# Setupチャンクに書く
row_data_d_2023 <- read_csv("data/SSDSE-D-2023.csv",
locale = locale(encoding = "CP932"))
row_data_d_2021 <- read_csv("data/SSDSE-D-2021.csv",
locale = locale(encoding = "CP932"))
df_long_d_2023 <-
row_data_d_2023 |>
select("SSDSE-D-2023", Prefecture, matches("^[A-Z]{2}[0-9]{2}$")) |> # 「MA01」「MB12」などのように、アルファベット2文字+数字2桁 になっている列をまとめて選ぶ
select(-c(MA00, MB00, MC00, MD00, ME00, MF00)) |> # 複数の列を一括で削除するためにc()で囲む
pivot_longer(
# 横に並んでいるデータ(列)を、縦に並べ替える
cols = matches("^[A-Z]{2}[0-9]{2}$"), # 対象となる列(コード列)
names_to = "code", # 列名(MA01など)を「code」という列に入れる
values_to = "value"
) # 中の値を「value」という列に入れる
middle_category <-
df_long_d_2023 |>
filter(Prefecture == "都道府県") |>
select(code, category_middle = value)
df_long_cat_d_2023 <-
df_long_d_2023 |>
mutate(Prefecture = factor(Prefecture, levels = pref_levels)) |>
filter_out(Prefecture == "都道府県") |>
filter_out(`SSDSE-D-2023` == "男女の別") |>
drop_na(Prefecture) |>
left_join(middle_category, by = "code") |>
relocate(category_middle, .after = code) |>
mutate(
category_major = case_when(
substr(code, 1, 2) == "MB" ~ "学習・自己啓発・訓練",
substr(code, 1, 2) == "MC" ~ "スポーツ",
substr(code, 1, 2) == "MD" ~ "趣味・娯楽",
substr(code, 1, 2) == "ME" ~ "ボランティア",
substr(code, 1, 2) == "MF" ~ "旅行・行楽",
substr(code, 1, 2) == "MG" ~ "行動種別",
substr(code, 1, 2) == "MH" ~ "平均時刻",
TRUE ~ NA_character_
)
) |>
relocate(category_major, .after = code) |>
rename(都道府県 = Prefecture) |>
filter_out(`SSDSE-D-2023` == "0_総数") |>
separate(`SSDSE-D-2023`, into = c(NA, "性別"), sep = "_") |>
filter(性別 %in% c("男", "女")) |>
mutate(性別 = factor(性別, levels = c("男", "女"))) |>
filter_out(都道府県 == "全国") |>
drop_na(都道府県) |>
mutate(year = 2021, .before = 性別) |>
mutate(data_file_name = "SSDSE-D-2023", .before = year) # 同種の複数データを結合する際に識別できるようファイル名を追加
df_long_d_2021 <-
row_data_d_2021 |>
select("SSDSE-D-2021", Prefecture, matches("^[A-Z]{2}[0-9]{2}$")) |> # 「MA01」「MB12」などのように、アルファベット2文字+数字2桁 になっている列をまとめて選ぶ
select(-c(MA00, MB00, MC00, MD00, ME00, MF00)) |> # 複数の列を一括で削除するためにc()で囲む
pivot_longer(
# 横に並んでいるデータ(列)を、縦に並べ替える
cols = matches("^[A-Z]{2}[0-9]{2}$"), # 対象となる列(コード列)
names_to = "code", # 列名(MA01など)を「code」という列に入れる
values_to = "value"
) # 中の値を「value」という列に入れる
middle_category_2021 <-
df_long_d_2021 |>
filter(Prefecture == "都道府県") |>
select(code, category_middle = value)
df_long_cat_d_2021 <-
df_long_d_2021 |>
mutate(Prefecture = factor(Prefecture, levels = pref_levels)) |>
filter_out(Prefecture == "都道府県") |>
filter_out(`SSDSE-D-2021` == "男女の別") |>
drop_na(Prefecture) |>
left_join(middle_category, by = "code") |>
relocate(category_middle, .after = code) |>
mutate(
category_major = case_when(
substr(code, 1, 2) == "MB" ~ "学習・自己啓発・訓練",
substr(code, 1, 2) == "MC" ~ "スポーツ",
substr(code, 1, 2) == "MD" ~ "趣味・娯楽",
substr(code, 1, 2) == "ME" ~ "ボランティア",
substr(code, 1, 2) == "MF" ~ "旅行・行楽",
substr(code, 1, 2) == "MG" ~ "行動種別",
substr(code, 1, 2) == "MH" ~ "平均時刻",
TRUE ~ NA_character_
)
) |>
relocate(category_major, .after = code) |>
rename(都道府県 = Prefecture) |>
filter_out(`SSDSE-D-2021` == "0_総数") |>
separate(`SSDSE-D-2021`, into = c(NA, "性別"), sep = "_") |>
filter(性別 %in% c("男", "女")) |>
mutate(性別 = factor(性別, levels = c("男", "女"))) |>
filter_out(都道府県 == "全国") |>
drop_na(都道府県) |>
mutate(year = 2016, .before = 性別) |>
mutate(data_file_name = "SSDSE-D-2021", .before = year) # 同種の複数データを結合する際に識別できるようファイル名を追加 RとQuartoではじめるデータサイエンス
#6 可視化(3)と出力
苅谷千尋 
金沢大学
May 20, 2026
差分のプロット
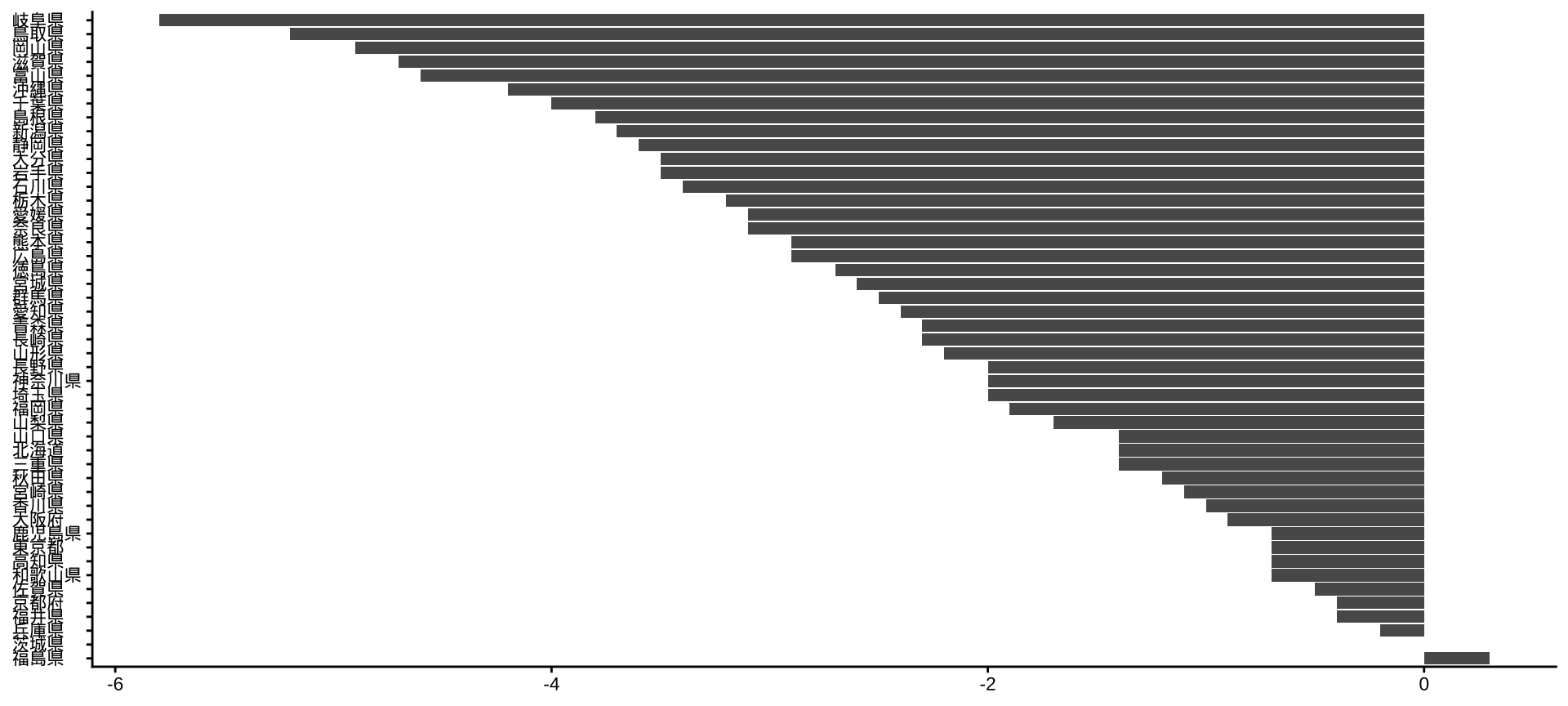
- ほとんどの都道府県で、男性の「野球(キャッチボールを含む)」の時間が縮小している(単独のデータだけでは見えなかった発見)
都道府県単位の日本地図
「野球(キャッチボールを含む)」に費やす時間の可視化(地図)
# 日本地図取得
map_japan <- ne_states("japan") |> # 日本の都道府県地図データを取得 ne_statesはrnaturalearthの関数
select(iso_3166_2, name_ja, name_en) # name_jaだけでも問題はないが、念の為、iso_3166_2や name_enも残す
# df_long_catを加工してbaseballと性別(例示は男)だけにする
df_baseball <-
df_long_cat |>
filter_out(都道府県 == "全国") |>
filter(category_major == "スポーツ") |>
filter(category_middle == "野球(キャッチボールを含む)") |>
drop_na() |>
filter(性別 =="男") |>
mutate(value = as.numeric(value))
# 上記の二つのデータフレームを結合
map_japan |>
left_join(
df_baseball,
by = c("name_ja" = "都道府県") # データフレーム間で列名が異なる場合の処理方法
) |>
ggplot() +
geom_sf(aes(fill = value)) + # valueで塗り分ける
scale_fill_distiller( # 数値の大小を、連続的な色の濃淡で表現するための関数
palette = "Blues", # 色の指定
direction = 1 # 値が大きいものを濃く、その逆を薄くする
) +
labs(fill = NULL) + # 凡例を削除
theme_void() # x軸とy軸の経度と緯度を削除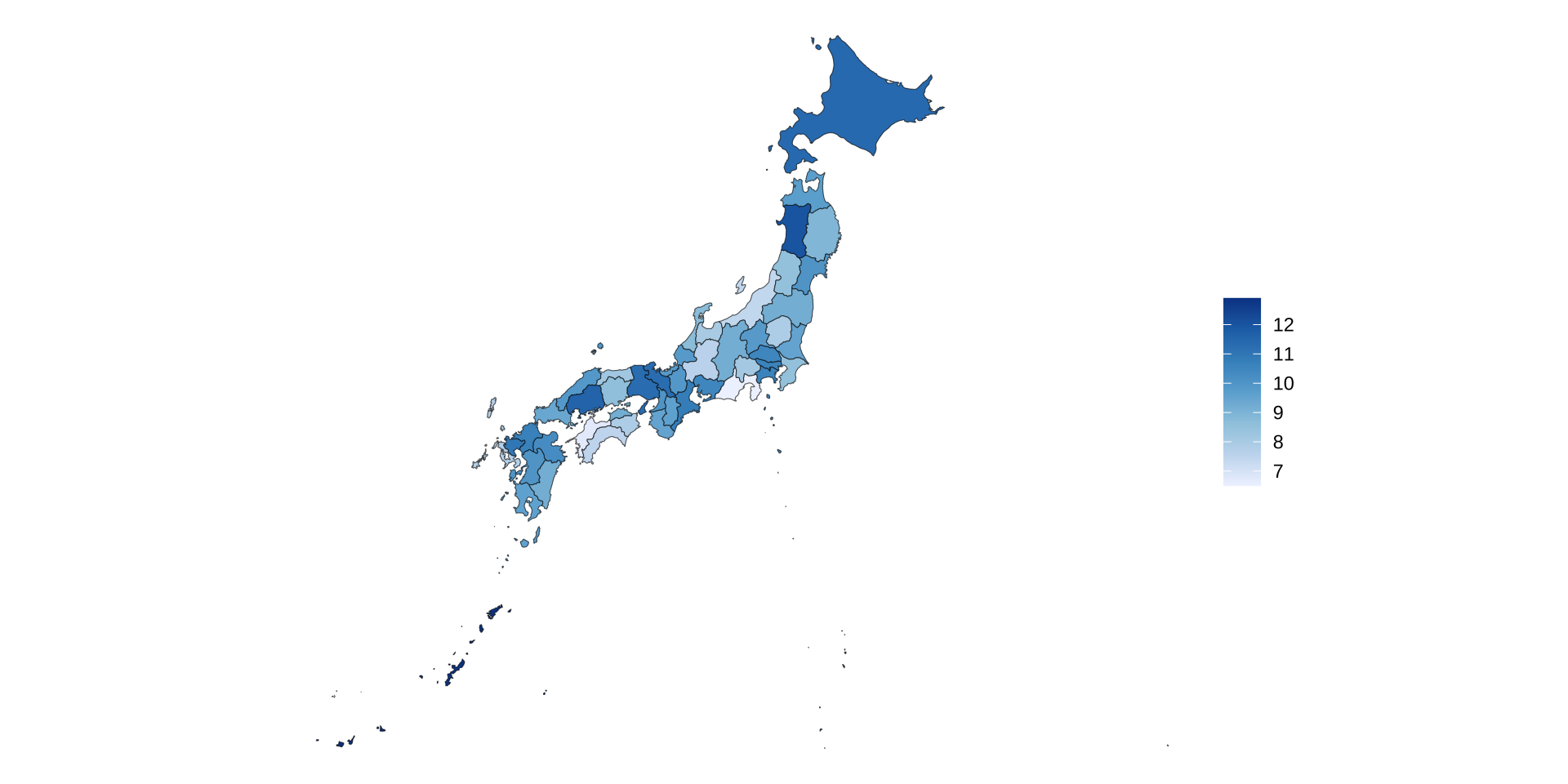
国境・河川・湖の地図のプロット
- rnaturalearthの地理データの利用
モンゴルの地図に地理データを乗せる
mongolia <- ne_countries(
country = "mongolia",
returnclass = "sf"
)
rivers <- ne_download(
scale = 10,
type = "rivers_lake_centerlines",
category = "physical",
returnclass = "sf"
) |>
st_make_valid()
rivers_mg <- st_intersection(
rivers,
st_union(mongolia)
)
lakes <- ne_download(
scale = 10,
type = "lakes",
category = "physical",
returnclass = "sf"
) |>
st_make_valid()
lakes_mg <- st_intersection(
lakes,
st_union(mongolia)
)
cities <- ne_download(
scale = 10,
type = "populated_places",
category = "cultural",
returnclass = "sf"
)
ulaanbaatar <- cities |>
filter(NAME == "Ulaanbaatar")
ggplot() +
geom_sf(data = mongolia,
fill = "cornsilk",
color = "gray40") +
geom_sf(
data = lakes_mg,
fill = "skyblue",
color = NA
) +
geom_sf(data = rivers_mg,
color = "skyblue") +
geom_sf(data = ulaanbaatar,
size = 3,
color = "red") +
theme_void()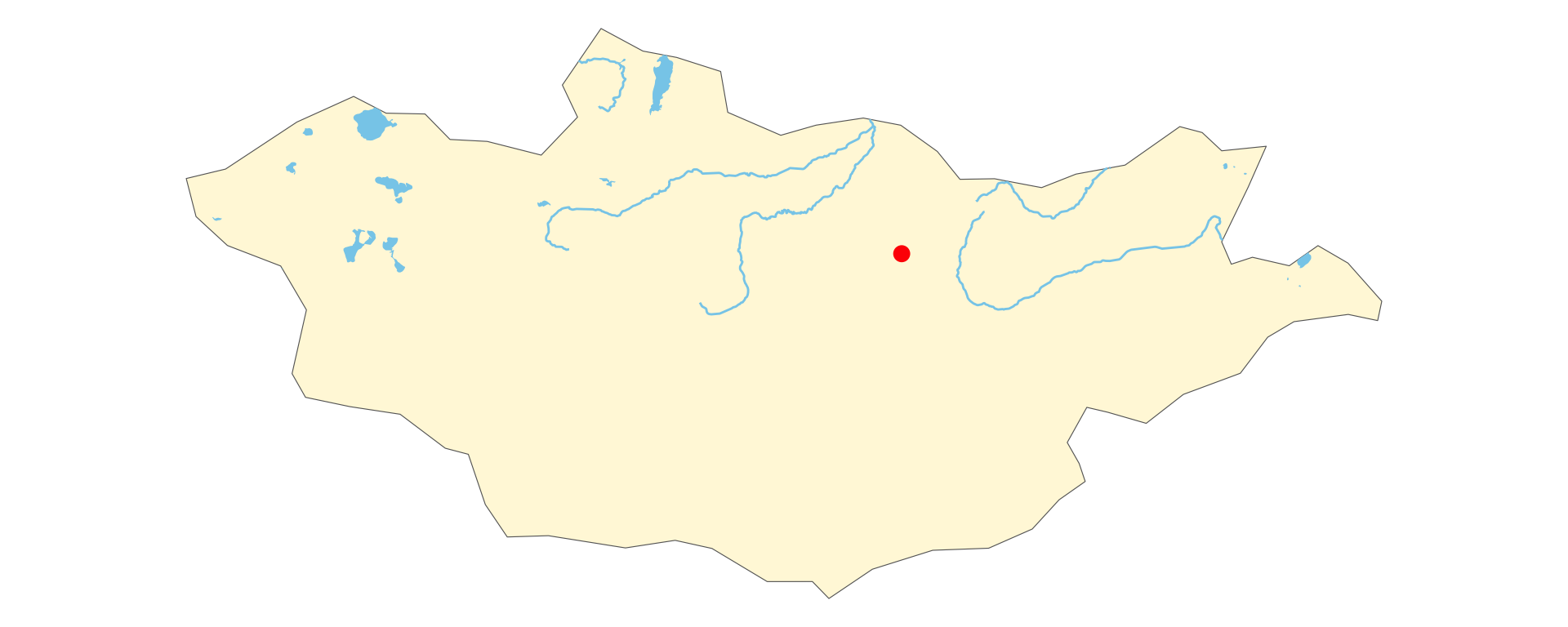
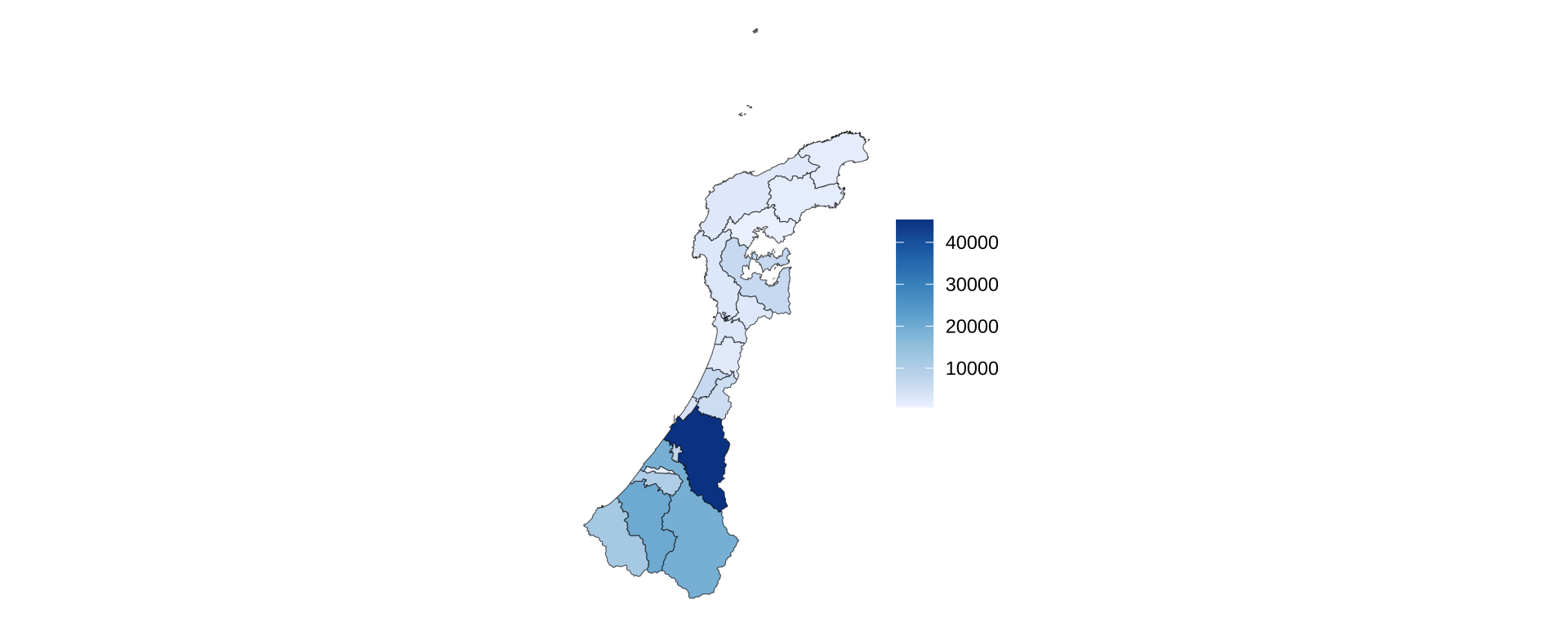
市町村単位の日本地図
石川県内の第2次産業就業者数の可視化(市町村別の地図)
- 準備:市町村単位のデータ(SSDSE-A-2025)を取得し、dataフォルダに入れる
df_ssdse_a <-
read_csv("data/ssdse_a.csv")
ishikawa <-
jpn_pref(pref = 17, district = TRUE) |> # pref = 17 は「石川県」を意味するコード
left_join(df_ssdse_a, by = c("city_code" = "市区町村コード")) # district = TRUE にすると、市区町村レベルの地図になる
ishikawa |>
filter(code_name == "第2次産業就業者数") |> # 「第2次産業就業者数」だけを取り出す
ggplot() +
geom_sf(aes(fill = value)) + # sf(地図データ)を描画。fill = value によって、値に応じて色を塗り分ける
scale_fill_distiller( # 数値の大小を、連続的な色の濃淡で表現するための関数
palette = "Blues", # 色の指定
direction = 1 # 値が大きいものを濃く、その逆を薄くする
) +
labs(fill = NULL) +
theme_void()