| 項目 | 比率 |
|---|---|
| 宿題:授業の感想 | 30 |
| 宿題:演習 | 30 |
| レポート | 20 |
| プレゼンテーション | 10 |
| 受講態度 | 10 |
RとQuartoではじめるデータサイエンス
#1 イントロダクション
苅谷千尋 
金沢大学
April 8, 2026
自己紹介
- 名前、学類
- 受講動機
- データ分析したい対象(の有無)
- 高校「情報」科目で習ったこと(該当者のみ)
- プログラミングの経験の有無

表によるデータ提供


- 総務省統計局 e-stat
- エクセルデータ(複雑なカラム名構造、結合、空白行)。pdfも多い
- 例:家計調査報告 ―月・四半期・年―
- OECD
- データセット、csvによるデータ提供
なぜRなのか / なぜQuartoなのか
5. 簡易的な記述法(Quarto)
| 要素 | Markdown構文 | 例 |
|---|---|---|
| 見出し | # H1## H2 |
H1 見出し H2 見出し |
| 太字 | **bold text** |
bold text |
| イタリック | *italicized text* |
italicized text |
| 引用 | > blockquote |
> blockquote |
| リンク | [金沢大学](https://www.kanazawa-u.ac.jp) |
金沢大学 |
| 画像 |  |
色や文字の大きさは、別途、CSSファイルを用意して、変更する必要があります
R Studio(ペイン)の見方
- 4画面構成
- 主要な操作は左上のソースペインで行う
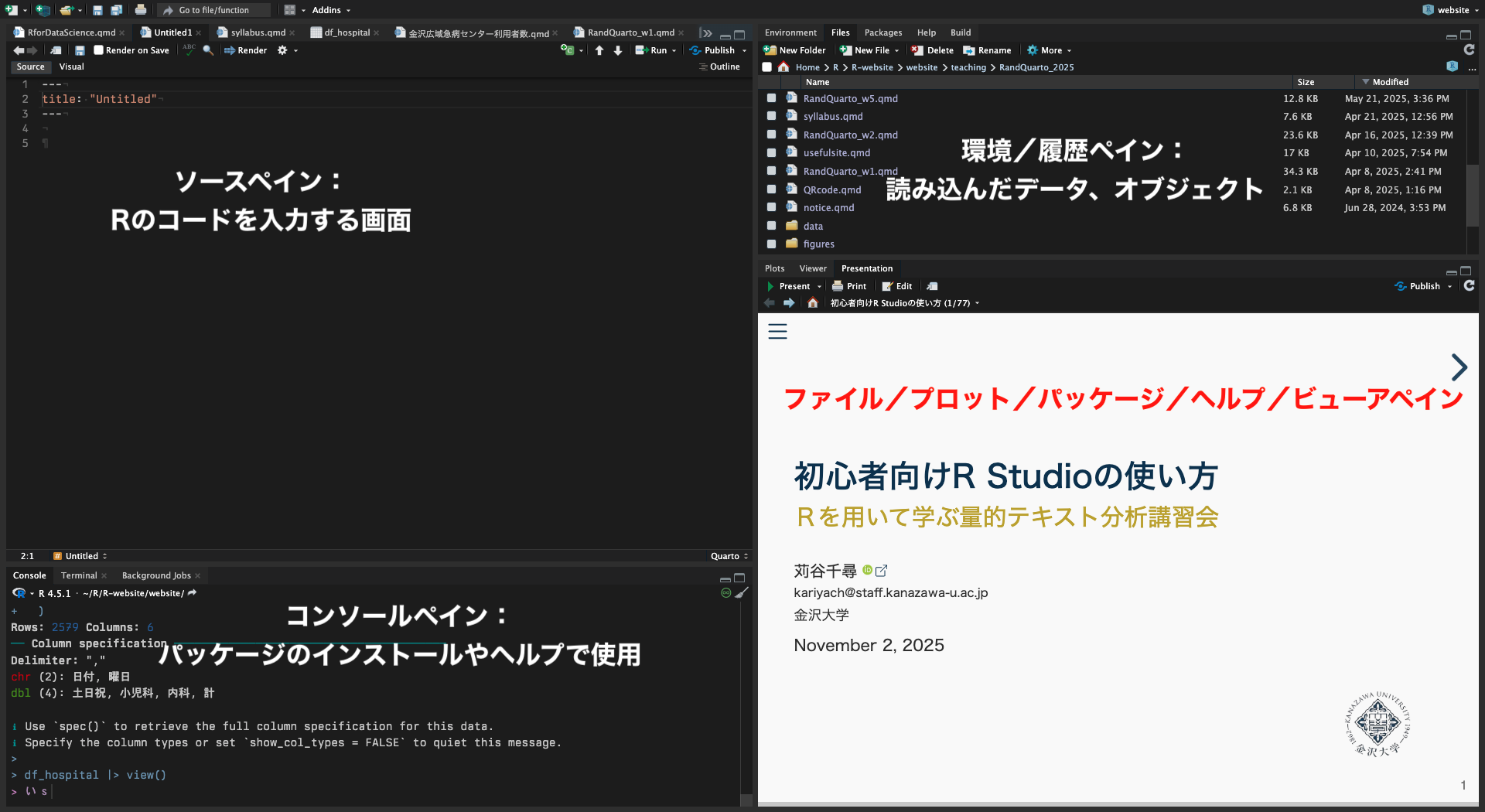
R Studio(ソースペイン)の外観の変更
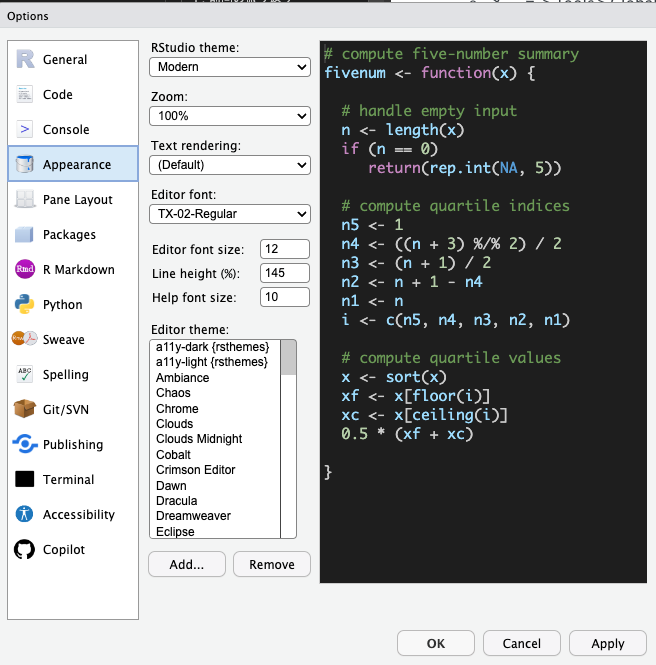
R Studio(ソースペイン)の外観の変更
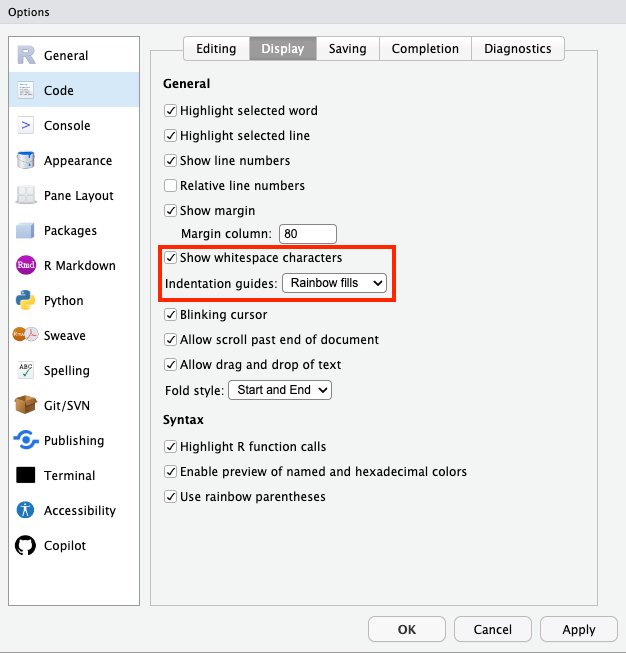
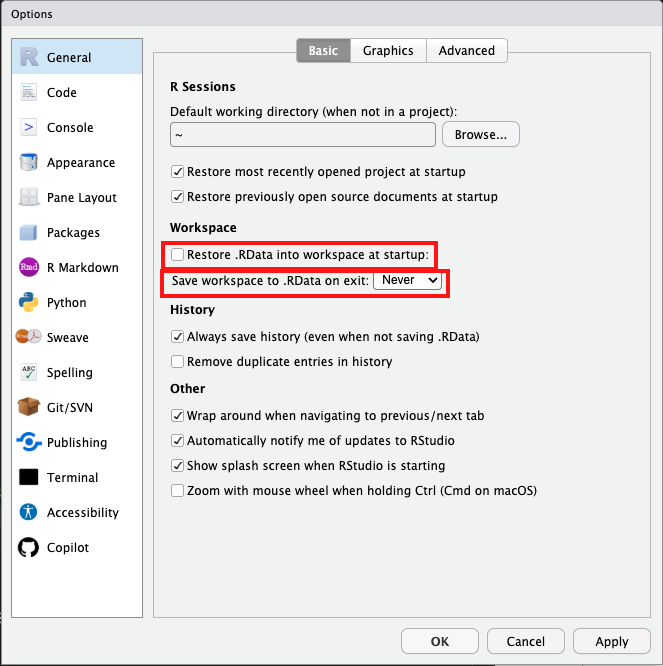
R Studioの保存・復元設定
- 意図しない古いデータが使われることを避ける必要あり
8. 「.RData」保存をオフにする
- メニュー > Tools > Global Options > General > Workspace
- Restore .RData into workspace at startup: チェックを外す
- Save workspace to .RData on exit: Neverを選択
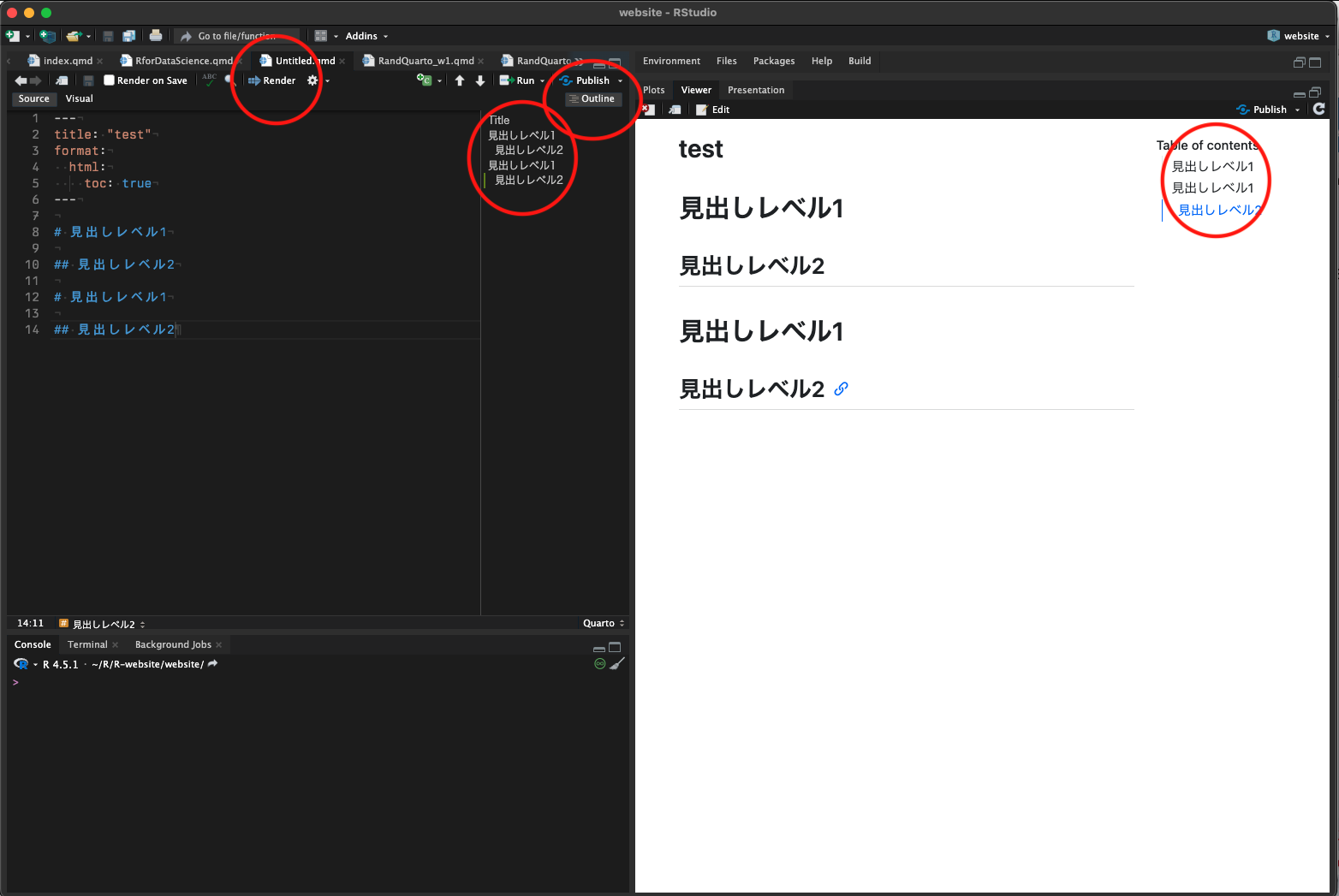
目次の追加(YAML)
- Renderをクリック
- YAMLで設定している出力形式に従って右下のペイン(Viewer/Presentation)にレポートが出力される(全てのR Chunkが実行される(後述))
基本:データセット
- パーマーランド(南極)の3つの島に住むペンギンたちのデータ
ペンギンの種類:
- Adelie(アデリーペンギン)
- Gentoo(ジェンツーペンギン)
- Chinstrap(ヒゲペンギン)
島の名前:
- Biscoe(ビスコー)
- Dream(ドリーム)
- Torgersen(トージャーセン)

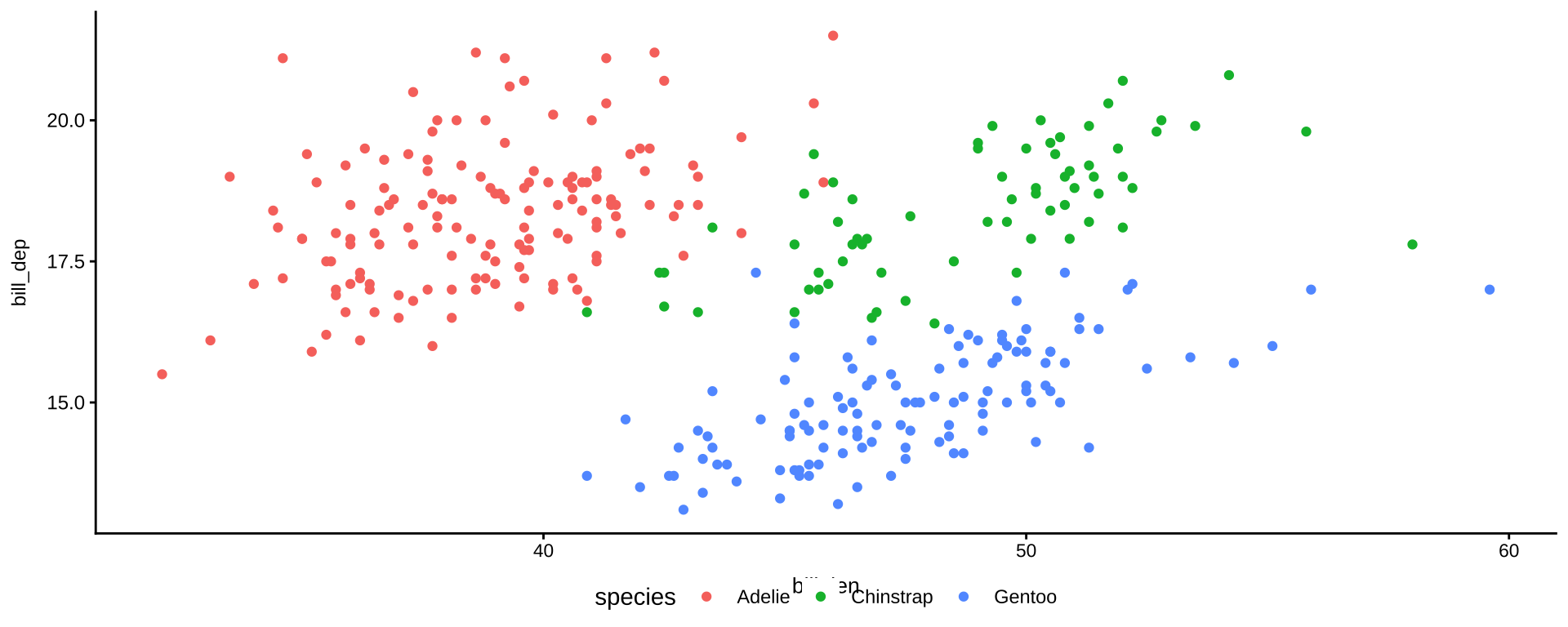
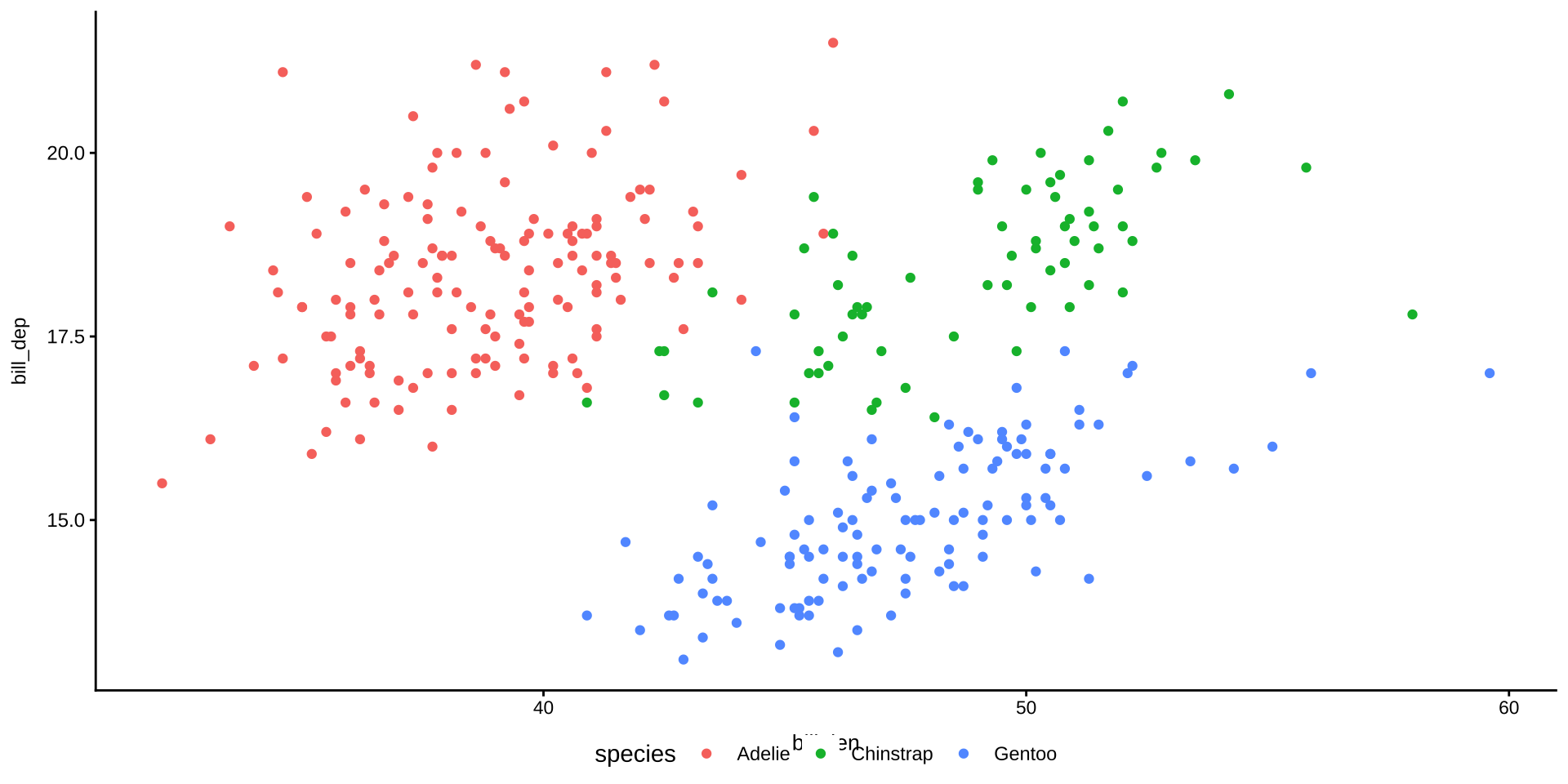
散布図を作ろう
- Codeのコードをクリップボードを使ってコピー
- 先に作成したqmdファイルにR Chunkを作る(メニュー > Code > Insert Chunk)
- R Chunk内に貼り付け
- chunkを実行(またはRender)
見出しを付けよう
- R Chunkで囲まれていない領域(=markdown領域)に見出しを付けて、今日行ったことを整理しよう
#を付けると見出しになる
# 第1回 4月8日
## 散布図
penguins |> # tidyverseに組み込まれているサンプルのデータセットを使う
filter(!if_any(everything(), is.na)) |> # 欠損値を除外
ggplot(aes(x = bill_len, y = bill_dep, colour = species)) + # x軸、y軸、分布の色分けを指定
geom_point() # 散布図
散布図
社会意識に関する世論調査
- 内閣府大臣官房政府広報室 世論調査「社会意識に関する世論調査」
国の政策への民意の反映(クロス集計)
- Q. あなたは、全般的にみて、国の政策に国民の考えや意見がどの程度反映されていると思いますか
- Q. あなたは、社会の動きを知ろうとするときに、どこから情報を得ることが多いですか(○はいくつでも)
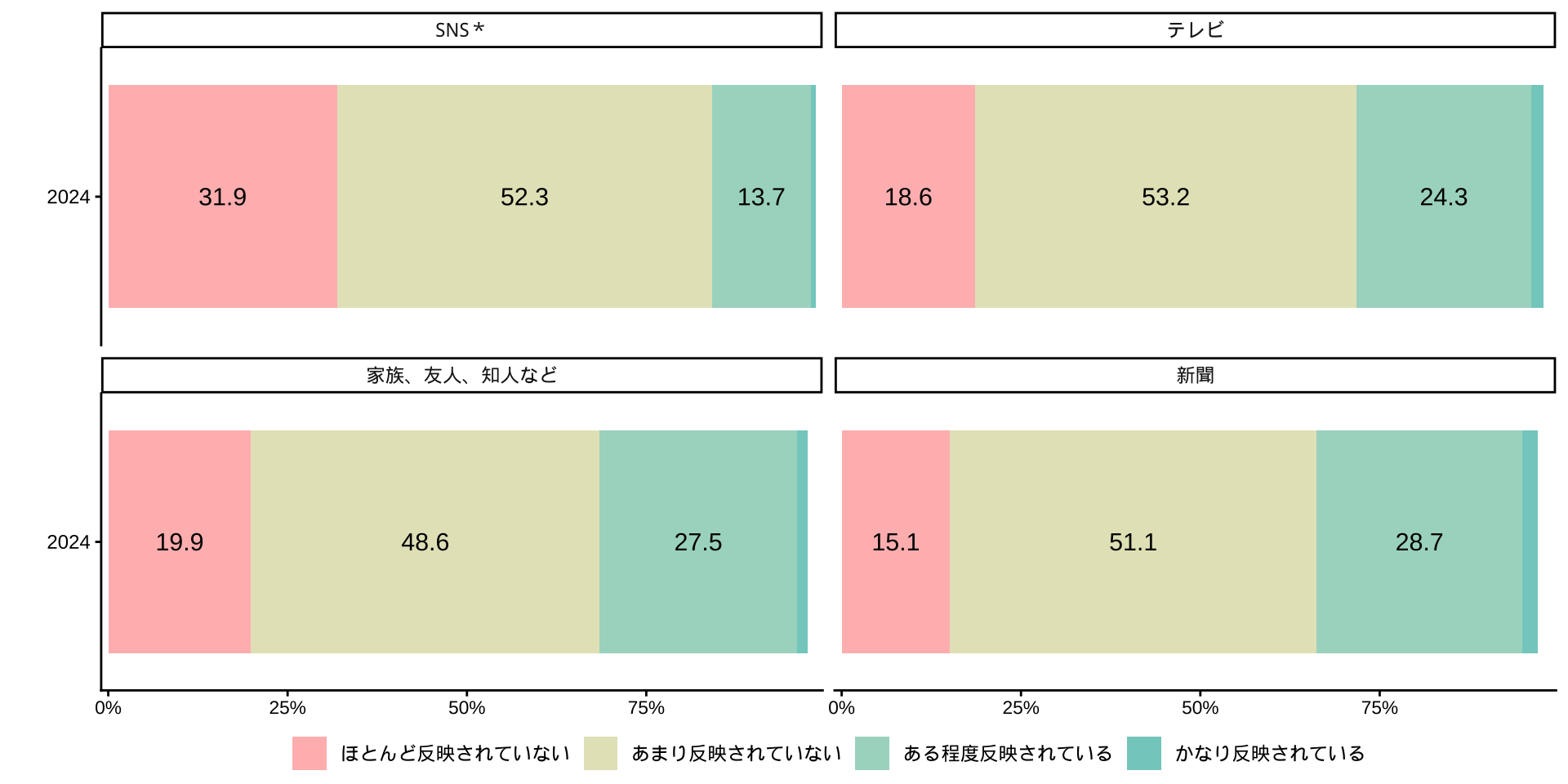
社会意識に関する世論調査
- Q. あなたは、全般的にみて、国の政策に国民の考えや意見がどの程度反映されていると思いますか
- Q. あなたは、現在の日本の状況について、悪い方向に向かっていると思われるのは、どのような分野についてでしょうか(○はいくつでも)
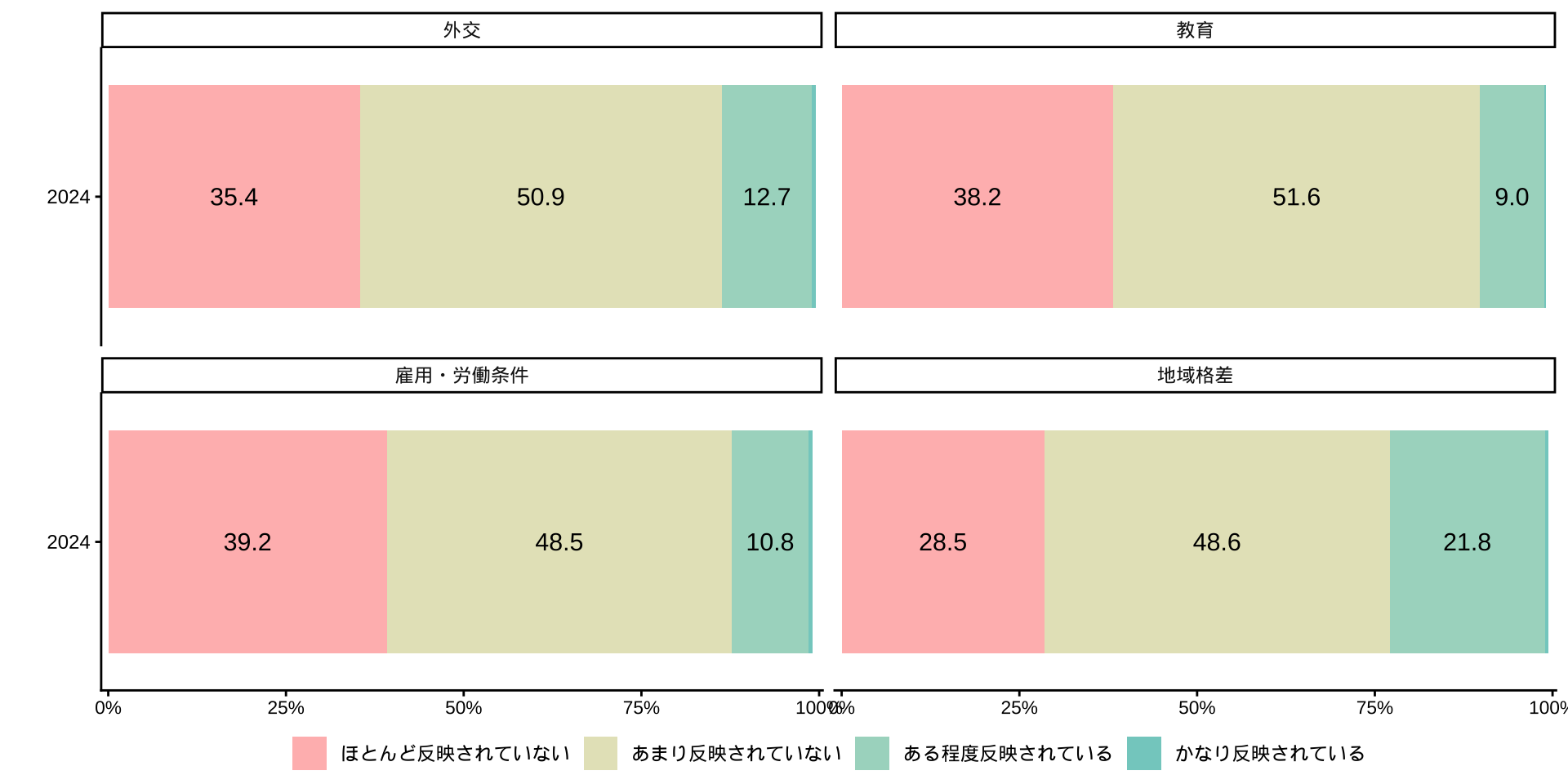
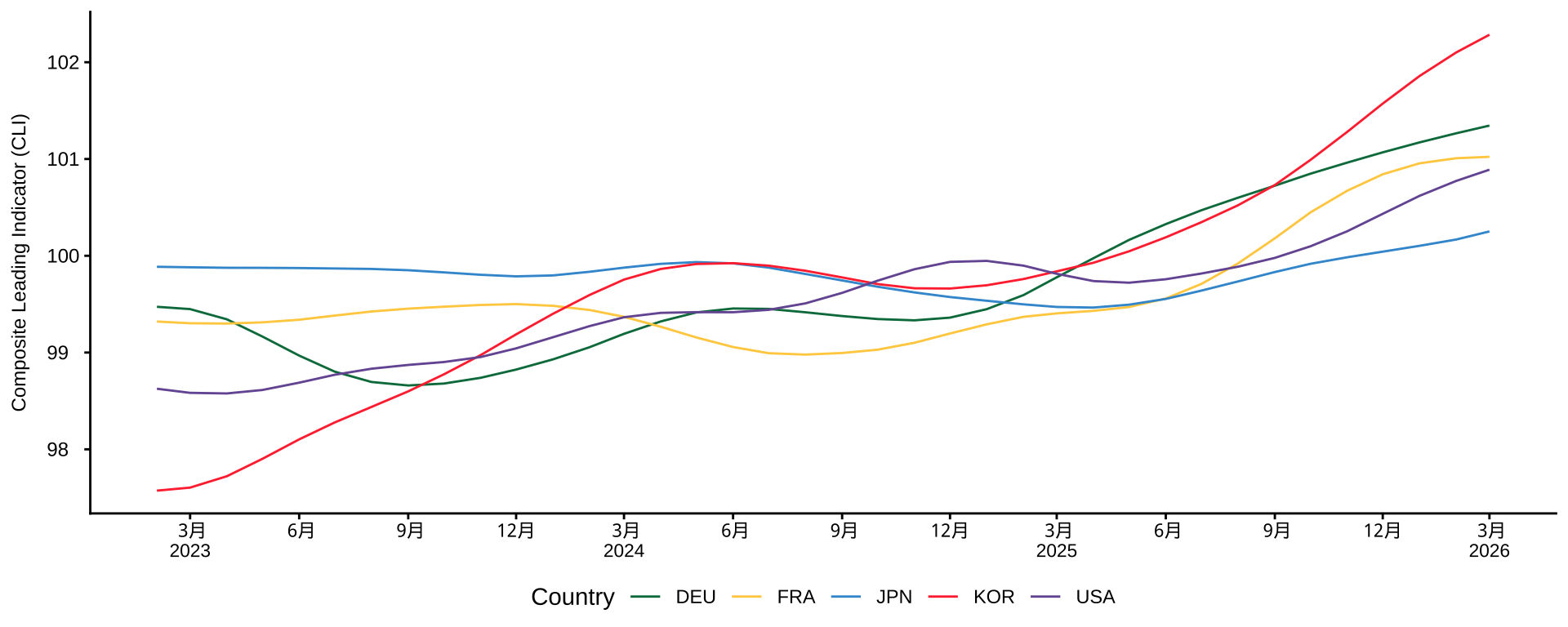
URLからデータ取得(OECD景気先行指数)
- OECDデータセット:Composite Leading Indicators (CLI)
- urlを指定して、データを取得(ファイルはダウンロードしない)
url <- "https://sdmx.oecd.org/public/rest/data/OECD.SDD.STES,DSD_STES@DF_CLI/.M.LI...AA...H?startPeriod=2023-02&dimensionAtObservation=AllDimensions&format=csvfilewithlabels"
df_oecd_cli <- read_csv(url) # 指定したURLから直接データを読み込み
de_oecd_cli_selected <- # 必要な列だけ取り出す
df_oecd_cli |>
select(REF_AREA, TIME_PERIOD, OBS_VALUE) |> # 必要な列を取り出す
mutate(TIME_PERIOD = ym(TIME_PERIOD)) # 年月を日付型に変換
countries <- c("JPN", "USA", "DEU", "FRA", "KOR") #主要国だけ選ぶ(主要国のオブジェクトを作る)
de_oecd_cli_selected |>
filter(REF_AREA %in% countries) |> # REF_AREA が countries に含まれる行だけを抽出
ggplot(aes(x = TIME_PERIOD, y = OBS_VALUE, color = REF_AREA)) +
geom_line() +
scale_x_date(
breaks = scales::breaks_width("3 months"), # x軸の間隔調整
labels = scales::label_date_short() # 年と月を行を変えて表記
) +
scale_y_continuous(
breaks = scales::breaks_extended(8), # 目盛りの個数を指定
labels = scales::label_number(accuracy = 1) # 数値表示(小数なし)
) +
labs( # ラベル名と凡例名の変更
x = "",
y = "Composite Leading Indicator (CLI)",,
color = "Country"
) +
scale_color_paletteer_d("awtools::mpalette")