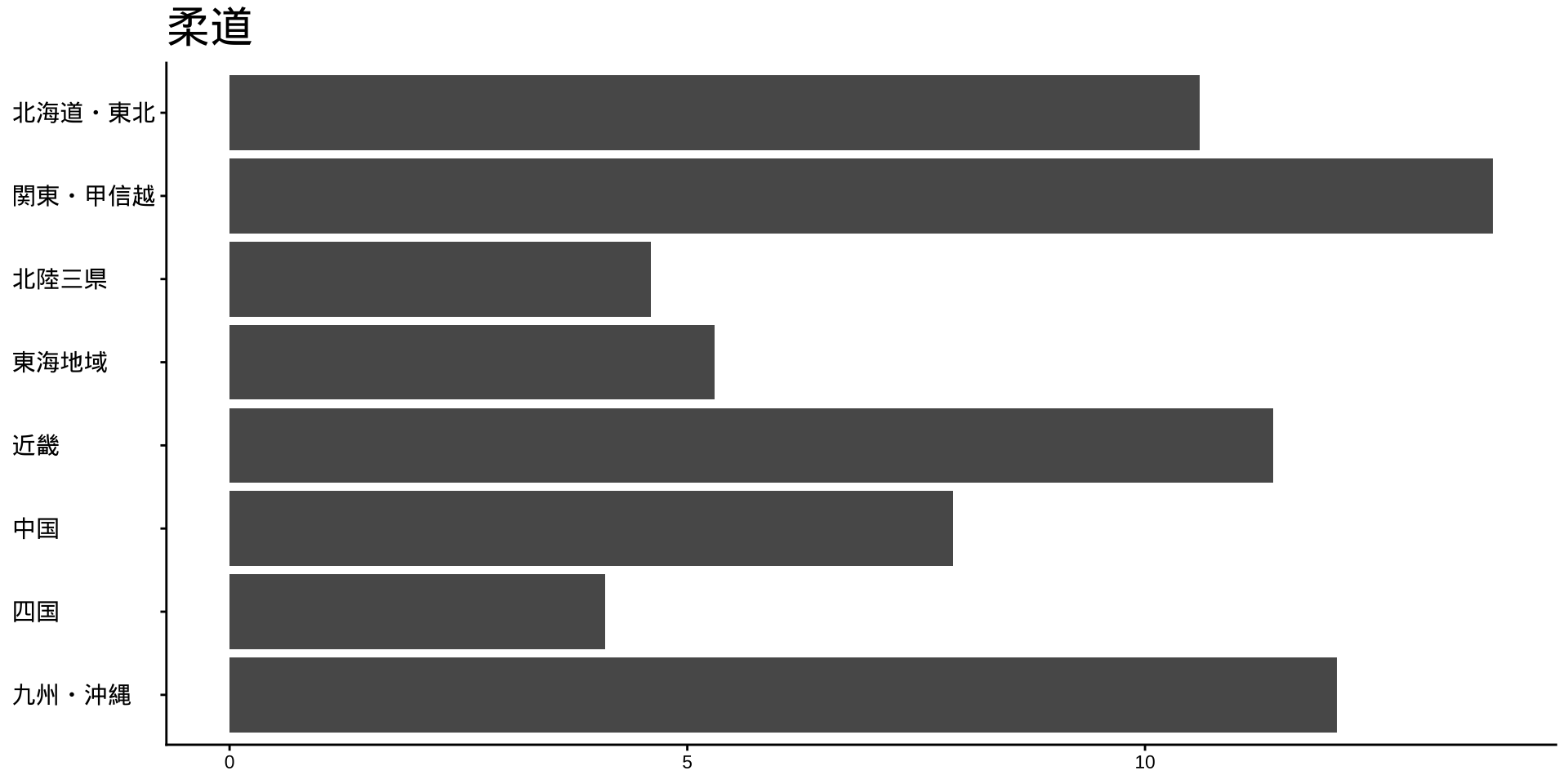
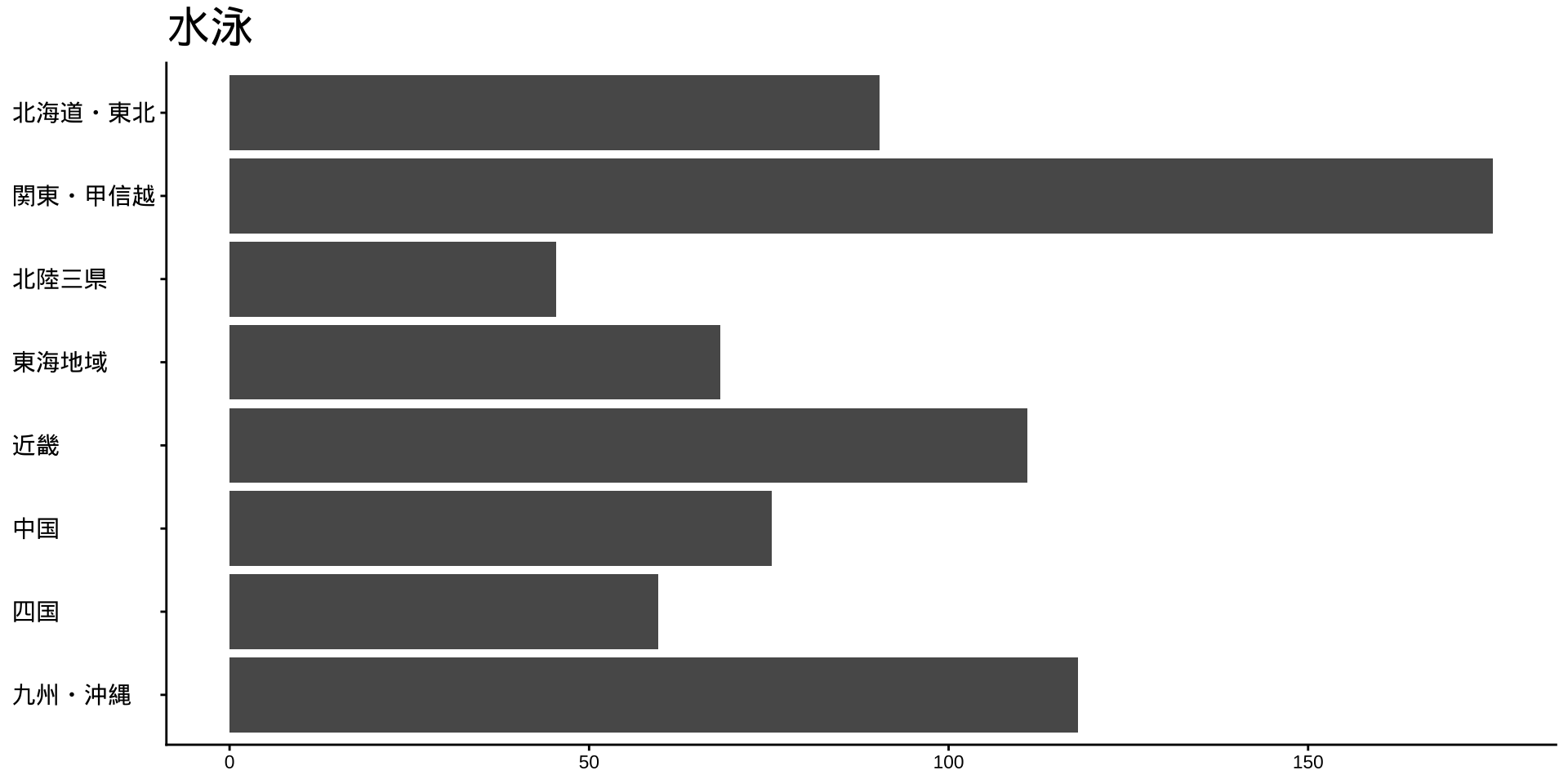
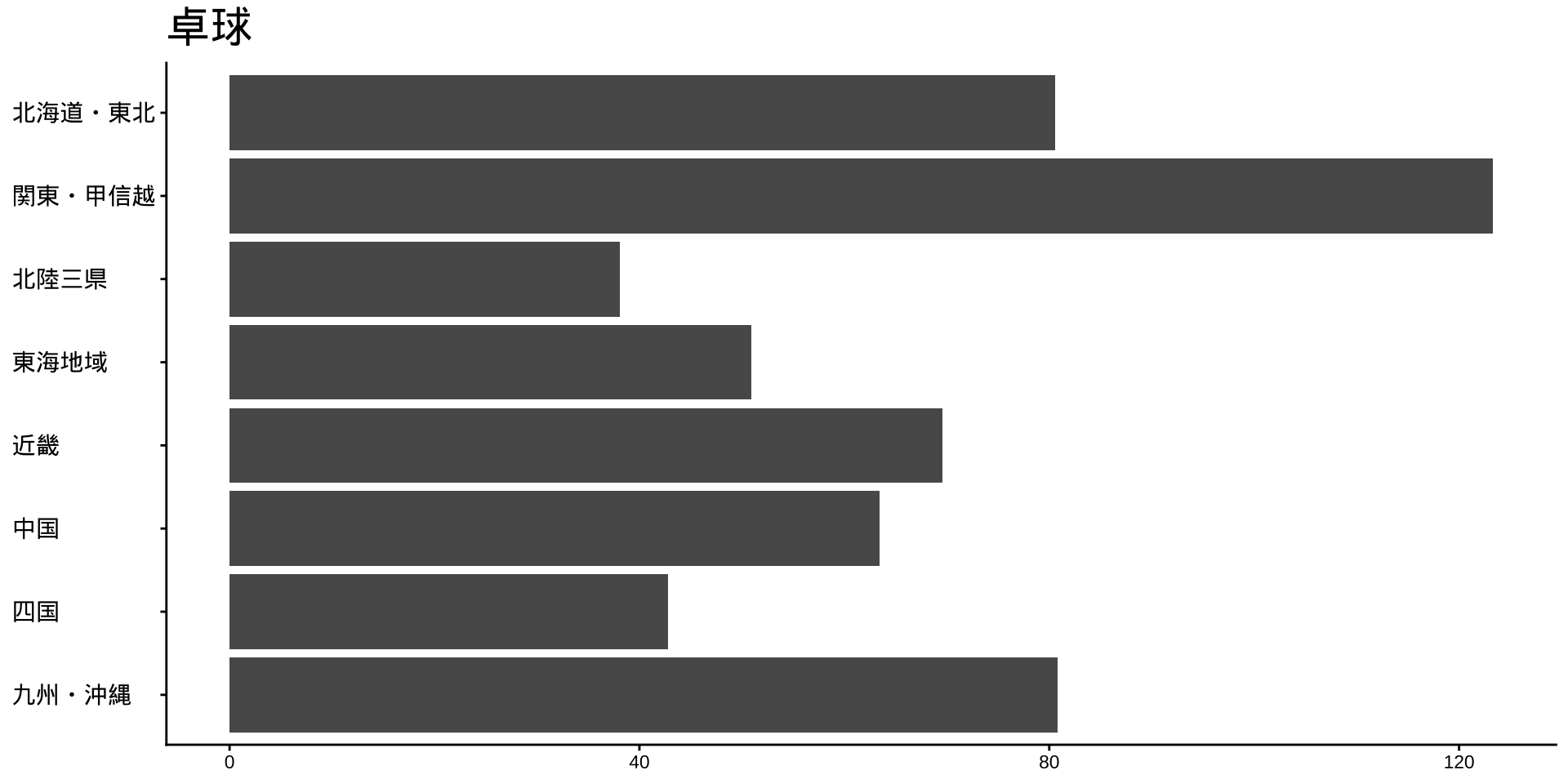
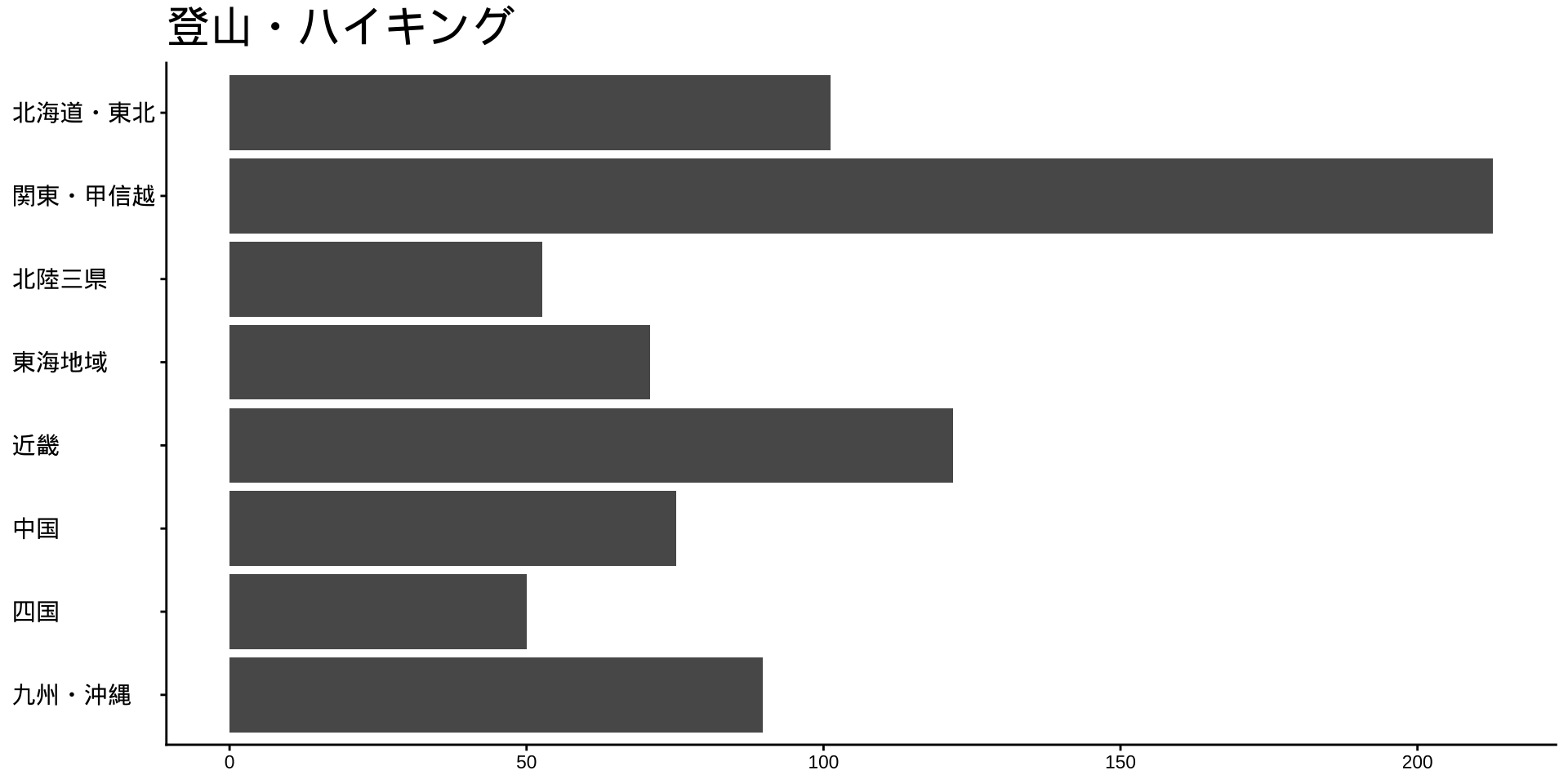
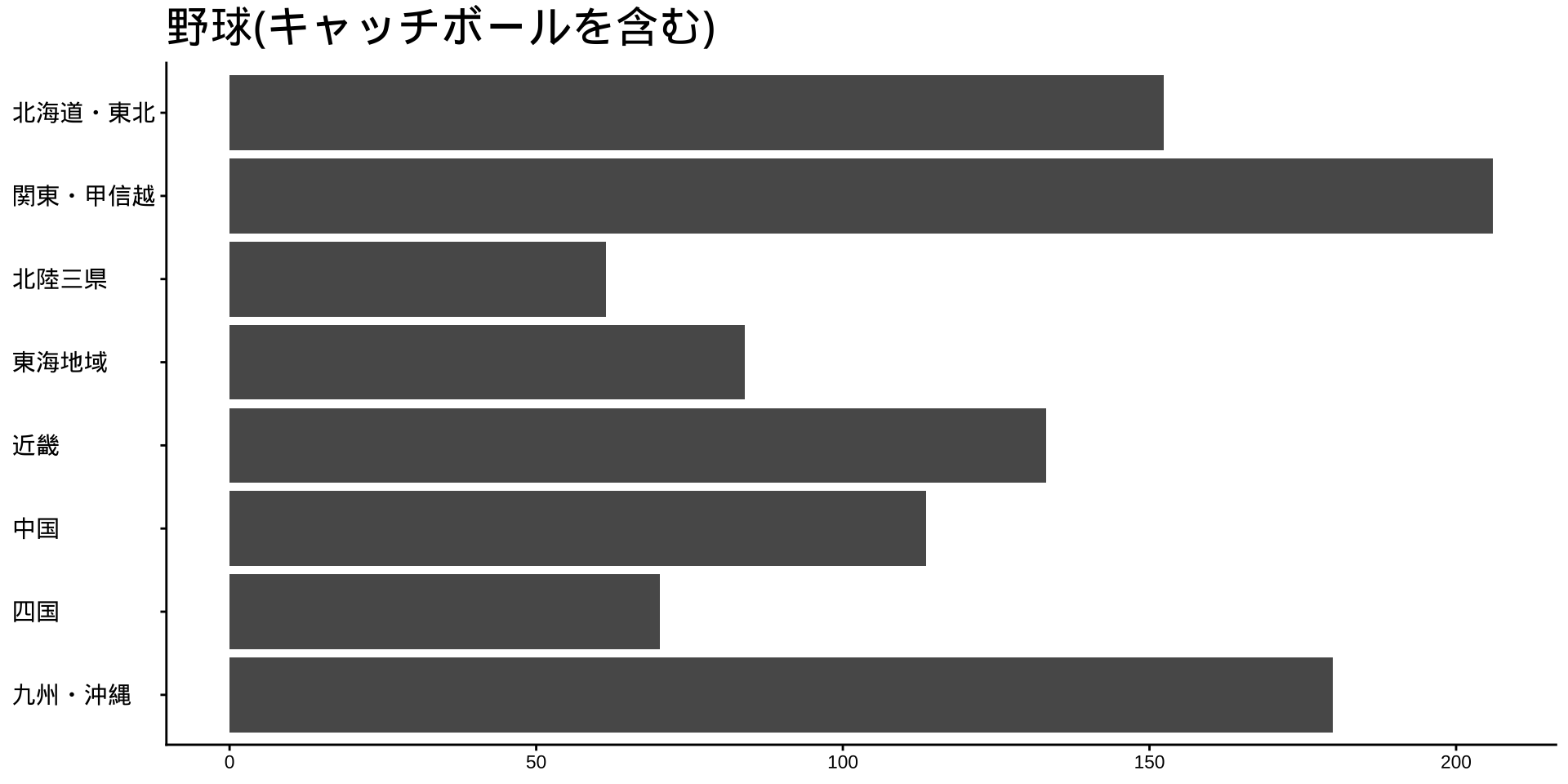
df_long_cat_d_all |>
filter(category_major == "スポーツ") |>
split(~ category_middle) |> # データをスポーツ種目ごとに分ける
walk( # 分けたデータを1つずつ取り出して処理する
\(df) {
p <- # オブジェクトpに代入
df |>
filter(性別 == "男") |>
drop_na() |>
mutate(value = as.numeric(value)) |>
group_by(地域ブロック) |>
summarise(
value_sum = sum(value),
.groups = "drop"
) |>
mutate(
地域ブロック = fct_rev(地域ブロック)
) |>
ggplot(
aes(
x = 地域ブロック,
y = value_sum
)
) +
geom_col() +
labs(
title = unique(df$category_middle),
x = NULL,
y = NULL
) +
coord_flip()
print(p) #オブジェクトpをプロット
}
)