RとQuartoではじめるデータサイエンス
#5 可視化(2)
苅谷千尋 
金沢大学
May 13, 2026
チャンクオプション
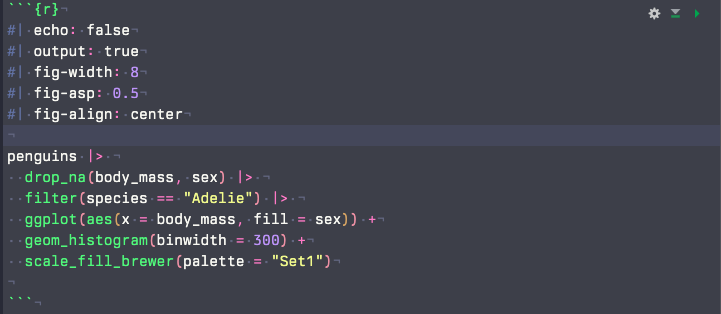
- ただし、echoとoutputは、YAMLでグローバル設定するのが普通(後述)
チャンクオプション
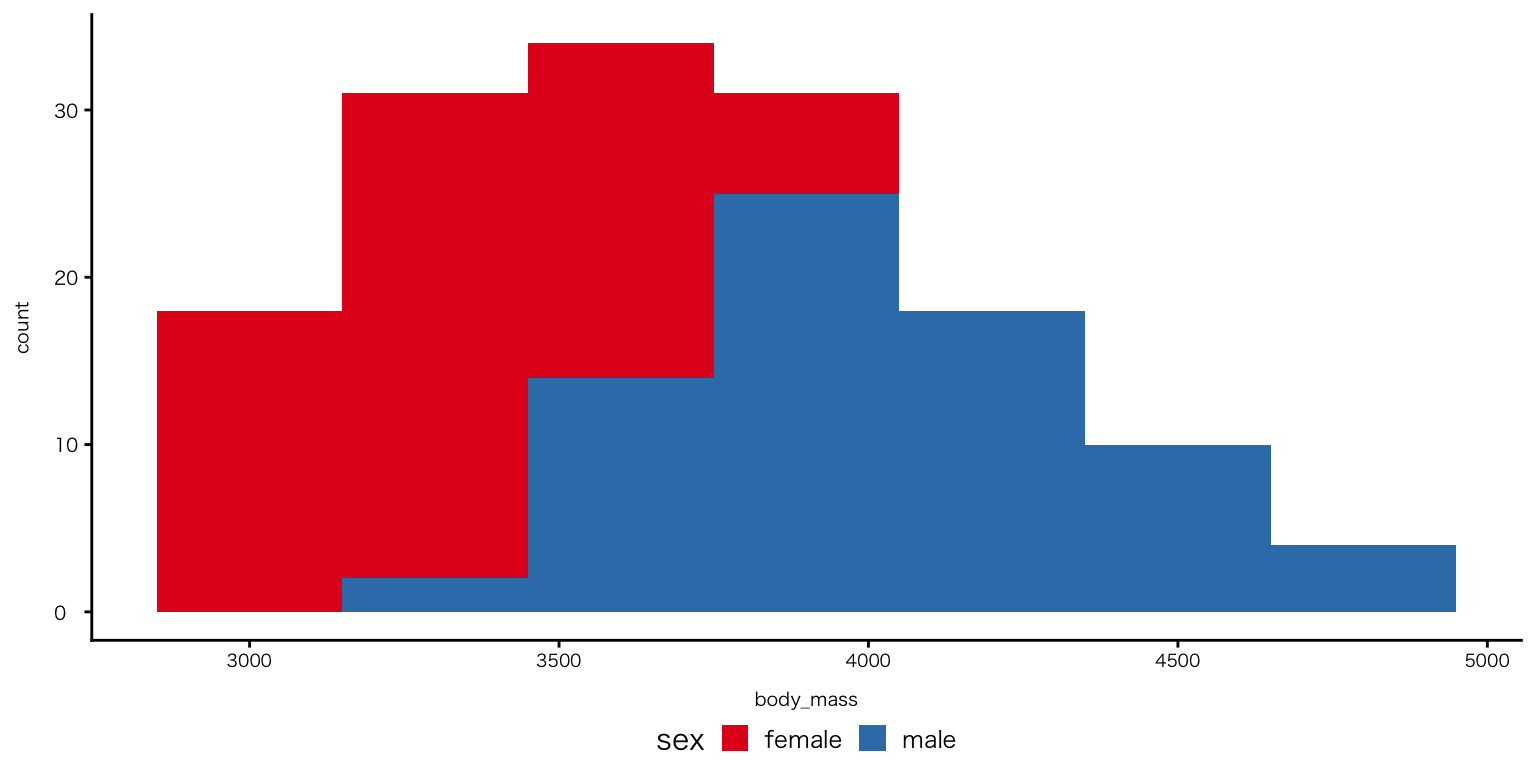
チャンクオプション
evalの使い方
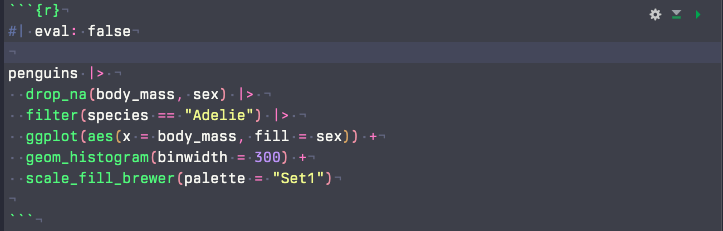
- 補完入力されない
- 補完入力される
theme
ggplot公式theme
- theme_gray():デフォルト
- theme_bw():白黒(論文向け)
- theme_classic():軸だけ(推奨)
- theme_minimal():最小限(プレゼン向け)
- theme_void():何もなし
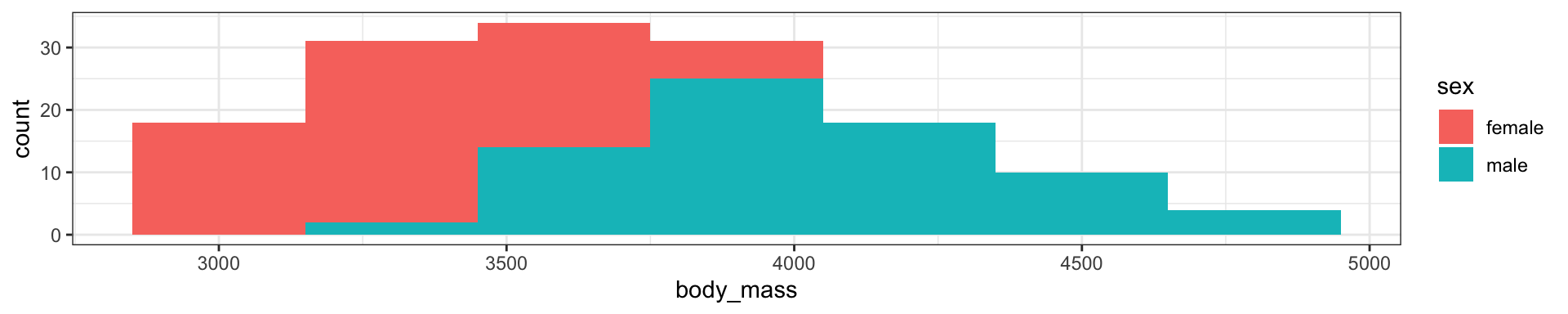
色
色の変更:ggplotのパレット
fill
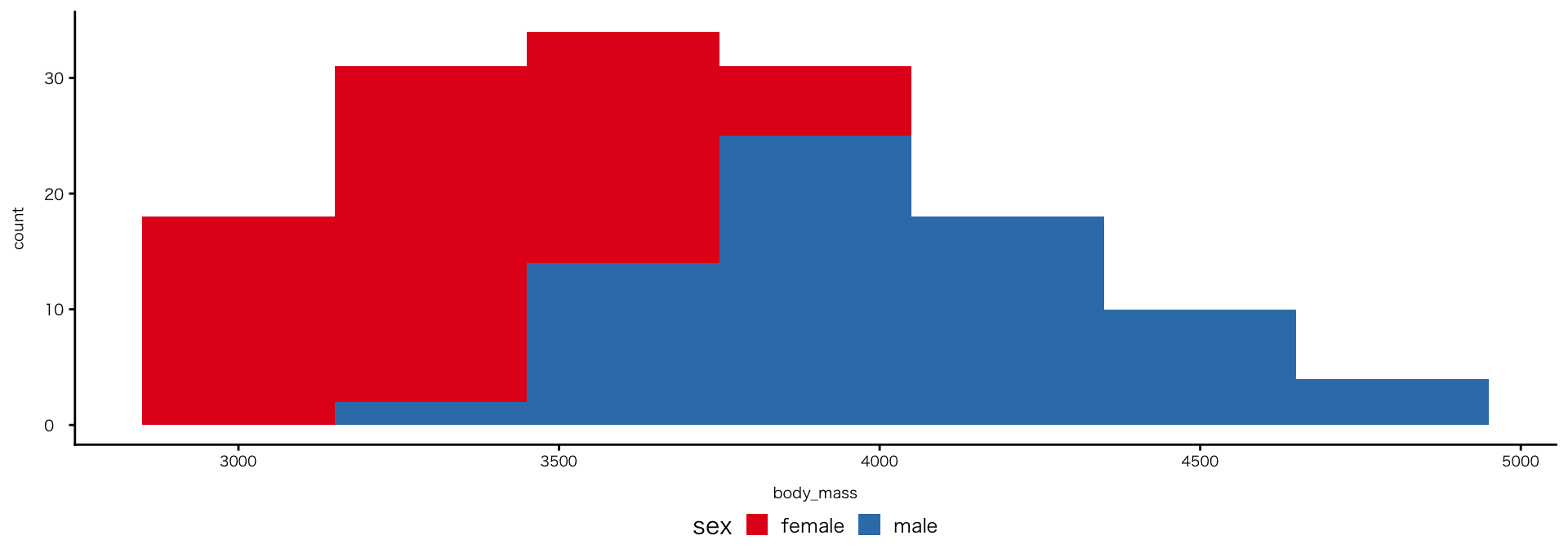
colour
色
色の変更:マニュアル指定
- カラー名の他、HTMLカラーコードも使用可
- Cf. WEB色見本 原色大辞典
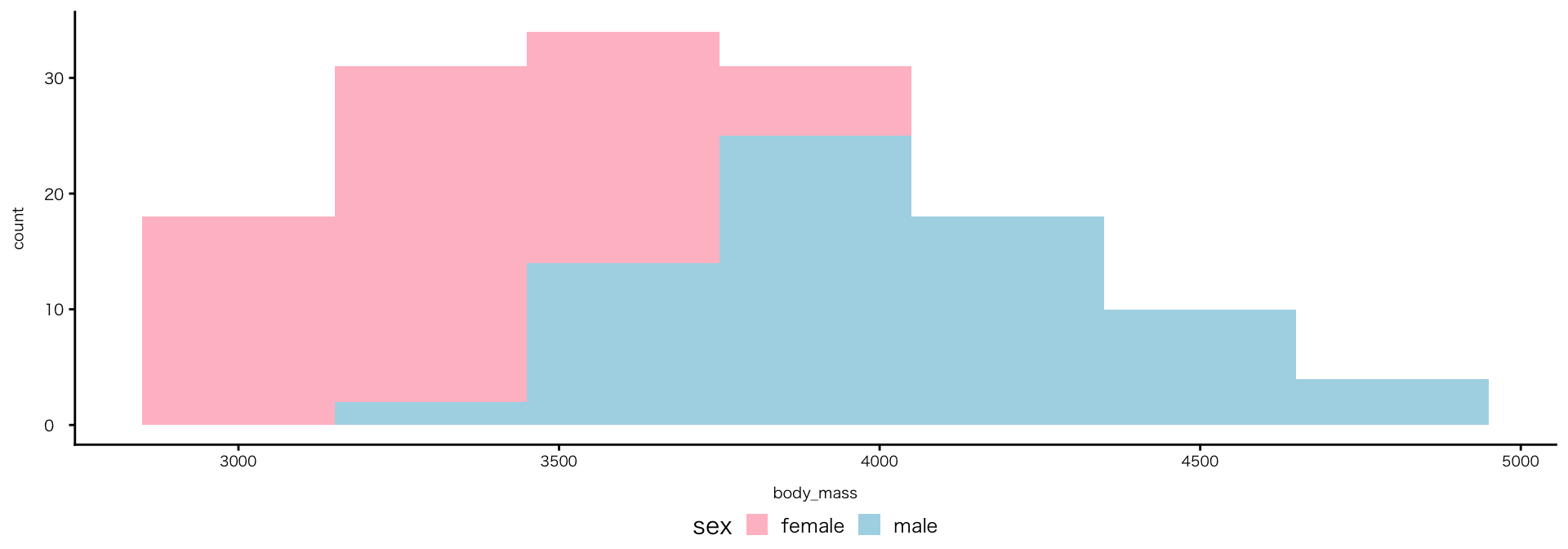
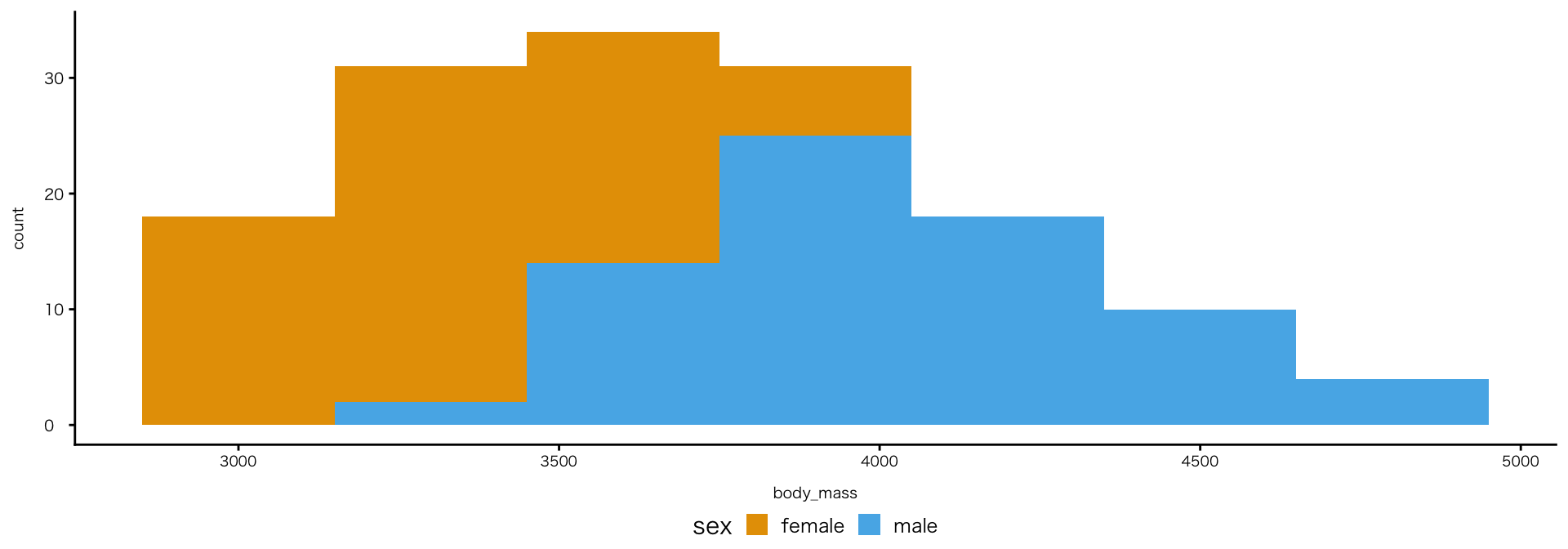
色
色の変更:追加パッケージ
- 色指定の関数はパッケージごとに異なる
- パッケージのインストールと読み込みが必要
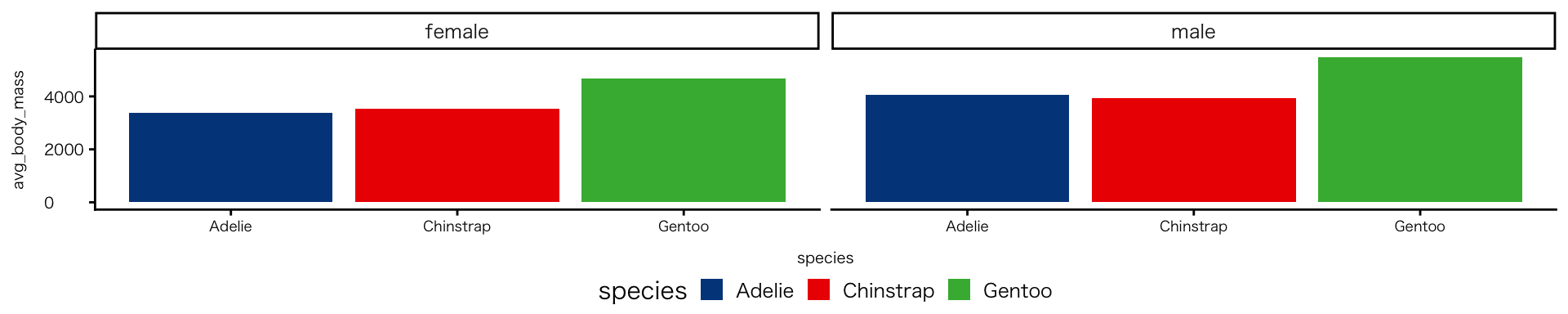
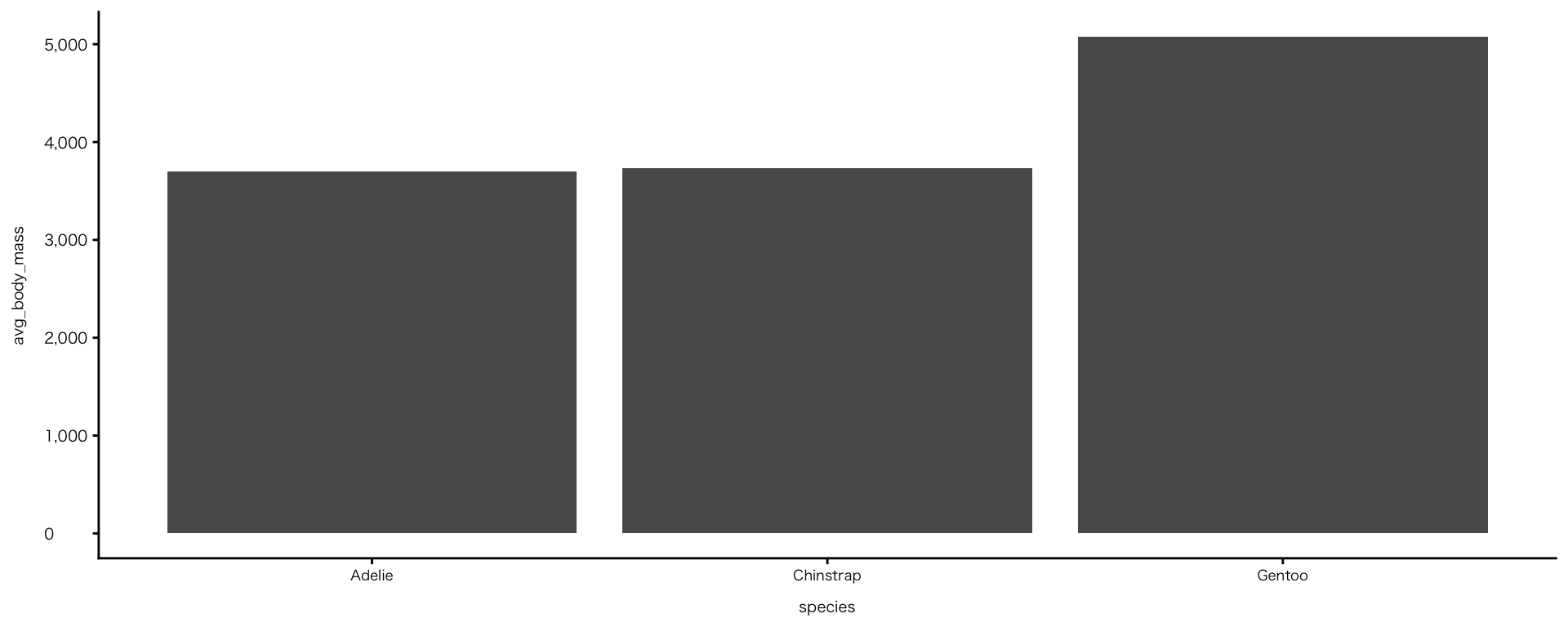
penguins |>
drop_na(species, sex, body_mass) |>
group_by(species, sex) |>
summarise(avg_body_mass = mean(body_mass), .groups = "drop") |>
ggplot(aes(x = species, y = avg_body_mass, fill = species)) +
geom_col() +
facet_wrap(~ sex) +
scale_fill_paletteer_d("DresdenColor::briefcases") # "ダブルクォテーション内がパレット名"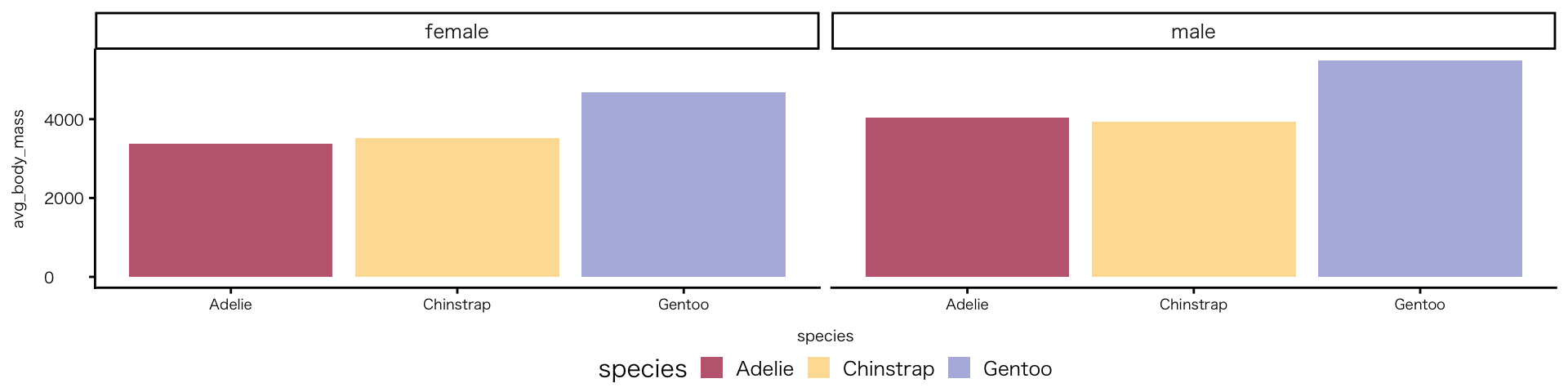
色
色の変更:追加パッケージ
- 色指定の関数はパッケージごとに異なる
- パッケージのインストールと読み込みが必要
penguins |>
drop_na(species, sex, body_mass) |>
group_by(species, sex) |>
summarise(avg_body_mass = mean(body_mass), .groups = "drop") |>
ggplot(aes(x = species, y = avg_body_mass, fill = species)) +
geom_col() +
facet_wrap(~ sex) +
scale_fill_manual(values = met.brewer("Klimt", 3)) # "ダブルクォテーション内がパレット名"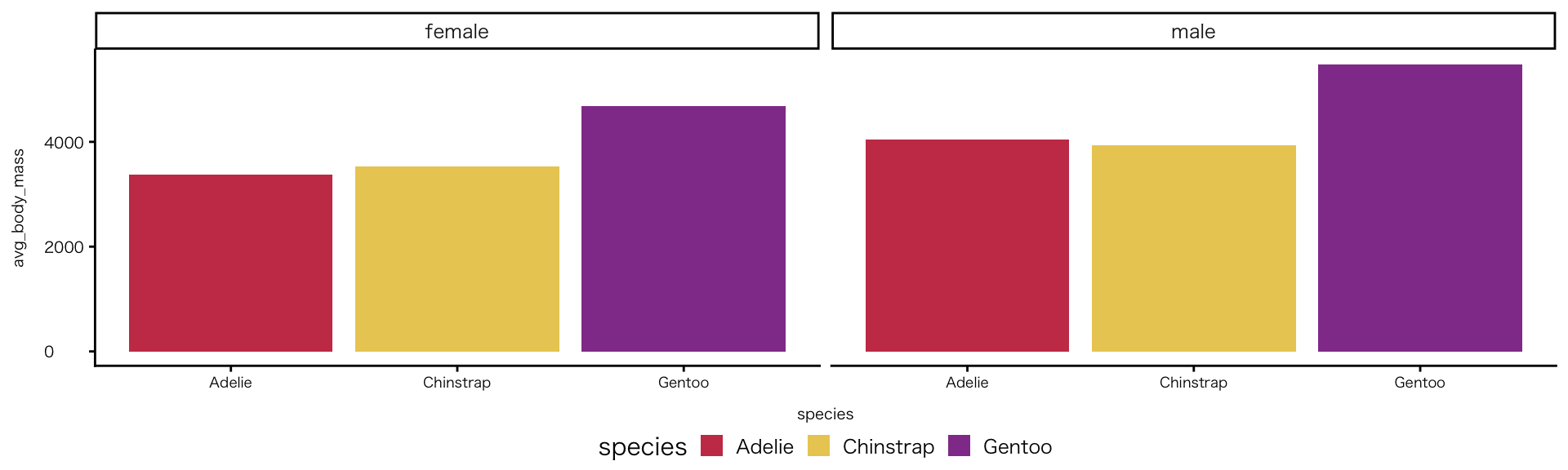
色
色の変更:追加パッケージ
- 色指定の関数はパッケージごとに異なる
- パッケージのインストールと読み込みが必要
色
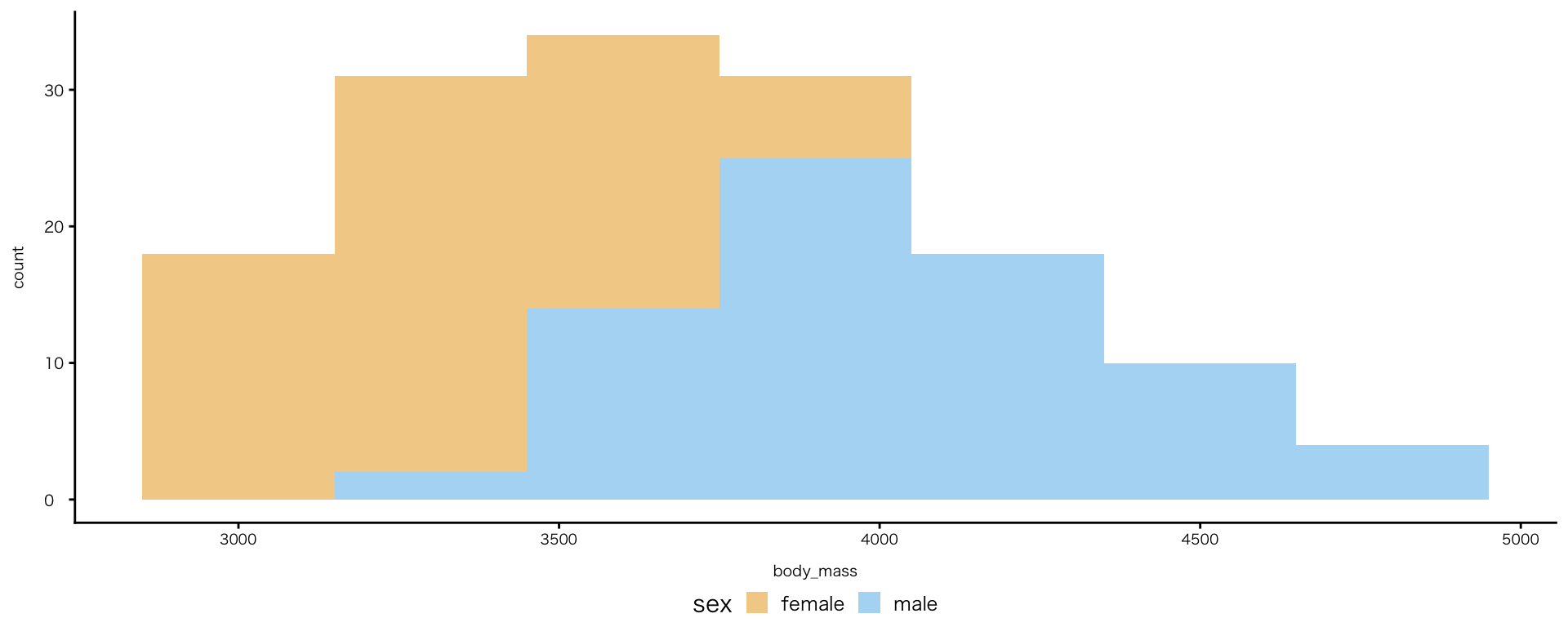
色の透過度
- 透過度は
geom_()内のalphaで指定- 0: 完全に透明(見えない)/ 1: 完全に不透明(普通の色・デフォルト値)
色
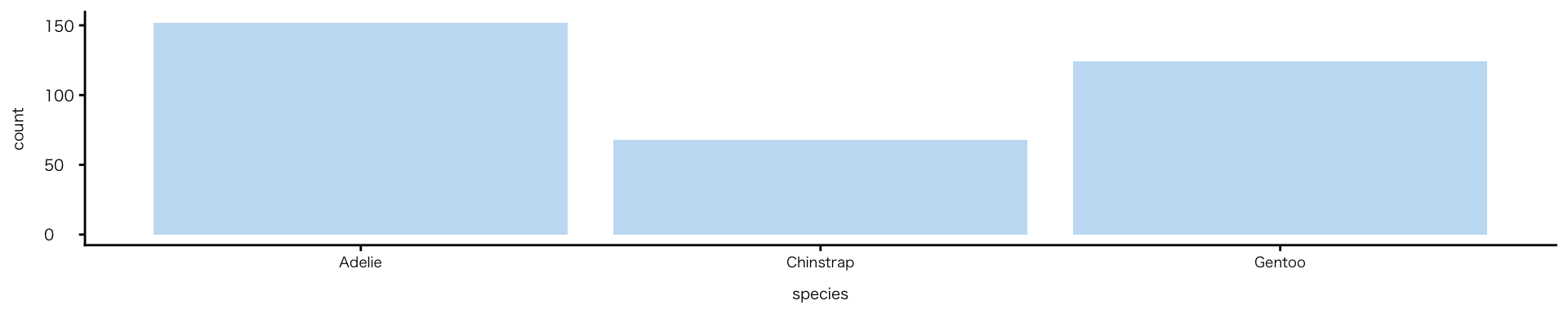
データによる色分けではない色の変更
- データと関係ない固定色の指定
- fillでもcolourでもない色を変えたい
- 方法:aesの外で指定する
geom_()内のfillで指定- Cf. aes() の中:データに応じて変わる
軸ラベル
label_percent()関数
- 数値をパーセント形式に変換する関数
scale_x_continuous()関数 / scale_y_continuous()関数
- 軸の設定を変更する関数
- continuous は「連続値」という意味
軸ラベル
label_comma()関数
- 軸の値に,を足す関数
- 例:100000→100,000
軸ラベル
label_kansuji()関数
- 日本語表記の桁数に変える関数
- 例:100,000→10万
- zipangu:日本語表記(年号・住所への対応)に対応するパッケージ
パッケージのインストールと読み込みが必要 パッケージがCRANにおいてないため、install.packagesが使えない パッケージremotesを利用。以下のコードをConsoleに入力して実行
install.packages("remotes")
remotes::install_github("uribo/zipangu")df_pop_all |>
mutate(都道府県 = factor(都道府県, levels = pref_levels)) |>
ggplot(aes(x = 都道府県, y = 推定人口)) +
geom_col(fill = "#D55E00") +
gghighlight(都道府県 == "石川県") +
scale_y_continuous(labels = zipangu::label_kansuji()) + # y軸のラベルを日本語にして視認性を高める
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # x軸のラベルの角度を調整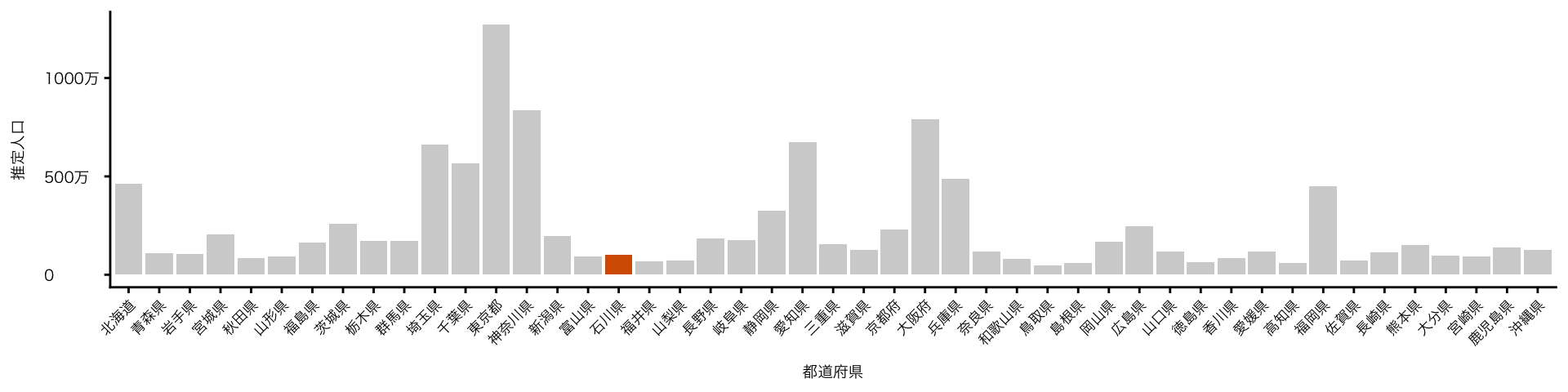
軸ラベル・凡例ラベル
fill
軸ラベル・凡例ラベル
colour
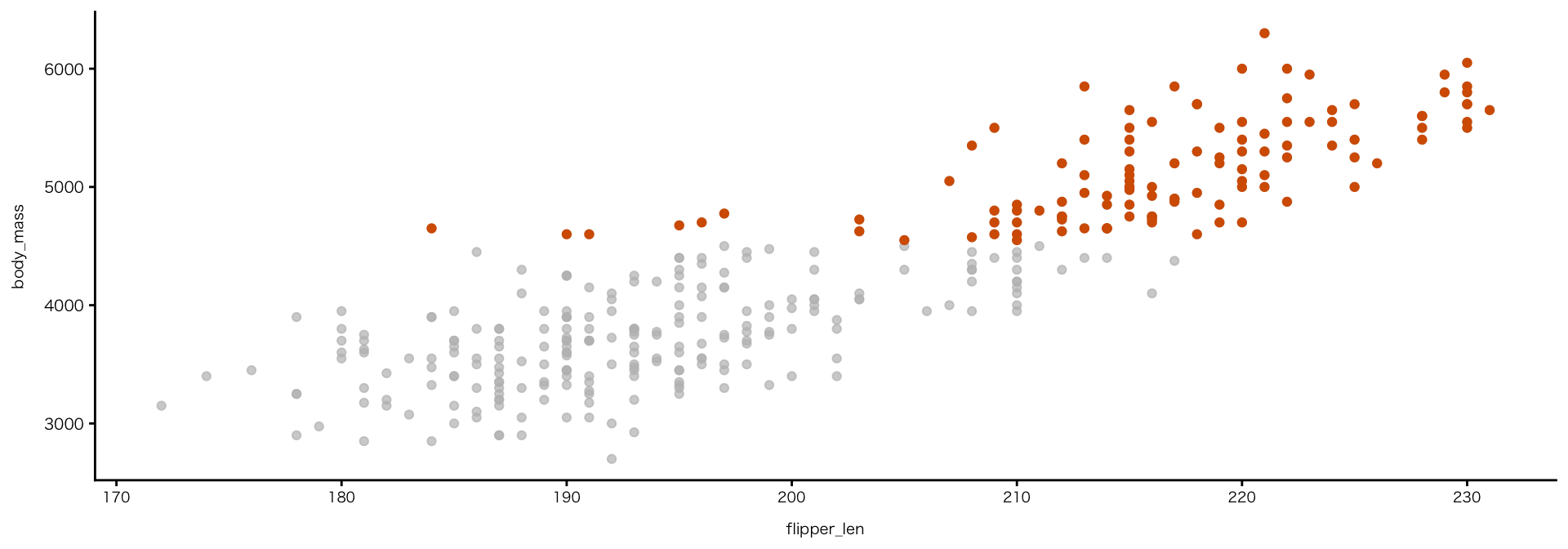
ハイライト
- 注目してほしい部分だけを浮かび上がらせる
パッケージのインストールと読み込みが必要
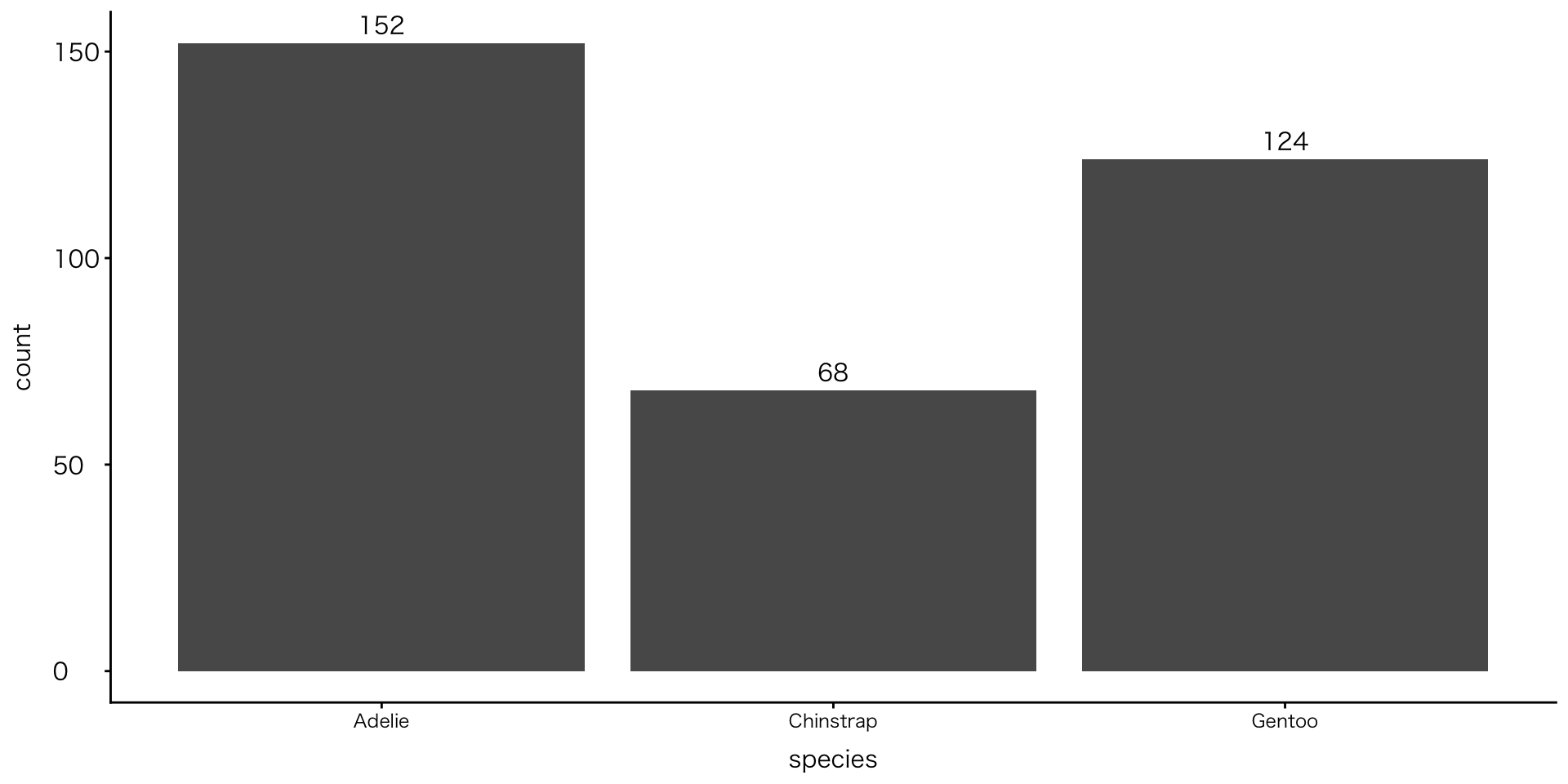
テキストラベル
geom_text()関数
- 棒の上に「数」を表示する:生データ(集計前データ)の場合
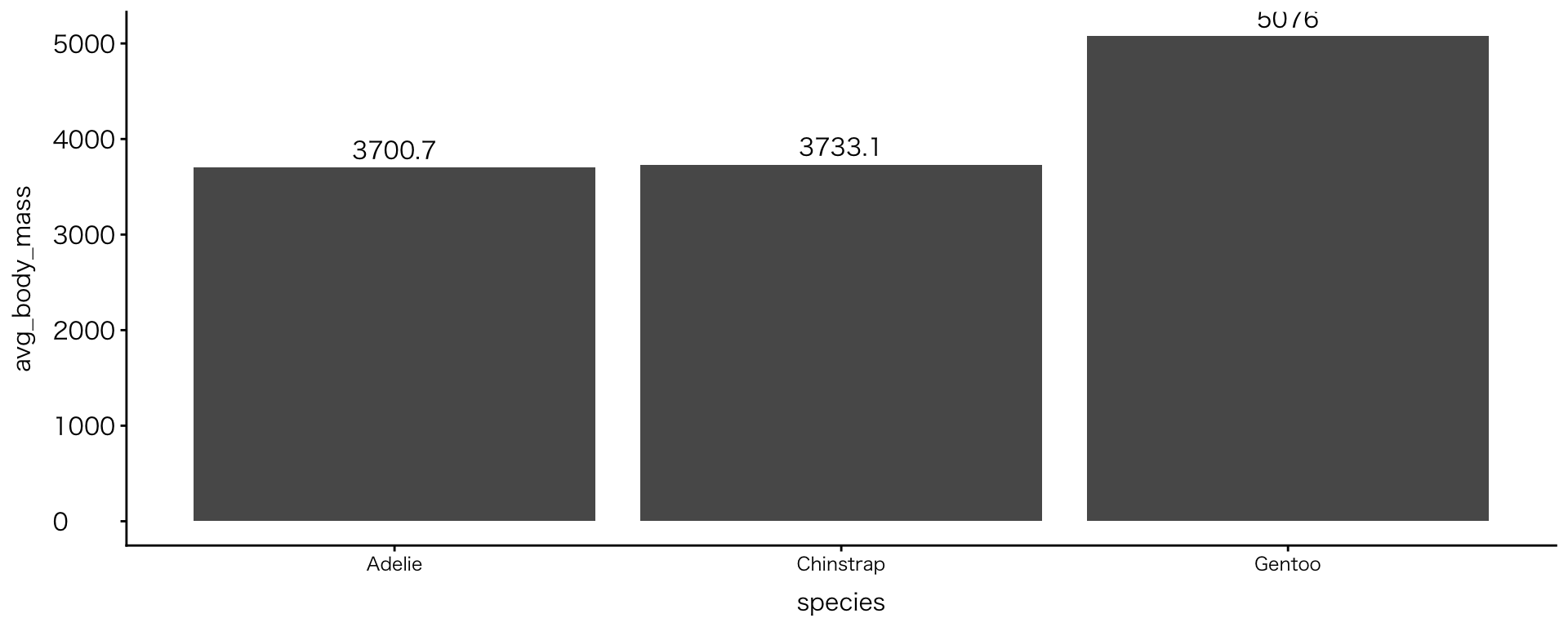
テキストラベル
geom_text()関数
- 棒の上に「数」を表示する:集計後データの場合
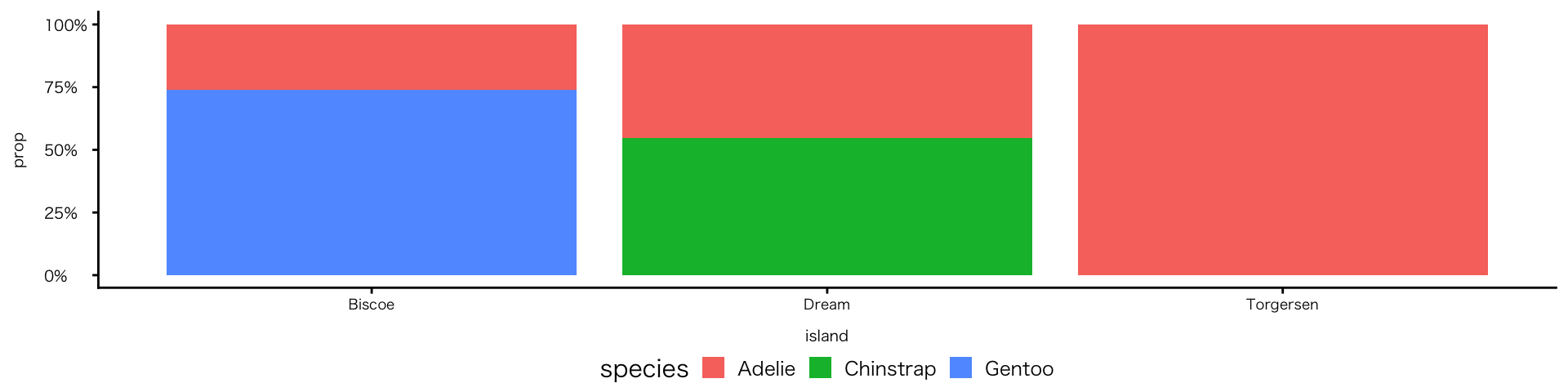
帯グラフ
- 棒の上に「数」を表示する:集計後データの場合②比率と実数
penguins |>
drop_na(species, island) |>
count(island, species) |>
group_by(island) |>
mutate(prop = n / sum(n)) |>
ggplot( aes(x = island, y = prop, fill = species)) +
geom_col(position = "fill") +
geom_text(
aes(
label = str_c( # 複数の要素を文字列として結合する
scales::percent(prop), # 比率(%が付される)
"\n(n=", n, ")" # 実数
)
),
position = position_fill(vjust = 0.5), # 位置
size = 3 # 文字サイズ
) +
scale_y_continuous(labels = scales::label_percent()) + # y軸を比率表示に変更
labs(y = "proportion") # y軸のラベルを変える(%が付されているので、proportionを削って""だけにしてよい=y軸のラベルがなくなる)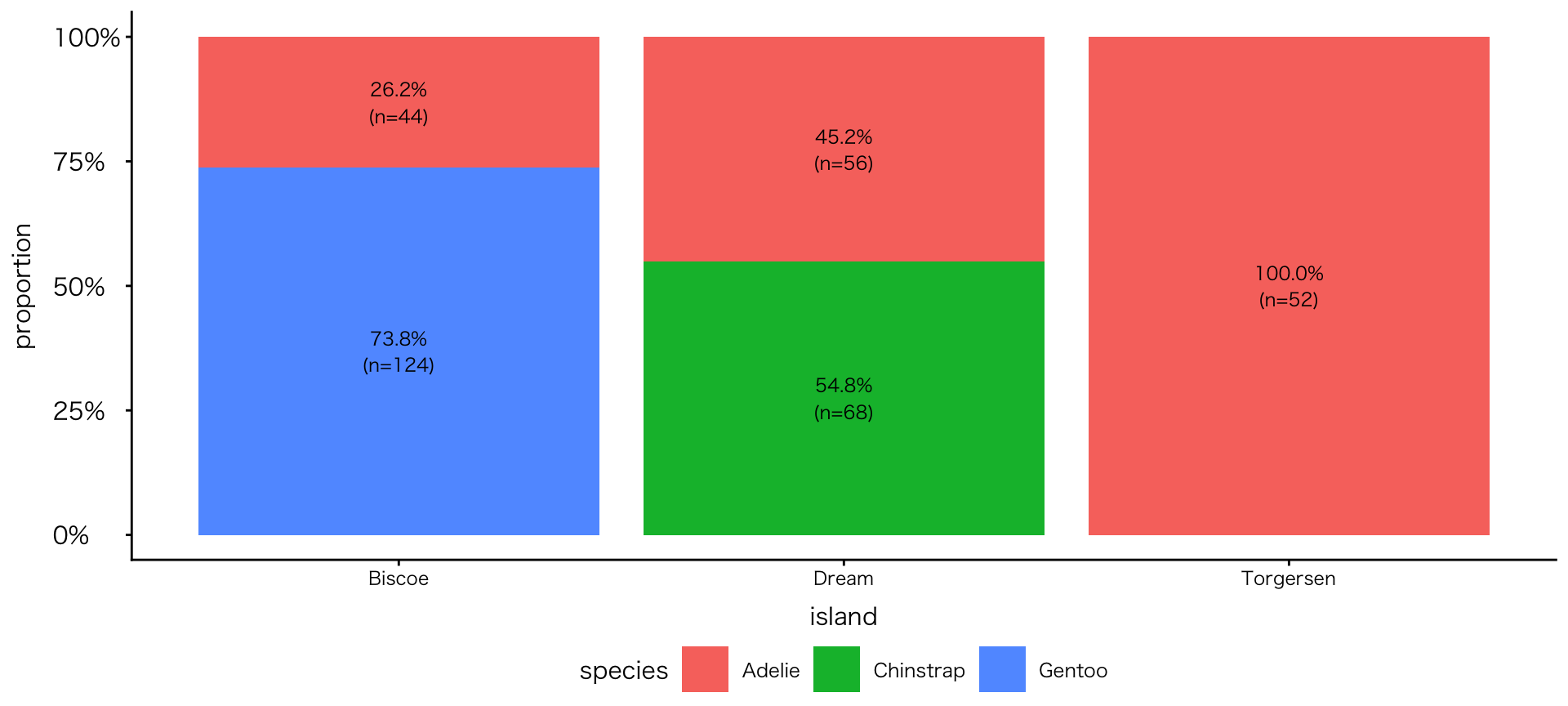
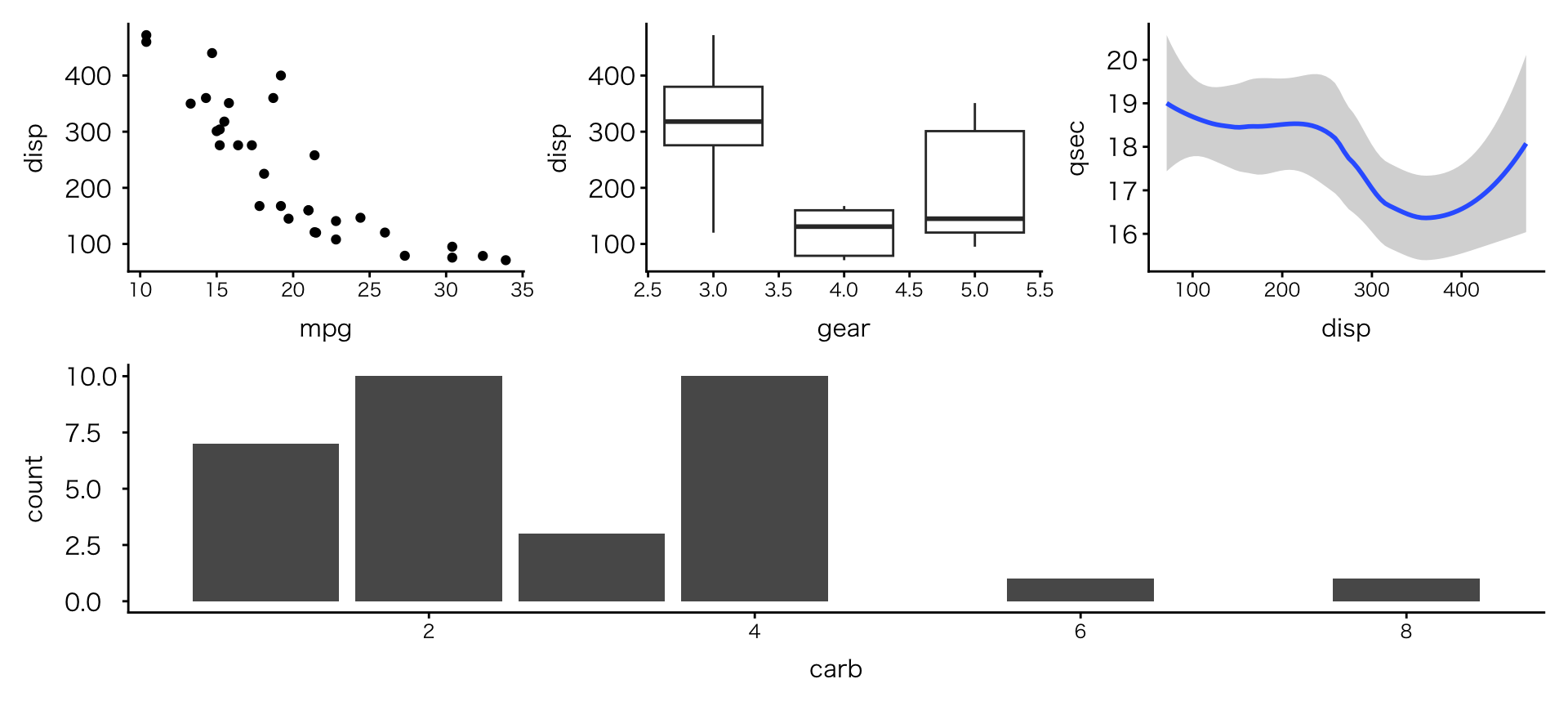
複数の図の配置
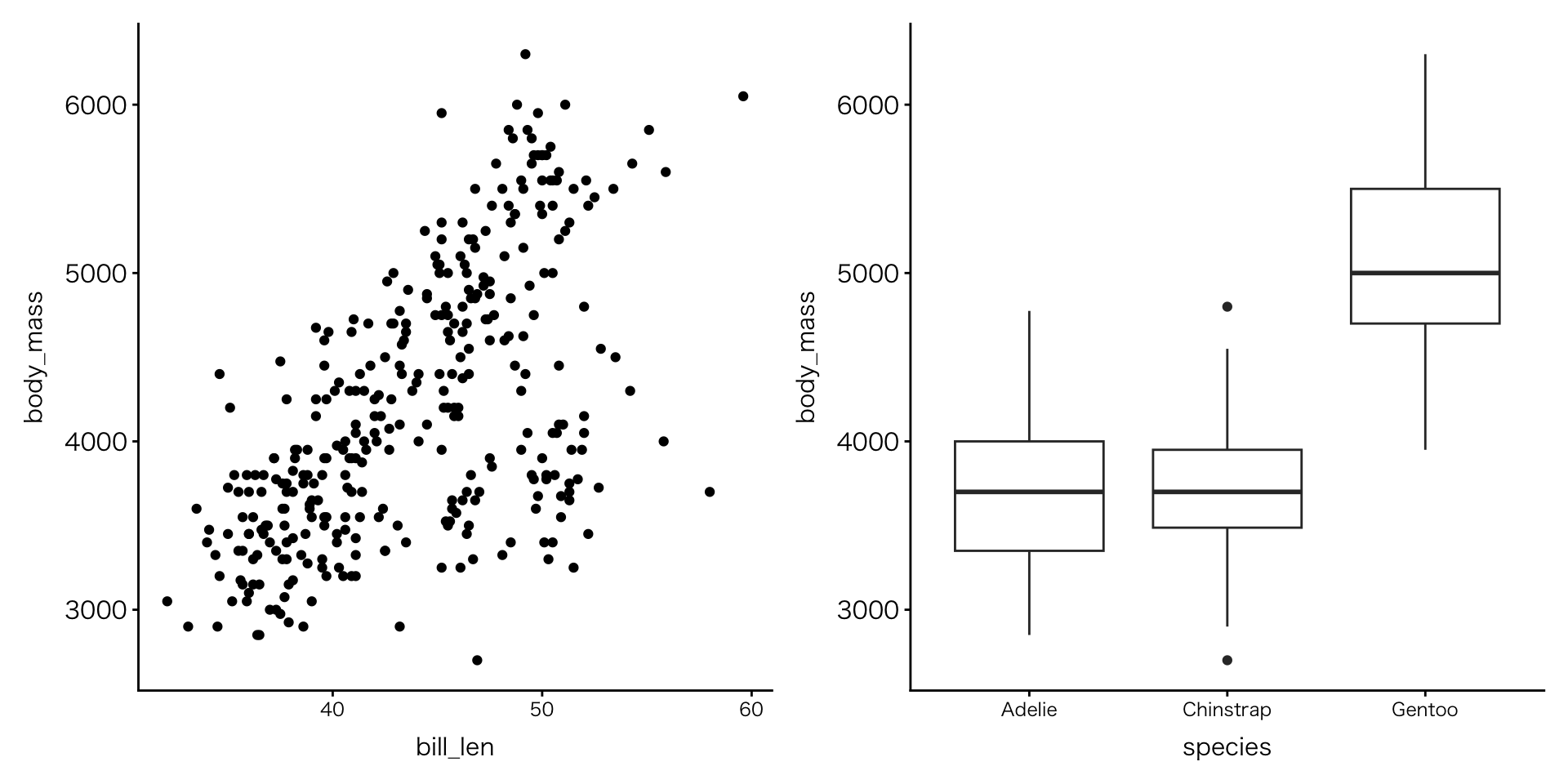
複数の図の配置
- 複雑な配置も可能
- 公式サイトのサンプル